
机器学习:李航-统计学习方法-代码实现
《统计学习方法》的代码实现分享《统计学习方法》这本书,附件里并没有代码实现,于是许多研究者复现了里面算法的代码,并放在github里分享,这里介绍几个比较热门的《统计学习方法》代码实现的项目: 1)GitHub - fengdu78/lihang-code: 《统计学习方法》的代码实现 (标星:13.6k+)这个仓库由黄海广博士整理,第一版的监督学习方法已经整理完毕(更新完十二章),仓库的主要内....

机器学习:李航-统计学习方法笔记(一)监督学习概论
1.1统计学习统计学习是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科。也可以说统计学习就是计算机系统通过运用数据及统计方提高系统性能的机器学习。故统计学习也称为统计机器学习。 统计学习的目的在于从假设空间中选取最优模型。统计学习的对象是数据,数据分为由连续变量和离散变量表示的类型,其中同类数据是指具有某种共同性质的数据。在统计学习的过程中,以变量或者是变量组表示数据....

机器学习测试笔记(12)——线性回归方法(下)
3.逻辑回归大家都知道符号函数: f(x)=0 (x=0) =-1 (x<0) =1 (x>1)下面这个函数是符号函数的一个变种:g(x) =0.5 (x=0) &...
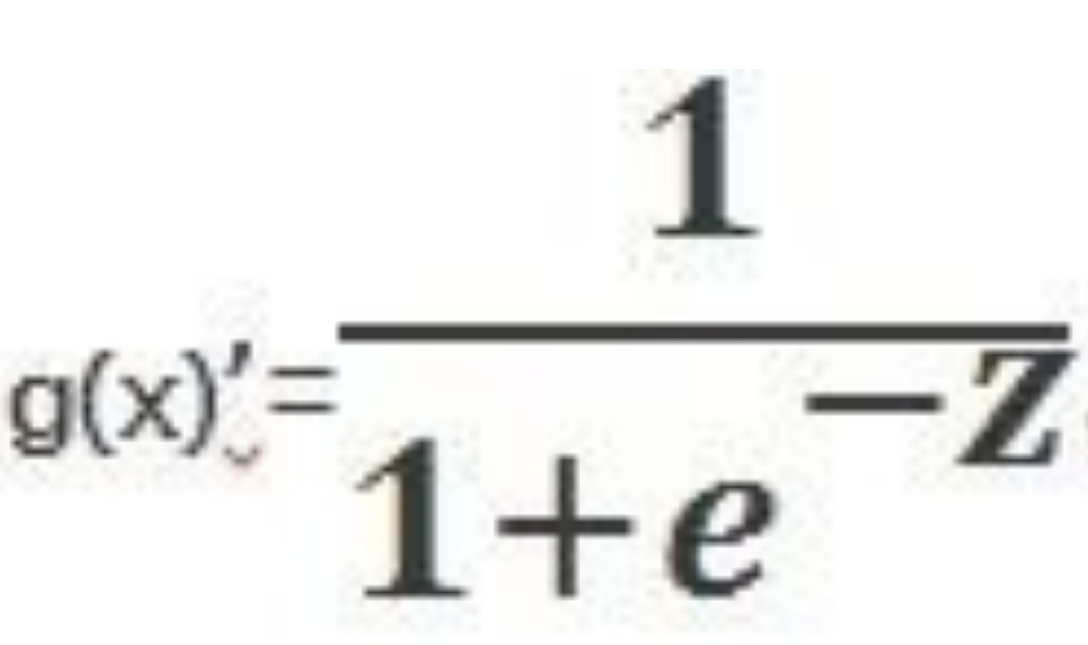
机器学习测试笔记(11)——线性回归方法(上)
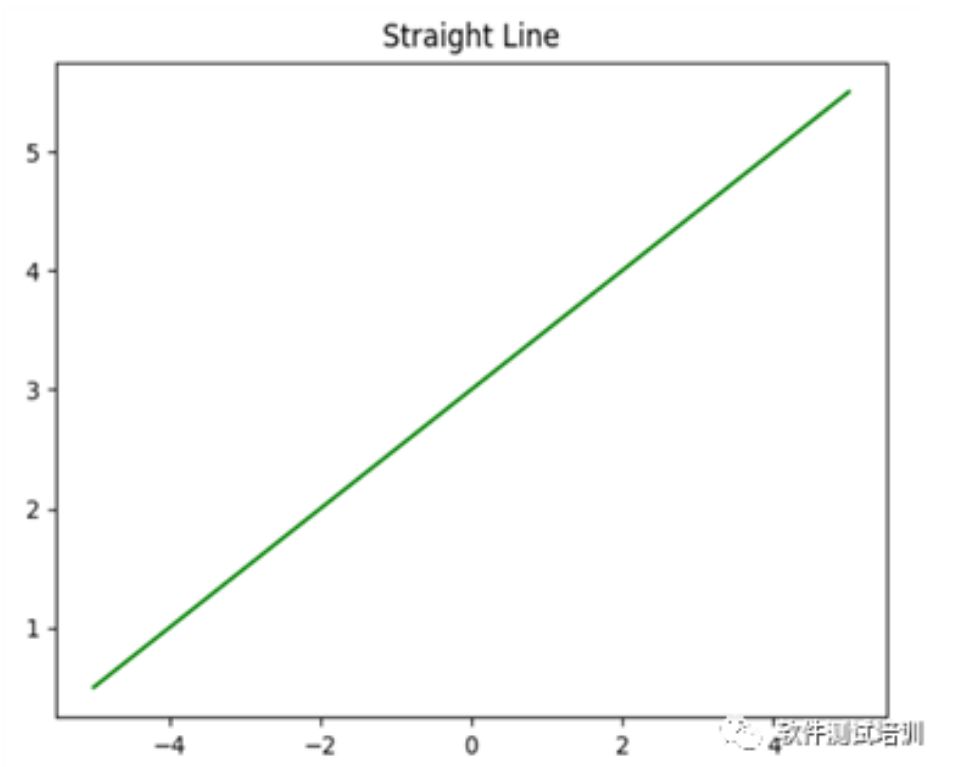
