
如何安装ProximaCE包
在使用向量计算功能之前,您需要安装Proxima CE包,本文为您介绍Proxima CE的环境准备、安装包获取方式、上传及输入数据准备等过程。
【大数据开发运维解决方案】hadoop+kylin安装及官方cube/steam cube案例文档
对于hadoop+kylin的安装过程在上一篇文章已经详细的写了,请读者先看完上一篇文章再看本本篇文章,本文主要大致介绍kylin官官方提供的常规批量cube创建和kafka+kylin流式构建cube(steam cube)的操作过程,具体详细过程请看官方文档。1、常规cube创建案例[root@hadoop ~]# cd /hadoop/kylin/bin/ [root@hadoop bin....

【大数据开发运维解决方案】Hadoop2.7.6+Spark单机伪分布式安装
一、安装spark依赖的Scala1.1 下载和解压缩Scala下载地址:点此下载或则直接去官网挑选下载:官网连接在Linux服务器的opt目录下新建一个名为scala的文件夹,并将下载的压缩包上载上去:[root@hadoop opt]# cd /usr/ [root@hadoop usr]# mkdir scala [root@hadoop usr]# cd scala/ [root@had....

【大数据开发运维解决方案】Hadoop2.7.6+Spark2.4.4+Scala2.11.12+Hudi0.5.2单机伪分布式安装
Hadoop2.7.6+Spark2.4.4+Scala2.11.12+Hudi0.5.2单机伪分布式安装注意1、本文档使用的基础hadoop环境是基于本人写的另一篇文章的基础上新增的spark和hudi的安装部署文档,基础环境部署文档2、整篇文章配置相对简单,走了一些坑,没有写在文档里,为了像我一样的小白看我的文档,按着错误的路径走了,文章整体写的较为详细,按照文章整体过程来做应该不会出错,如....

【大数据开发运维解决方案】sqoop1.4.7的安装及使用(hadoop2.7环境)
一、sqoop简介Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。二、环境配置三、安装Sqoop1. 下载,解压到指定目录下载连接:点此下载创....

【大数据开发运维解决方案】Linux Solr5.1安装及导入Oracle数据库表数据
一、Solr5.1安装1、官方下载链接点此下载2、下载上传压缩包到Linux服务器[root@hadoop ~]# mkdir -p /hadoop/solr通过sftp上传压缩包至此目录:[root@hadoop solr]# ls solr-5.1.0.tgz [root@hadoop solr]# tar -zxvf solr-5.1.0.tgz ...... [root@hadoop...

【大数据开发运维解决方案】linux5 安装 oracle 11g(11.2.0.4)实验
安装环境(可以查看附件的环境安装过程来安装和我这个一模一样的环境):oracle linux 5 64位 ,oracle11.2.0.4 64位 ip 192.168.0.5 hostname jtxy安装目录: /u01系统要求:以下是安装Oracle数据库的内存要求11所示g版本2(11.2):grep MemTotal /proc/meminfo&nbs...

