
创建PyODPS 2节点任务
DataWorks提供了PyODPS 2节点类型,允许您使用PyODPS语法在DataWorks平台上开发PyODPS任务。PyODPS集成了MaxCompute的Python SDK,使您能够在PyODPS 2节点上直接编写和编辑Python代码来操作MaxCompute。
优雅下线表和任务
对于数据治理过程中的无效任务或表,数据资产治理为您提供完整的下线方案,包含下线风险评估、下线通知推送、下线过程管理等全流程功能,为您解决人工识别下线风险、任务存在正常调度的下游任务时不能下线、因无法预知风险而不敢轻易下线等问题,同时提供批量下线功能,方便统一管理和执行,为您提升下线效率。
大数据增加分区减少单个任务的负担
在处理大数据时,增加分区(Partitioning)是一种常见的策略,用于优化数据处理流程,减少单个任务的负担。分区是指将大型数据集分成较小、更易于管理的部分,每个部分都可以独立地进行处理。这种做法有助于提高数据处理效率,尤其是在分布式计算环境中。以下是几种利用分区来减轻单个任务负担的方法ÿ...
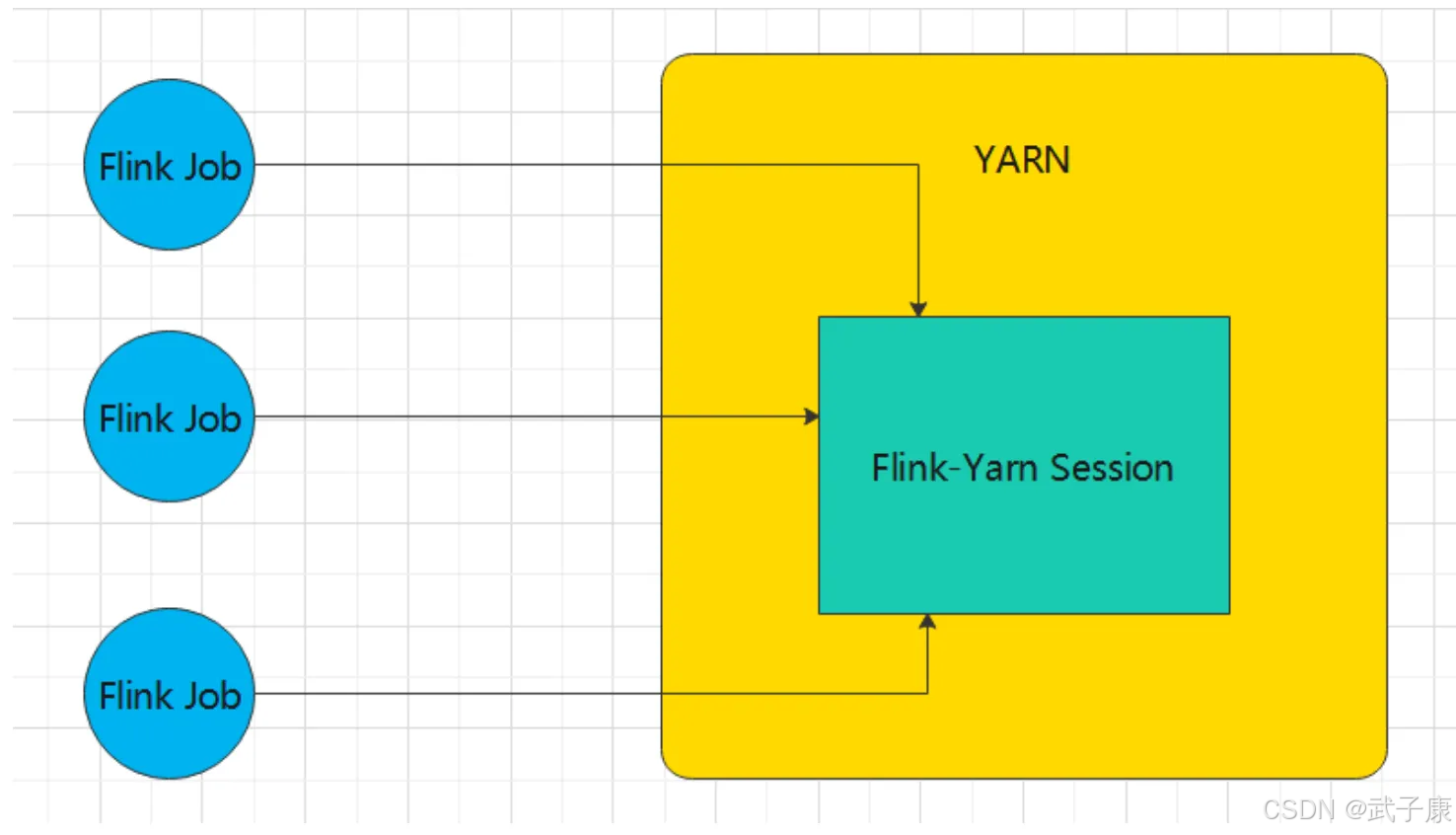
大数据-111 Flink 安装部署 YARN部署模式 FlinkYARN模式申请资源、提交任务
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...
如何对付一个耗时6h+的ODPS任务:慢节点优化实践
一、背景 二、快速止血 2.1、耗时卡点定位 先来看看这个让人头疼的慢节点,长什么样子?让我看看你是何方神圣。 ...

MaxCompute Online Job失败后 任务日志如何查看
MaxCompute Online Job失败后转换为Offline Job 任务日也都是Offline Job的 那 Online Job失败日志如何查看
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute更多任务相关
- 云原生大数据计算服务 MaxCompute配置任务
- 云原生大数据计算服务 MaxCompute产品同步任务
- 云原生大数据计算服务 MaxCompute任务资源
- 云原生大数据计算服务 MaxCompute资源任务
- 云原生大数据计算服务 MaxCompute flink任务
- 云原生大数据计算服务 MaxCompute任务优化
- 云原生大数据计算服务 MaxCompute任务日志