1.基本概念直线是最基本的几何图形,一般的直线可以表达为:y = kx+b,这里的k我们叫做斜率,b叫做截距(x=0的时候,y的值。即直线与y轴的交叉点)。线性回归方法即找出一条直线,使得各个点到这条直线上的误差最小。现在让我们通过Python语言来画一条直线:y = 0.5 * x + 3(这里斜率为0.5, 截距为3)。# 导入NumPy库 import numpy as np # 导入画.....
浅析机器学习中的降维方法
在我们用机器学习去训练数据集的时候,可能会遇到上千甚至上万个特征,随着数据量的增大,所分析出结果的准确度虽然会提高很多,但同时处理起来也会变得十分棘手,此时我们不得不想出一种方法去减少特征将高维的数据转化为低维的数据(降维)。什么是降维?简单的说降维就是把一个n维的数据转化为一个k维的数据(k<<n)为什么要降维?随着数据维度不断降低,数据存储所需的空间也会随之减少。低维数据有助于减....
【机器学习项目实战10例】(七):基于逻辑回归方法完成垃圾邮件过滤任务
一、基于逻辑回归方法完成垃圾邮件过滤任务1、✌ 任务描述我们日常学习以及工作中会收到非常多的邮件,除了与学习工作相关的邮件,还会收到许多垃圾邮件,包括广告邮件、欺诈邮件等等。本任务通过邮件中包含的文本内容来判断该邮件是正常邮件(ham)还是垃圾邮件(spam),来实现自动化垃圾邮件过滤,是一种典型的文本分类任务。2、✌ 数据集该数据集包含5574条邮件,所有邮件都被标记为正常邮件(ham)或者垃....