大数据开发之Hadoop 伪分布式安装(4)【完结】
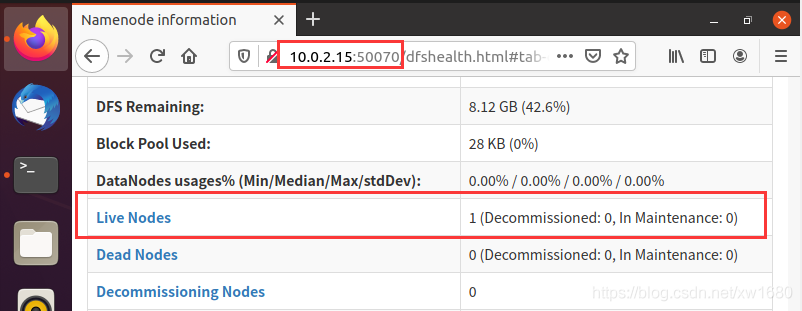
大数据开发之Hadoop 伪分布式安装(4)查看 Hadoop 的基本信息查看 HDFS Web 界面HDFS Web 界面可以检查当前 HDFS 与 DataNode 的运行情况,打开步骤如下。打开浏览器 Firefox,在浏览器的地址栏中输入:10.0.2.15:50070,向下滑动页面,可以看到活动节点,如下图所示:说明:10.0.2.15 为笔者虚拟机中的 IP 地址,读者应根据实际情况....
大数据开发之Hadoop 伪分布式安装(3)
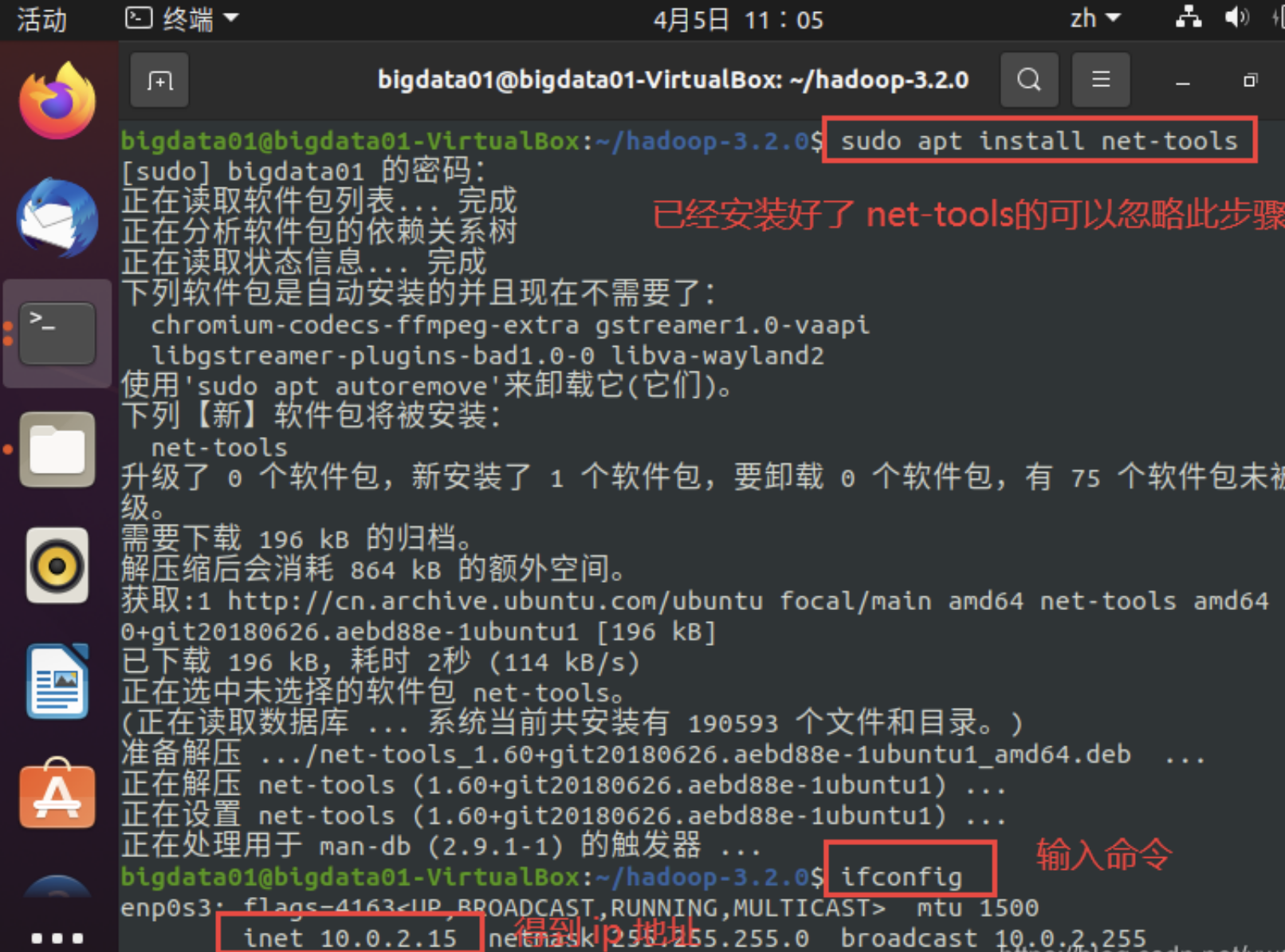
大数据开发之Hadoop 伪分布式安装(3)我们接着上一节,来配置Hadoop.Hadoop 环境配置1、配置 IP 和主机名下面分别通过命令查看本机的 IP 地址和主机名,并将 IP 地址和主机名写进 /etc/hosts 配置文件中,步骤如下:(1) 查看本机的 IP 地址,命令如下:sudo apt install net-tools ifconfig或者直接使用ip addr执行结果如下....
大数据开发之Hadoop 伪分布式安装(2)
大数据开发之Hadoop 伪分布式安装(2)Hadoop 的下载与安装在介绍 Hadoop 的安装之前,先介绍一下 Hadoop 对各个节点的角色定义。Hadoop 可以分别从三个角度将主机划分为两种角色。第一,最基本的划分为 Master 和 Slave,即主人与奴隶;第二,从 HDFS 的角度,将主机划分为 NameNode 和 DataNode(在分布式文件系统中,目录的管理很重要,管理目....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute更多安装相关
- 大数据计算云原生大数据计算服务 MaxCompute安装
- 大数据计算云原生大数据计算服务 MaxCompute安装方包
- 云原生大数据计算服务 MaxCompute安装方包
- 数据计算云原生大数据计算服务 MaxCompute安装
- 云原生大数据计算服务 MaxCompute安装导入
- 云原生大数据计算服务 MaxCompute superset安装
- 云原生大数据计算服务 MaxCompute包安装
- 云原生大数据计算服务 MaxCompute安装mma
- 安装云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute集群环境安装
- 云原生大数据计算服务 MaxCompute hbase安装
- 云原生大数据计算服务 MaxCompute dockerfile安装
- 云原生大数据计算服务 MaxCompute sqoop安装
- 云原生大数据计算服务 MaxCompute安装步骤
- 云原生大数据计算服务 MaxCompute安装hbase
- 云原生大数据计算服务 MaxCompute伪分布安装
- 云原生大数据计算服务 MaxCompute flume安装
- 云原生大数据计算服务 MaxCompute安装zookeeper
- 安装云原生大数据计算服务 MaxCompute框架
- 云原生大数据计算服务 MaxCompute安装编程
- 云原生大数据计算服务 MaxCompute组件安装
- 云原生大数据计算服务 MaxCompute安装kafka
- 云原生大数据计算服务 MaxCompute数据采集安装
- 云原生大数据计算服务 MaxCompute伪分布式安装
- 阿里云ecs安装云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute安装flume
- 云原生大数据计算服务 MaxCompute vmware安装
- 云原生大数据计算服务 MaxCompute kafka安装
- ubuntu安装云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute安装脚本
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute oss
- 云原生大数据计算服务 MaxCompute分布式
- 云原生大数据计算服务 MaxCompute数据处理
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute天作之合
- 云原生大数据计算服务 MaxCompute区块链
- 云原生大数据计算服务 MaxCompute心跳
- 云原生大数据计算服务 MaxCompute崛起
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute平台
大数据计算 MaxCompute
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
+关注