
实战 | Apache Hudi回调功能简介及使用示例
1. 功能简介 从0.6.0版本开始,Hudi开始支持 commit 回调功能,即每当Hudi成功提交一次 commit, 其内部的回调服务就会向外部系统发出一条回调信息,用户可以根据该回调信息查询Hudi表的增量数据,并根据具体需求进行相应的业务处理。 1.1 支持的回调方式 当前 HoodieDeltaStreamer 可通过 HTTP(默认) 和 Kafka 两种方...
大数据技术变革正当时,Apache Hudi了解下?
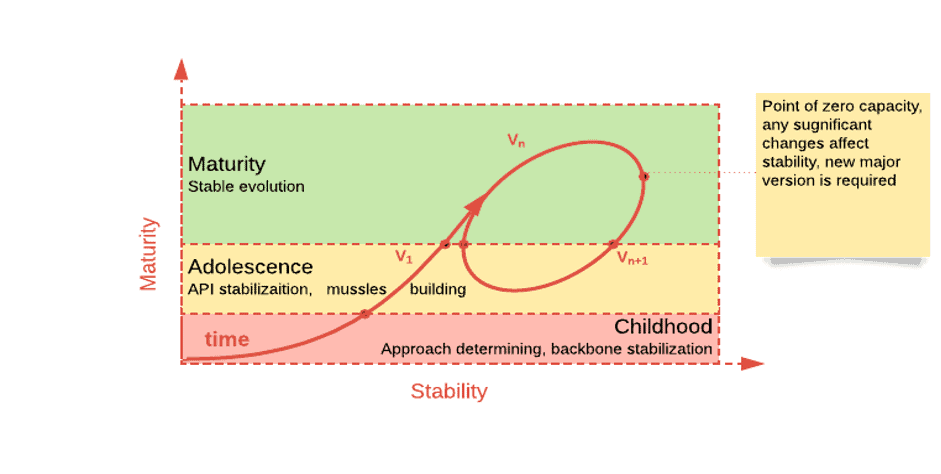
之前认为只有大公司才能负担得起大数据驱动的解决方案,该方案适用于海量数据,但价格昂贵。随着大数据技术的不断发展,现在已经发生了很大变化。 1. 大数据技术的成熟度 第一次革命与成熟度和质量有关。十年前对于大数据技术开发人员需要做出一定努力才能使一些大数据技术正常工作或与其他大基础组件协同工作。 ...
查询时间降低60%!Apache Hudi数据布局黑科技了解下
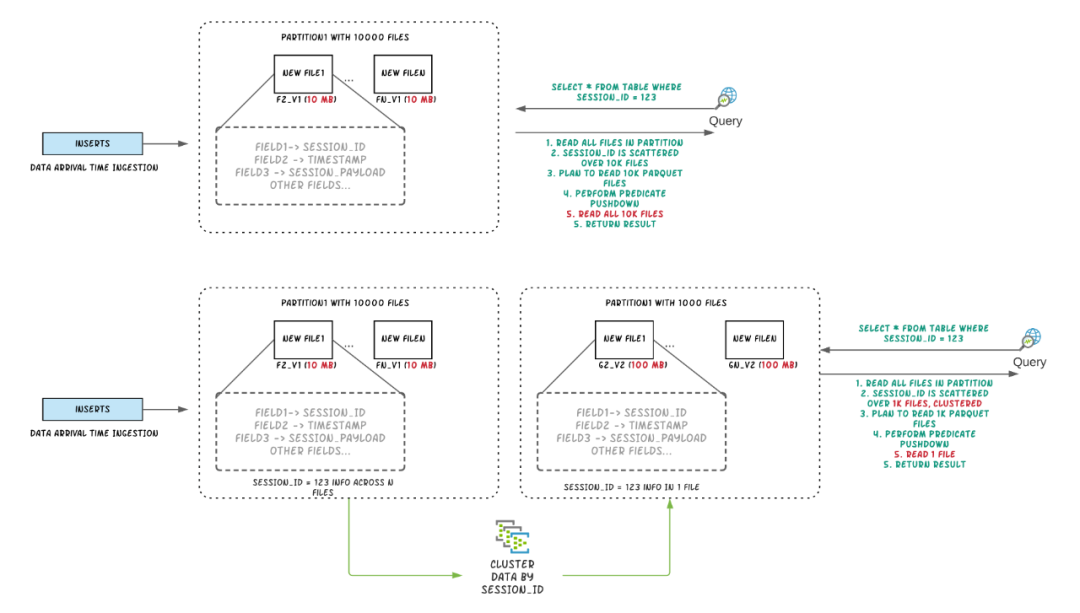
1. 背景 Apache Hudi将流处理带到大数据,相比传统批处理效率高一个数量级,提供了更新鲜的数据。在数据湖/仓库中,需要在摄取速度和查询性能之间进行权衡,数据摄取通常更喜欢小文件以改善并行性并使数据尽快可用于查询,但很多小文件会导致查询性能下降。在摄取过程中通常会根据时间在同一位置放置数据,但如果把查询频繁的数据放在一起时,查询引擎的性能会更好,大多数系统都倾向于支持独立的优化来...