【机器学习】(19)使用sklearn实现估计器的调参方法
使用sklearn实现估计器的调参方法有些刚刚接触机器学习的人总是弄混超参数和参数的意思,在深度学习中超参数对应着我们的网络学习到的参数,就是每一层的权重w,而参数就是网络的层数或者epoch这些。而在机器学习中也是如此,举个例子,对于随机森林来说,我们调的树的棵树就是超参数,而参数就是我们模型内部有关书的形状的一些参数。可以这样说,超参数的选择决定着模型参数的值,我们调整超参数的目的就是使模型....
Kaggle M5 Forecasting:传统预测方法与机器学习预测方法对比(三)
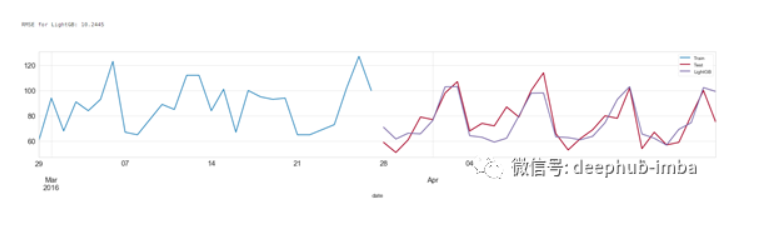
机器学习使用机器学习方法,首先需要特征数据以及指标数据。在本文中,基于时间序列数据构造特征数据如下:特征数据1:滞后数据。选择 7 天前的 demand 数据作为特征数据。特征数据2:移动平均数据。选择 7 天前至 14 天之前的 demand 移动平均值数据作为特征数据。特征数据3:月销售均值特征数据4:每月销售最大值特征数据5:每月销售最小值特征数据6:每月销售最大值与最小值的差值特征数据7....
Kaggle M5 Forecasting:传统预测方法与机器学习预测方法对比(二)
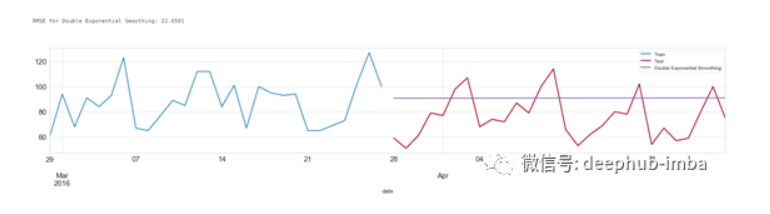
双指数平滑方法单指数平滑方法只使用了一个平滑系数 ,而双指数平滑方法则引入了第二个平滑系数 ,以反映数据的趋势。使用双指数平滑方法,我们需要定义 seasonal_periods。具体代码如下: t0 = time.time() model_name='Double Exponential Smoothing' #train doubleExpSmooth_model = Exponential....
Kaggle M5 Forecasting:传统预测方法与机器学习预测方法对比(一)
本文使用的数据集来自 kaggle:M5 Forecasting — Accuracy。该数据集包含有 California、Texas、Wisconsin 三个州的产品类别、部门、仓储信息等。基于这些数据,需要预测接下来 28 天的每日销售量。本文代码 github见最后部分涉及到的方法有:单指数平滑法双指数平滑法三指数平滑法ARIMASARIMASARIMAXLight Gradient B....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
机器学习平台 PAI更多方法相关
机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI scikit-learn
- 机器学习平台 PAI python
- 机器学习平台 PAI代码
- 机器学习平台 PAI论文
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI实战
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI模型
- 机器学习平台 PAI构建
- 机器学习平台 PAIpai
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI数据
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI分类
- 机器学习平台 PAI平台
- 机器学习平台 PAI笔记
- 机器学习平台 PAI学习
- 机器学习平台 PAI特征
- 机器学习平台 PAI实践
- 机器学习平台 PAI决策
- 机器学习平台 PAIai
- 机器学习平台 PAI部署
- 机器学习平台 PAI网络
- 机器学习平台 PAI线性回归