
Haskell爬虫:为电商运营抓取京东优惠券的实战经验
一、需求分析:为什么抓取京东优惠券?京东作为中国领先的电商平台之一,拥有海量的商品和丰富的优惠券资源。这些优惠券信息对于电商运营者来说具有极高的价值。通过分析竞争对手的优惠券策略,运营者可以更好地制定自己的促销方案,优化营销策略,从而在激烈的市场竞争中脱颖而出。具体来说,抓取京东优惠券信息可以帮助运...

如何通过PHP爬虫模拟表单提交,抓取隐藏数据
引言 在网络爬虫技术中,模拟表单提交是一项常见的任务,特别是对于需要动态请求才能获取的隐藏数据。在电商双十一、双十二等促销活动期间,商品信息的实时获取尤为重要,特别是针对不断变化的价格和库存动态。为了满足这种需求,网络爬虫技术中的模拟表单提交显得尤为关键,尤其是在需要动态请求才能获取隐藏数据的场景中。在本文中,我们将详细讲解如何使用PHP实现表单提交并抓取隐藏数据,同时结合代理IP技术,优化爬虫....

为什么PHP爬虫抓取失败?解析cURL常见错误原因
豆瓣电影评分作为中国电影市场的重要参考指标,凭借其广泛覆盖的观众反馈和真实评分,成为电影市场推广和策略优化的核心依据之一。通过精准获取这些评分数据,电影制作方和发行方可以更好地理解观众需求,优化宣传策略,并作出科学决策。 在数据驱动的时代,网络爬虫技术为高效采集豆瓣电影评分等关键数据提供了强大的支持。利用爬虫技术,我们能够迅速收集海量的电影评分、评论内容及趋势信息,为电影市场推广提供详实的量化依....

除了网页标题,还能用爬虫抓取哪些信息?
使用爬虫可以抓取的信息非常广泛,几乎涵盖了网页上所有可见和不可见的数据。以下是一些常见的信息类型,爬虫可以用来抓取: 一、文本信息: 文章内容产品描述用户评论新闻报道价格信息产品规格二、图片和视频: 图片链接和文件视频链接和文件图片的元数据(如尺寸、格式)三、链接: 内部链接ÿ...
python爬虫抓取91处理网
本人是个爬虫小萌新,看了网上教程学着做爬虫爬取91处理网www.91chuli.com,如果有什么问题请大佬们反馈,谢谢。 以下是用lxml来爬取的。 from lxml import etree def getHTMLText(url): kv = { 'cookie': 'ssids=158...
Selenium爬虫技术:如何模拟鼠标悬停抓取动态内容
介绍 在当今数据驱动的世界中,抓取动态网页内容变得越来越重要,尤其是像抖音这样的社交平台,动态加载的评论等内容需要通过特定的方式来获取。传统的静态爬虫方法难以处理这些由JavaScript生成的动态内容,Selenium爬虫技术则是一种能够有效解决这一问题的工具。本文将以采集抖音评论为示例,介绍如何使用Selenium模拟鼠标...

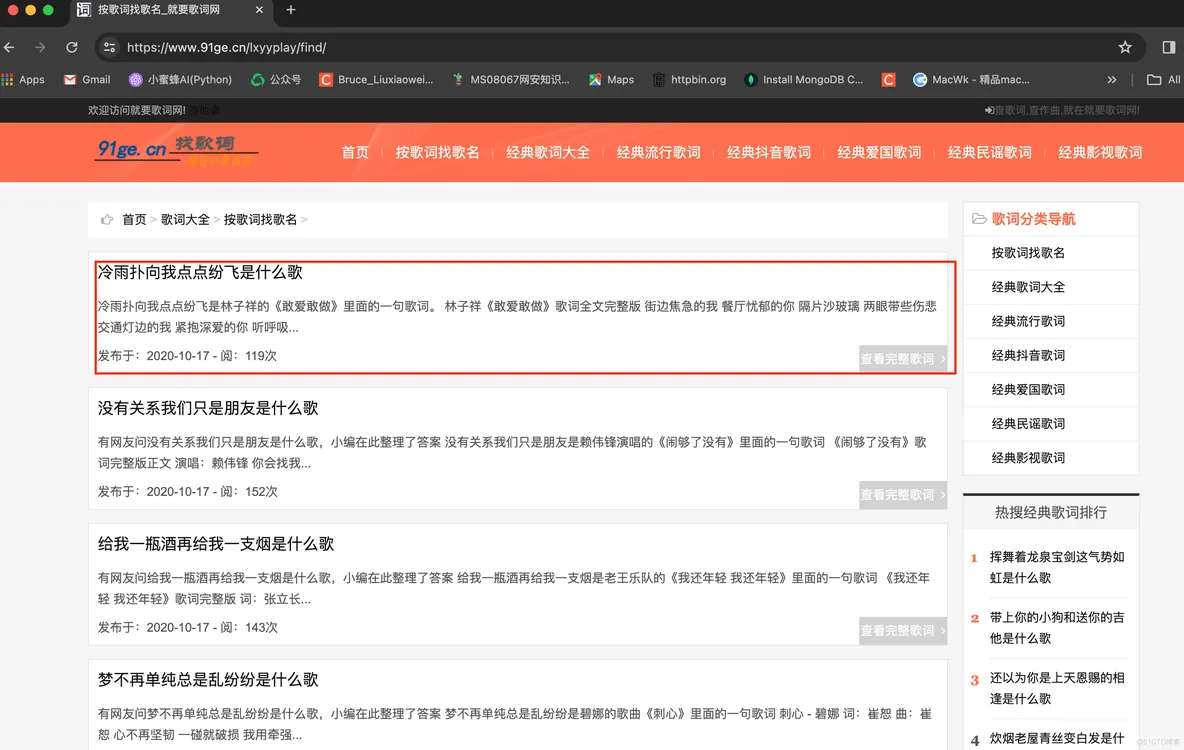
爬虫案例—抓取找歌词网站的按歌词找歌名数据
爬虫案例—抓取找歌词网站的按歌词找歌名数据找个词网址: https://www.91ge.cn/lxyyplay/find/ 目标:抓取页面里的所有要查的歌词及歌名等信息,并存为txt文件 一共46页数据 网站截图如下: 抓取完整歌词数据,如下图: 源码如下: import asyncio impo...
爬虫案例—根据四大名著书名抓取并存储为文本文件
爬虫案例—根据四大名著书名抓取并存储为文本文件诗词名句网: https://www.shicimingju.com 目标:输入四大名著的书名,抓取名著的全部内容,包括书名,作者,年代及各章节内容 诗词名句网主页如下图: 今天的案例是抓取古籍板块下的四大名著,如下图: 案...

