
生态 | Apache Hudi集成Apache Zeppelin
1. 简介 Apache Zeppelin 是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等等。当前Hive与SparkSQL已经支持查询Hudi的读优化视图和实时视图。...
Apache Hudi典型应用场景知多少?
1.近实时摄取 将数据从外部源如事件日志、数据库提取到Hadoop数据湖 中是一个很常见的问题。在大多数Hadoop部署中,一般使用混合提取工具并以零散的方式解决该问题,尽管这些数据对组织是非常有价值的。 对于RDBMS摄取,Hudi通过Upserts提供了更快的负载,而非昂贵且低效的批量负载。例如你可以读取MySQL binlog日志或Sqoop增量导入,并将它们应用在DFS上...
实战!配置DataDog监控Apache Hudi应用指标
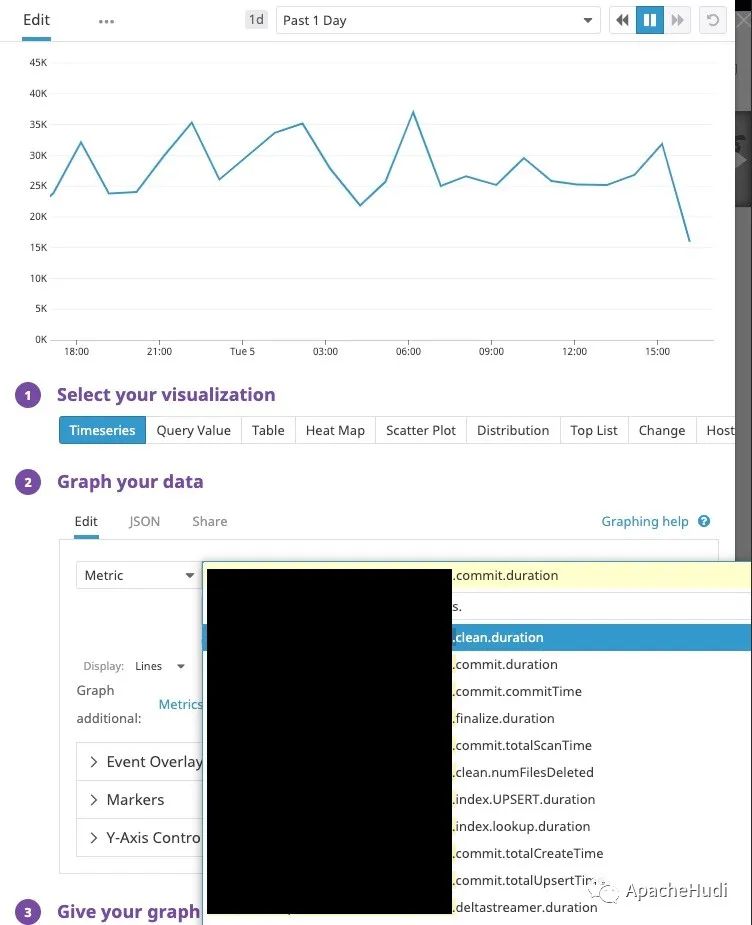
1. 可用性 在Hudi最新master分支,由Hudi活跃贡献者Raymond Xu贡献了DataDog监控Hudi应用指标,该功能将在0.6.0 版本发布,也感谢Raymond的投稿。 2. 简介 Datadog是一个流行的监控服务。在即将发布的Apache Hudi 0.6.0版本中,除已有的报告者类型(Graphite和JMX)之外,我们将引入通过Datadog ...
Apache Hudi:云数据湖解决方案
1. 引入 开源Apache Hudi项目为Uber等大型组织提供流处理能力,每天可处理数据湖上的数十亿条记录。 随着世界各地的组织采用该技术,Apache开源数据湖项目已经日渐成熟。 Apache Hudi(Hadoop Upserts Deletes and Incrementals)是一个数据湖项目,可在与Apache Hadoop兼容的云存储系统(包括Amazon...
使用Apache Hudi构建大规模、事务性数据湖
一个近期由Hudi PMC & Uber Senior Engineering Manager Nishith Agarwal分享的Talk 关于Nishith Agarwal更详细的介绍,主要从事数据方面的工作,包...

Apache Hudi重磅RFC解读之存量表高效迁移机制
1. 摘要 随着Apache Hudi变得越来越流行,一个挑战就是用户如何将存量的历史表迁移到Apache Hudi,Apache Hudi维护了记录级别的元数据以便提供upserts和增量拉取的核心能力。为利用Hudi的upsert和增量拉取能力,用户需要重写整个数据集让其成为Hudi表。此RFC提供一个无需重写整张表的高效迁移机制。 2. 背景 为了更好的了解此RFC...