Apache Hudi与Apache Flink更好地集成,最新方案了解下?
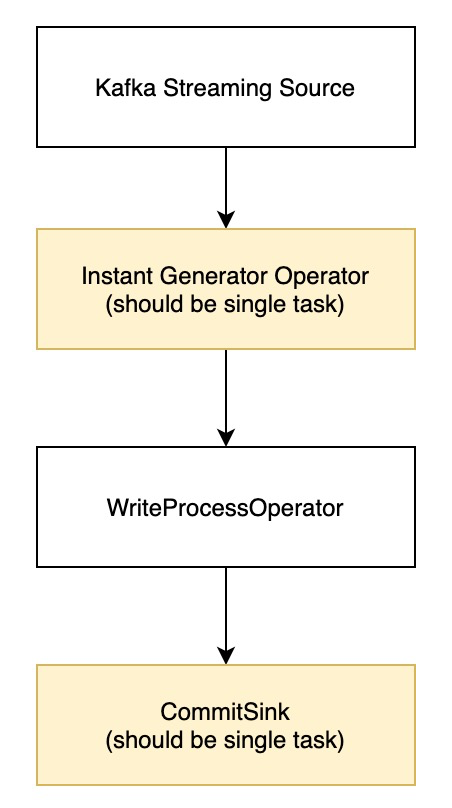
1. 现有架构 现有Flink写Hudi架构如下 现有的架构存在如下瓶颈 •InstantGeneratorOperator并发度为1,将限制高吞吐的消费,因为所有的split都将会打到一个线程内,网络IO会...
使用Apache Hudi构建下一代Lakehouse
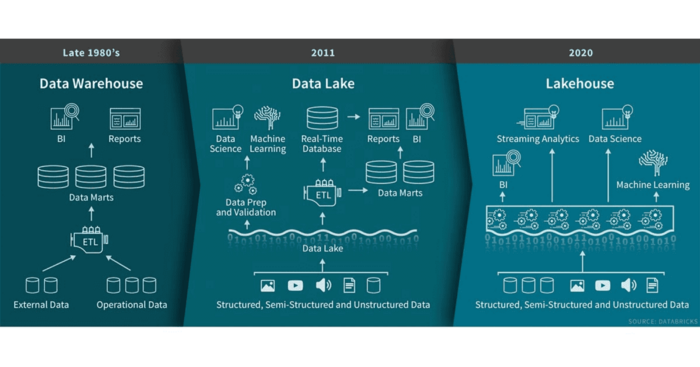
1. 概括 本文介绍了一种称为Data Lakehouse的现代数据架构范例。Data Lakehouse相比于传统的数据湖具有很多优势,本文说明了如何通过现代化数据平台并使用Lakehouse架构来应对客户端所面临的可扩展性、数据质量和延迟方面的挑战。本文介绍了使用Apache Hudi实现Data Lakehouse的基本知识和步骤。 2. 前言 过去十年随着物联网、...
