
深度解析:使用 Headless 模式 ChromeDriver 进行无界面浏览器操作
一、问题背景(传统爬虫的痛点) 数据采集是现代网络爬虫技术的核心任务之一。然而,传统爬虫面临多重挑战,主要包括: 反爬机制:许多网站通过检测请求头、IP地址、Cookie等信息识别爬虫,进而限制或拒绝访问。 动态加载内容:一些页面的内容是通过 JavaScript 渲染的,传统的 HTTP 请求无法直接获取这些动态数据。 为了解决这些问题,无界面浏览器(Headless Browser)...

深度解析:使用ChromeDriver和webdriver_manager实现无头浏览器爬虫
问题背景 在现代网络爬虫的实践中,动态网页的内容加载和复杂的反爬虫机制使得数据采集变得愈发困难。传统的静态网页爬取方法已无法满足需求,尤其是在需要模拟用户行为、处理JavaScript渲染的场景下。为此,采用无头浏览器(Headless Browser)技术成为一种有效的解决方案。 无头浏览器能够在后台运行,模拟真实用户的浏览器行为,执行JavaScript脚本,获取动态加载的内容。然而,直接使....

"面试通关秘籍:深度解析浏览器面试必考问题,从重绘回流到事件委托,让你一举拿下前端 Offer!"
浏览器面试常问的问题在求职前端开发岗位时,浏览器相关的知识是面试官必然会考察的内容。以下是一些常见的浏览器面试问题,通过比较和对比的方式,帮助大家更好地理解和准备。问题一:谈谈你对浏览器的渲染机制的理解。在渲染网页时,浏览器大致会经历以下步骤:解析HTML构建DOM树,解析CSS构建CSSOM树&#...
深入解析JS中的visibilitychange事件:监听浏览器标签间切换的利器
一、JS 监听浏览器各个标签间的切换 以前看到过一些网页,在标签切换到其它地址时,网页上的标题上会发生变化,一直不知道这个是怎么做的,最近查了一些资料才发现有一个 visibilitychange 事件就可以搞定,这里将介绍一下页面可见性(Page Visibility)API的简单应用。 简单的说,当用户最小化网页或移动到另一个标签时,API会发送 visibilit...
使用 Python 解析火狐浏览器的 SQLite3 数据库
使用 Python 解析火狐浏览器的 SQLite3 数据库 火狐浏览器(Firefox)使用 SQLite3 数据库来存储用户的各种数据,如书签、历史记录和下载记录等。在这篇文章中,我们将学习如何使用 Python 来解析这些 SQLite3 数据库。 准备工作 在开始之前,请确保您已经安装了以下软件: Pyt...
详细步骤解析:Undetectable指纹浏览器使用IPXProxy代理IP
对于品牌来说,社交媒体已经成为寻找目标受众的丰富资源。在社交媒体平台通过评论和留言进行推广具有很高的转化率,并且推广成本较低。为了获得可观的利润,大家可能需要管理至少几个社交媒体账号,然而在一台电脑上管理多个账号会比较困难。因此使用可靠的工具成为大家的必要选择,其中Undetectable指纹浏览器和IPXProxy代理IP就是两个不错的工具。下面给大家带来Undetectable指纹浏览器配置....
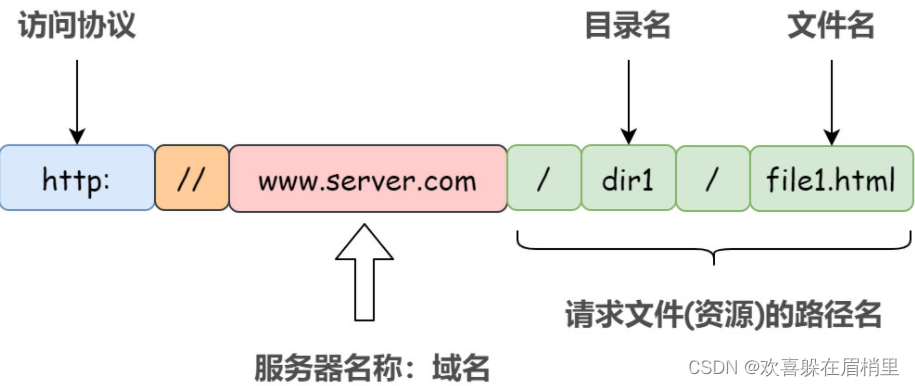
在浏览器上输入一个网址后,发生了什么?/HTTP的工作流程/DNS域名解析过程
这是一个比较常见且经典的问题,我们或者用户通过浏览器访问某个网站,比如用户点击URL为http://www.sxtyu.com/index.html的链接或者访问www.baidu.com,敲回车之后,浏览器的背后发生了什么? 在浏览器中输入url并且获取响应的过程,其实就是浏览器和该url对应的服务器的网络通信过程。就比如在浏览器中输入:www.baidu.com,那么会返回一个百度搜...
HTTP请求流程概览:浏览器构建请求行含方法、URL和版本;检查缓存;解析IP与端口
HTTP请求的基本流程可以分为以下几个步骤: 构建请求行: 浏览器根据用户提供的URL来构建一个HTTP请求。请求行包括三个部分:请求方法(如GET、POST)、请求的资源路径和HTTP版本号。 查找浏览器缓存: 在真正发送请求之前,浏览器会先检查本地缓存中是否有这个请求的响应结果。如果有且没有过期...
浏览器通过构建DOM树来解析HTML代码
浏览器通过构建DOM树来解析HTML代码。 当用户在浏览器中输入网址或点击链接时,浏览器会向服务器发送请求,并接收到HTML代码作为响应。然后,浏览器会将接收到的HTML代码解析成DOM(文档对象模型)树的结构。这个过程涉及以下几个关键步骤: 接收HTML代码:浏览器从服务器接收HTML代码作为对用...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云解析DNS更多浏览器相关
云解析DNS您可能感兴趣
- 云解析DNS互联网
- 云解析DNS定义
- 云解析DNS系统
- 云解析DNS域名
- 云解析DNS http
- 云解析DNS解析
- 云解析DNS网络
- 云解析DNS dhcp
- 云解析DNS ecs
- 云解析DNS dns
- 云解析DNS源码
- 云解析DNS java
- 云解析DNS阿里云
- 云解析DNS服务器
- 云解析DNS应用
- 云解析DNS json
- 云解析DNS备案
- 云解析DNS配置
- 云解析DNS网站
- 云解析DNS数据
- 云解析DNS ip
- 云解析DNS linux
- 云解析DNS访问
- 云解析DNS设置
- 云解析DNS xml
- 云解析DNS android
- 云解析DNS python
- 云解析DNS原理
- 云解析DNS实战
- 云解析DNS文件