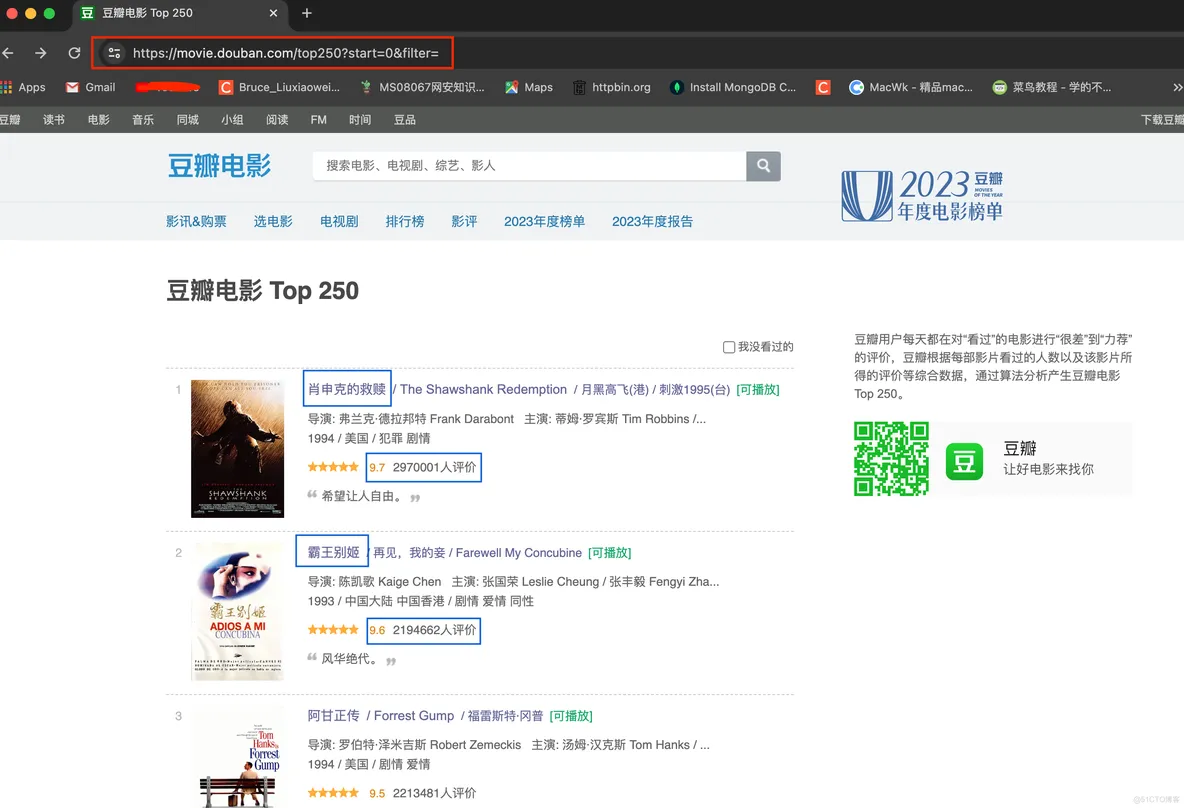
爬虫案例—抓取豆瓣电影的电影名称、评分、简介、评价人数
爬虫案例—抓取豆瓣电影的电影名称、评分、简介、评价人数豆瓣电影网址:https://movie.douban.com/top250 主页截图和要抓取的内容如下图: 分析:第一页的网址:https://movie.douban.com/top250?start=0&filter= 第二页的网址:http...
构建您的第一个Python网络爬虫:抓取、解析与存储数据
在当今的信息时代,数据无处不在,而网络爬虫正是提取这些数据的有力工具。Python因其简洁的语法和强大的库支持成为编写网络爬虫的首选语言。本教程将带领初学者了解并实践构建一个基础的网络爬虫项目。 网络爬虫的核心功能是从网站上自动提取信息。这通常涉及三个步骤:请求网页、解析响应内容、存储有用数据。我们将通过一个简单的例子来演示这一过程。 首先,...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
爬虫更多抓取相关
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注