Apache Flink 1.12.2集成Hudi 0.9.0运行指南
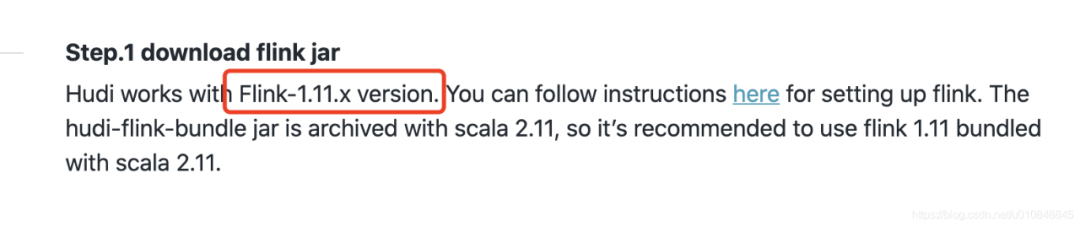
1. 准备工作 1. 编译包下载 •下载Flink 1.12.2包:https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.12.2/flink-1.12.2-bin-scala_2.11.tgz•Hudi编译:https://github.com/apache/hudi•git clone https://github...
一文彻底掌握Apache Hudi的主键和分区配置
1. 介绍 Hudi中的每个记录都由HoodieKey唯一标识,HoodieKey由记录键和记录所属的分区路径组成。基于此设计Hudi可以将更新和删除快速应用于指定记录。Hudi使用分区路径字段对数据集进行分区,并且分区内的记录有唯一的记录键。由于仅在分区内保证唯一性,因此在不同分区之间可能存在具有相同记录键的记录。应该明智地选择分区字段,因为它可能影响摄取和查询延迟。 2. K...
Apache Hudi在Linkflow构建实时数据湖的生产实践
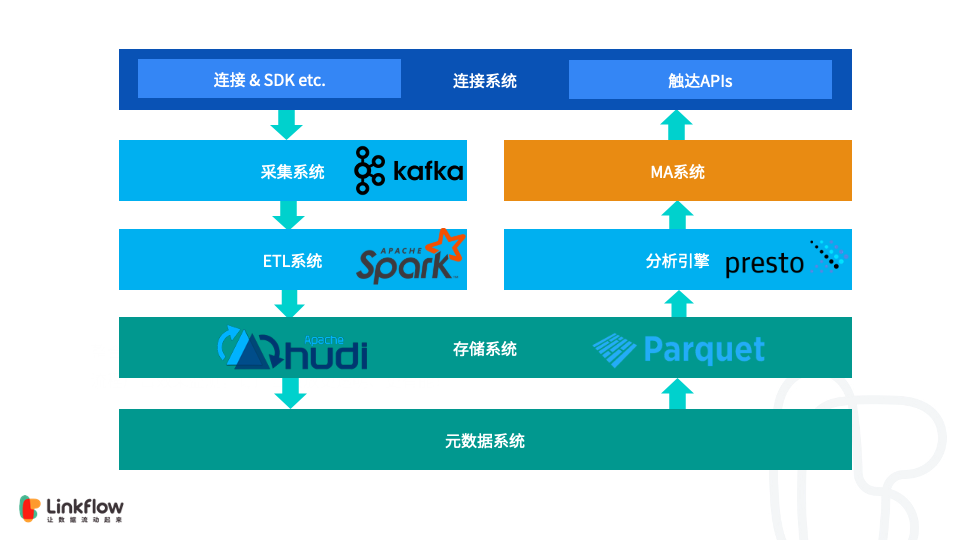
1. 背景 Linkflow 作为客户数据平台(CDP),为企业提供从客户数据采集、分析到执行的运营闭环。每天都会通过一方数据采集端点(SDK)和三方数据源,如微信,微博等,收集大量的数据。这些数据都会经过清洗,计算,整合后写入存储。使用者可以通过灵活的报表或标签对持久化的数据进行分析和计算,结果又会作为MA (Marketing Automation) 系统的数据源,从而实现对特定人群...