Apache Hudi 异步Compaction部署方式汇总
本篇文章对执行异步Compaction的不同部署模型全面汇总。 1. Compaction 对于Merge-On-Read表,数据使用列式Parquet文件和行式Avro文件存储,更新被记录到增量文件,然后进行同步/异步compaction生成新版本的列式文件。Merge-On-Read表可减少数据摄入延迟,因而进行不阻塞摄入的异步Compaction很有意义。 2. 异...
使用Apache Hudi + Amazon EMR进行变化数据捕获(CDC)
前一篇文章中我们讨论了如何使用Amazon数据库迁移服务(DMS)无缝地收集CDC数据。 https://towardsdatascience.com/data-lake-change-data-capture-cdc-using-amazon-database-migration-service-part-1-capture-b43c3422aad4 下面将演示如何处理CDC数...
最佳实践 | 通过Apache Hudi和Alluxio建设高性能数据湖
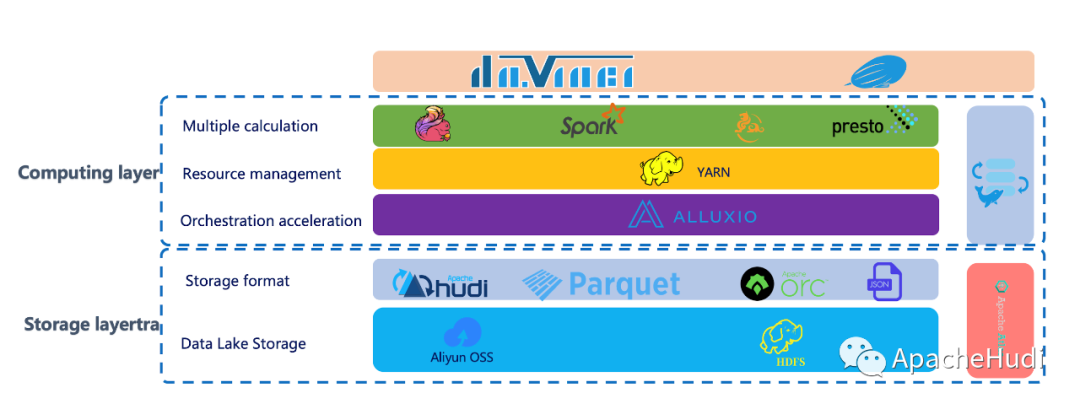
T3出行的杨华和张永旭描述了他们数据湖架构的发展。该架构使用了众多开源技术,包括Apache Hudi和Alluxio。在本文中,您将看到我们如何使用Hudi和Alluxio将数据摄取时间缩短一半。此外,数据分析人员如何使用Presto、Hudi和Alluxio让查询速度提高了10倍。我们基于数据编排为数据管道的多个阶段(包括提取和分析)构建了数据湖。 1.T3出行数据湖总览 T...
Apache Hudi + Flink作业运行指南
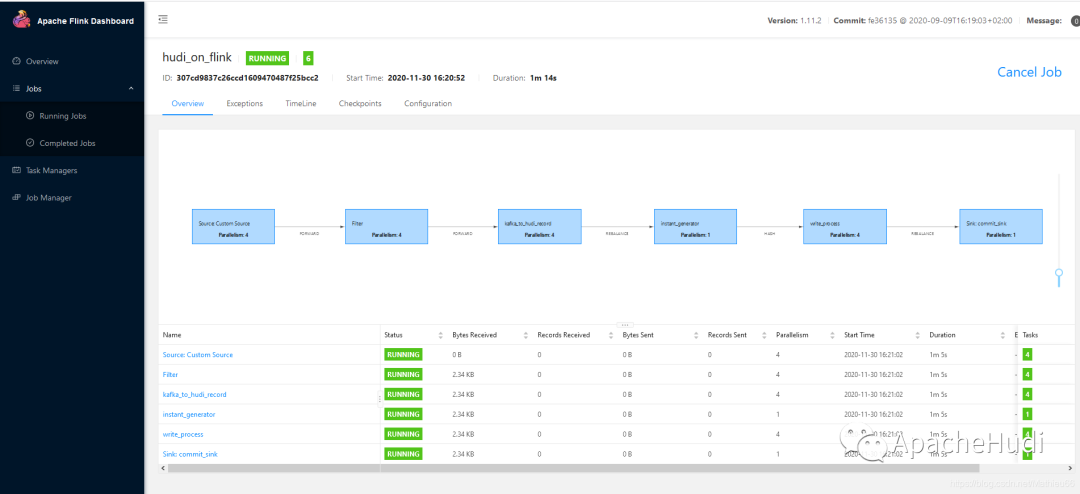
近日Apache Hudi社区合并了Flink引擎的基础实现(HUDI-1327),这意味着 Hudi 开始支持 Flink 引擎。有很多小伙伴在交流群里咨询 Hudi on Flink 的使用姿势,三言两语不好描述,不如实操演示一把,于是有了这篇文章。 当前 Flink 版本的Hudi还只支持读取 Kafka 数据,Sink到 COW(COPY_ON_WRITE) 类型的 Hudi 表...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache更多hudi相关
- Apache hudi lakehouse
- hudi Apache
- Apache hudi s3
- Apache hudi最佳实践
- Apache hudi架构
- Apache hudi cdc
- Apache hudi构建管道
- Apache hudi管道
- Apache hudi分析
- Apache hudi存储
- Apache hudi数据湖
- Apache hudi构建数据湖
- Apache hudi构建lakehouse
- Apache hudi集成
- Apache hudi索引
- Apache hudi数据湖实践
- Apache hudi平台
- Apache hudi方案
- 数据湖Apache hudi
- Apache hudi概念
- 实战Apache hudi
- Apache hudi实时数据湖
- Apache hudi流批一体实践
- Apache hudi核心概念
- Apache hudi模式
- Apache hudi机制
- Apache hudi异步
- Apache hudi实战
- Apache hudi清理
- Apache hudi aws
Apache您可能感兴趣
- Apache agent
- Apache data
- Apache版本
- Apache olap
- Apache技术
- Apache解决方案
- Apache doris
- Apache llm
- Apache函数
- Apache湖仓
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache报错
- Apache mysql
- Apache微服务
- Apache访问
- Apache从入门到精通
- Apache kafka
- Apache实践
- Apache应用

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注