- 数据计算云原生大数据计算服务 MaxCompute抽取任务
- 云原生大数据计算服务 MaxCompute mc任务
- 云原生大数据计算服务 MaxCompute周期任务
- 云原生大数据计算服务 MaxCompute任务运行
- 云原生大数据计算服务 MaxCompute sql任务
- 云原生大数据计算服务 MaxCompute产品任务
- maxcompute云原生大数据计算服务 MaxCompute任务
- 大数据云原生大数据计算服务 MaxCompute任务运行
- 云原生大数据计算服务 MaxCompute套件任务
- 数据计算云原生大数据计算服务 MaxCompute任务运行
- 云原生大数据计算服务 MaxCompute数据集成任务
- 云原生大数据计算服务 MaxCompute任务配置
- 云原生大数据计算服务 MaxCompute实时同步任务
- 云原生大数据计算服务 MaxCompute调度任务
- 数据计算云原生大数据计算服务 MaxCompute sql任务
- 云原生大数据计算服务 MaxCompute任务参数
- 云原生大数据计算服务 MaxCompute节点任务
- 云原生大数据计算服务 MaxCompute任务节点
- 大数据云原生大数据计算服务 MaxCompute数据集成任务
- 云原生大数据计算服务 MaxCompute任务字段
- 云原生大数据计算服务 MaxCompute spark任务报错
- 云原生大数据计算服务 MaxCompute任务文件
- 数据计算云原生大数据计算服务 MaxCompute调度任务
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute潜能
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute oss
- 云原生大数据计算服务 MaxCompute分布式
- 云原生大数据计算服务 MaxCompute数据处理
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute天作之合
- 云原生大数据计算服务 MaxCompute区块链
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目
- 云原生大数据计算服务 MaxCompute分区
大数据计算 MaxCompute
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
+关注