
分词提取免费API使用指南:轻松实现文本关键词提取
一、接口简介 免费的中文分词关键词提取API,通过智能算法快速拆分文本关键词。适用于舆情分析、内容标签生成、搜索引擎优化等场景。 二、核心参数说明 ...
如何实现从钉钉考勤api中根据用户id和日期拿到的考勤数据在宜搭的文本控件中展示?
钉钉考勤api根据用户ID和日期已经拿到数据了,但是不知道如何在宜搭的文本控件中展示,还请给出截图+示例代码
通用文本排序模型API使用详情
模型简介文本排序模型 (Text ReRank Model),通常用于语义检索场景,模型可以简单、有效地提升文本检索的效果。给定查询 (Query) 和一系列候选文本 (Documents),会根据与查询的语义相关性从高到低对候选文本进行排序。 gte-rerank是通义实验室研发的多语言文本统一排...
自学记录鸿蒙API 13:实现智能文本识别Core Vision Text Recognition
在完成语音助手项目后,我想试试其他的AI的API 13,于是我瞄上了——智能文本识别。通过研究HarmonyOS Next最新版本API 13中的Core Vision Text Recognition API,我深刻感受到了鸿蒙生态在计算机视觉领域的强大支持。该API能够快速将图像中的文本内容提取为结构化信息,官方给了足够的支持,也为开发者提供了丰富的应用场景。 ...

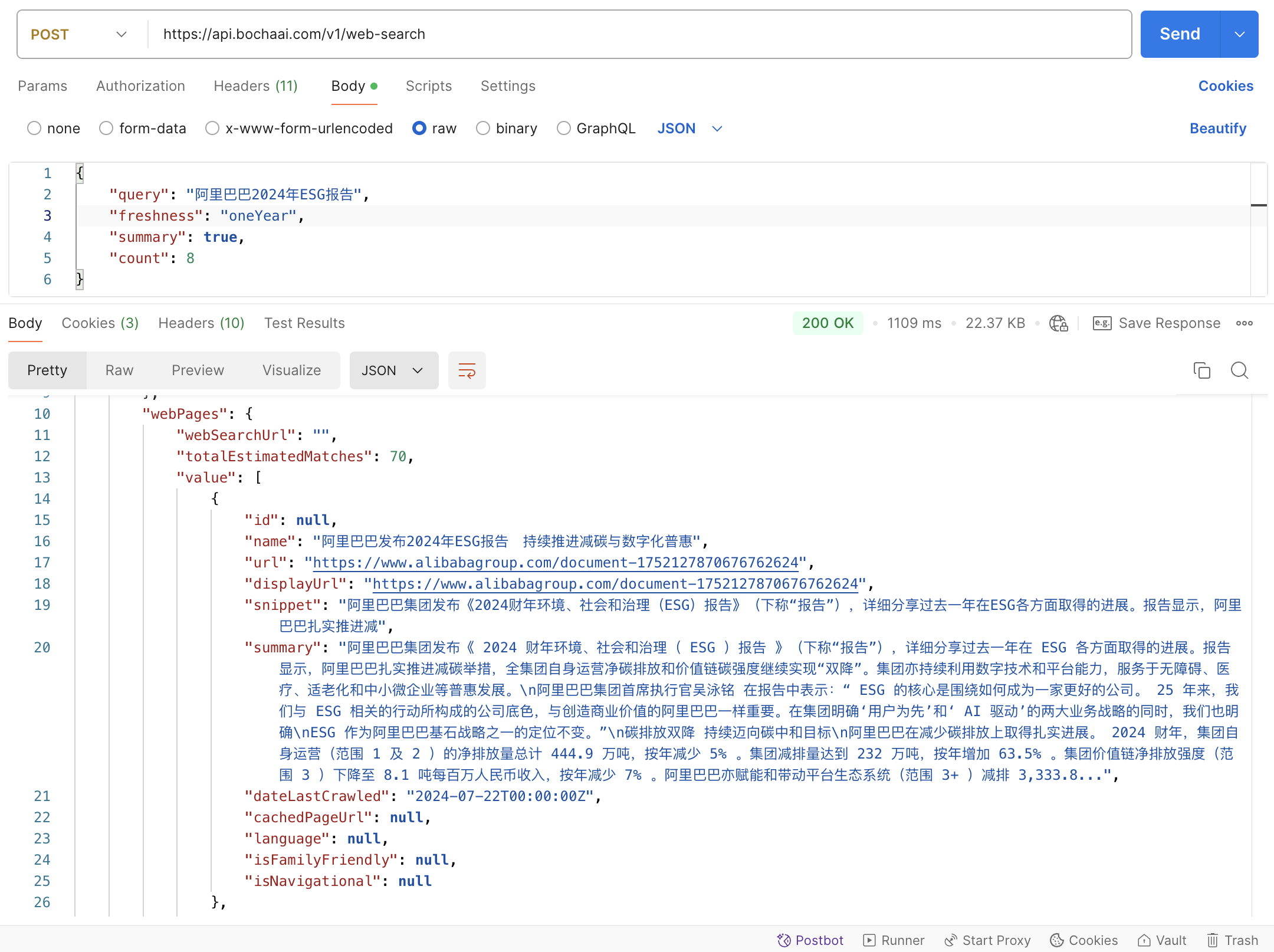
用于企业AI搜索的Bocha Web Search API,给LLM提供联网搜索能力和长文本上下文
Bocha Web Search API是由博查提供的企业级互联网网页搜索API接口,允许开发者通过编程访问博查搜索引擎的搜索结果和相关信息,实现在应用程序或网站中集成搜索功能。该API支持近亿级网页内容搜索,适用于各类AI应用、RAG应用和AI Agent智能体的开发,解决数据安全、价格高昂和内容合规等问题。通过注册博查开发者账户、获取A...
`transformers`库是Hugging Face提供的一个开源库,它包含了大量的预训练模型和方便的API,用于自然语言处理(NLP)任务。在文本生成任务中,`transformers`库提供了许多预训练的生成模型,如GPT系列、T5、BART等。这些模型可以通过`pipeline()`函数方便地加载和使用,而`generate()`函数则是用于生成文本的核心函数。
一、引言 transformers库是Hugging Face提供的一个开源库,它包含了大量的预训练模型和方便的API,用于自然语言处理(NLP)任务。在文本生成任务中,transformers库提供了许多预训练的生成模型,如GPT系列、T5、BART等。这些模型可以通过pipeline()函数方便地加载和使用&...
语音服务调用api报错isv.TEMPLATE_ILLEGAL文本转语音模板不合法
语音服务调用api报错isv.TEMPLATE_ILLEGAL文本转语音模板不合法
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