在AWS Glue中使用Apache Hudi
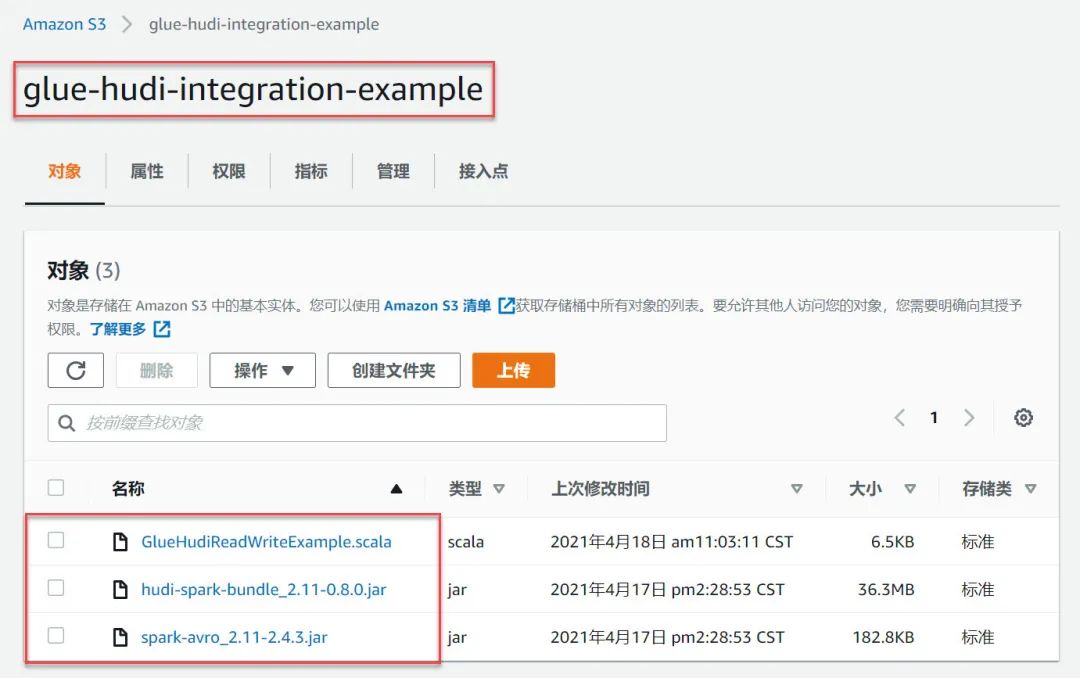
1. Glue与Hudi简介 •AWS Glue AWS Glue是Amazon Web Services(AWS)云平台推出的一款无服务器(Serverless)的大数据分析服务。对于不了解该产品的读者来说,可以用一句话概括其实质:Glue是一个无服务器的全托管的Spark运行环境,只需提供Spark程序代码即可运行Spark作业,无需维护集群。 •Apache Hud...
使用Apache Pulsar + Hudi 构建Lakehouse方案了解下?
由StreamNative Founder & CEO 郭斯杰 执笔的Apache Pulsar作为Lakehouse的提案,阐述如何利用Apache Hudi解决Pulsar作为Lakehouse的痛点问题,强烈推荐! 1. 动机 Lakehouse最早由Databricks公司提出,其可作为低成本、直接访问云存储并提供传统DBMS管系统性能和ACID事务、版...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache更多hudi相关
- Apache hudi lakehouse
- hudi Apache
- Apache hudi s3
- Apache hudi最佳实践
- Apache hudi架构
- Apache hudi cdc
- Apache hudi构建管道
- Apache hudi管道
- Apache hudi分析
- Apache hudi存储
- Apache hudi数据湖
- Apache hudi构建数据湖
- Apache hudi构建lakehouse
- Apache hudi集成
- Apache hudi索引
- Apache hudi数据湖实践
- Apache hudi平台
- Apache hudi方案
- 数据湖Apache hudi
- Apache hudi概念
- 实战Apache hudi
- Apache hudi实时数据湖
- Apache hudi流批一体实践
- Apache hudi核心概念
- Apache hudi模式
- Apache hudi机制
- Apache hudi异步
- Apache hudi实战
- Apache hudi清理
- Apache hudi aws
Apache您可能感兴趣
- Apache agent
- Apache data
- Apache版本
- Apache olap
- Apache技术
- Apache解决方案
- Apache doris
- Apache llm
- Apache函数
- Apache湖仓
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache报错
- Apache mysql
- Apache微服务
- Apache访问
- Apache从入门到精通
- Apache kafka
- Apache实践
- Apache应用

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注