
Python爬虫库性能与选型实战指南:从需求到落地的全链路解析
在数据驱动的时代,爬虫技术已成为获取网络信息的核心工具。无论是市场调研、学术研究还是商业决策,高效稳定的爬虫系统都是关键基础设施。但面对Requests、Scrapy、Selenium等数十种技术方案,开发者常陷入"库多难选"的困境。本文通过真实场景案例,从需求分析到性能优化,提供可落地的技术选型方法论。 ...

大数据岗位技能需求挖掘:Python爬虫与NLP技术结合
引言随着大数据技术的快速发展,企业对大数据人才的需求日益增长。了解当前市场对大数据岗位的技能要求,可以帮助求职者精准提升技能,也能为企业招聘提供数据支持。本文介绍如何利用 Python爬虫 从招聘网站(如拉勾网、智联招聘)抓取大数据相关岗位信息,并采用 自然语言处理(NLP) 技术对岗...
Python异步爬虫(aiohttp)加速微信公众号图片下载
引言在数据采集领域,爬取微信公众号文章中的图片是一项常见需求。然而,传统的同步爬虫(如requests)在面对大量图片下载时,由于I/O阻塞问题,效率较低。而异步爬虫(如aiohttp)可以显著提升爬取速度,尤其适用于高并发的网络请求场景。 异步爬虫 vs 同步爬虫1.1...
Python爬虫分析B站番剧播放量趋势:从数据采集到可视化分析
引言B站(Bilibili)作为中国领先的年轻人文化社区和视频平台,其番剧区一直是动漫爱好者聚集的重要场所。对于内容创作者、版权方以及市场分析师而言,了解B站番剧的播放量趋势具有重要价值。本文将详细介绍如何使用Python爬虫技术获取B站番剧数据,并进行播放量趋势分析。一、技术准备在开始之前,我们需要准备以下工具和库:● Py...
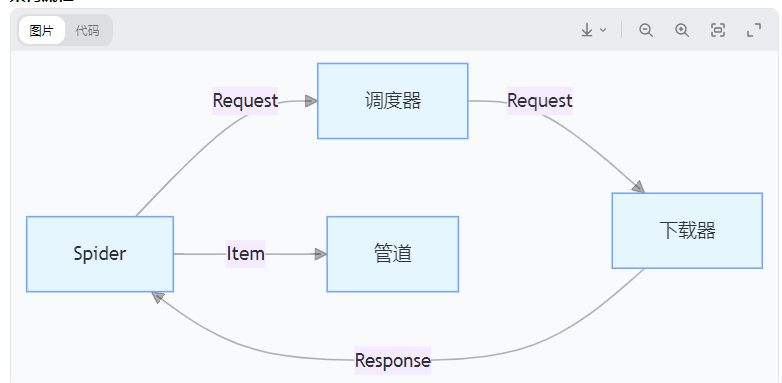
Python爬虫案例:Scrapy+XPath解析当当网网页结构
引言在当今大数据时代,网络爬虫已成为获取互联网信息的重要工具。作为Python生态中最强大的爬虫框架之一,Scrapy凭借其高性能、易扩展的特性受到开发者广泛青睐。本文将详细介绍如何利用Scrapy框架结合XPath技术解析当当网的商品页面结构,实现一个完整的电商数据爬取案例。一、Scrapy框架概述Scrapy是一个为了爬取网站数据、提取结构性数据而编...
基于Python的新闻爬虫:实时追踪行业动态
引言在信息时代,行业动态瞬息万变。金融从业者需要实时了解政策变化,科技公司需要跟踪技术趋势,市场营销人员需要掌握竞品动向。传统的人工信息收集方式效率低下,难以满足实时性需求。Python爬虫技术为解决这一问题提供了高效方案。本文将详细介绍如何使用Python构建新闻爬虫系统,实现行业动态的实时追踪。我们将从技术选型、爬虫实现、...
Python爬虫框架对比:Scrapy vs Requests在API调用中的应用
在 API 调用场景中,Scrapy 和 Requests 作为 Python 主流爬虫框架,有着截然不同的设计定位与适用场景。以下从架构设计、API 调用模式、性能优化、适用场景四个维度展开对比,并给出实战建议。一、架构设计:从单线程到异步引擎的差异 Requests:轻量级同步请求库核心特点:基于urllib...
Python爬虫实战:批量下载亚马逊商品图片
引言在电商数据分析、竞品调研或价格监控等场景中,爬取亚马逊商品图片是一项常见需求。然而,亚马逊(Amazon)作为全球最大的电商平台之一,具有严格的反爬机制,直接爬取可能会遇到IP封锁、验证码等问题。本文将介绍如何使用Python爬虫技术批量下载亚马逊商品图片,涵盖以下内容:● 目标分...
多线程Python爬虫:加速大规模学术文献采集
引言在学术研究过程中,高效获取大量文献数据是许多科研工作者和数据分析师的需求。然而,传统的单线程爬虫在面对大规模数据采集时,往往效率低下,难以满足快速获取数据的要求。因此,利用多线程技术优化Python爬虫,可以显著提升数据采集速度,尤其适用于爬取学术数据库(如PubMed、IEEE ...
解决Python爬虫访问HTTPS资源时Cookie超时问题
一、问题背景:Cookie 15 秒就失效了?很多互联网图片站为了防止盗链,会把图片地址放在 HTTPS 接口里,并且给访问者下发一个带 Path=/ 的 Cookie,有效期极短(15 s~60 s)。常规 Requests 脚本在下载第二张图时就会 401 或 403。本文...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Python更多爬虫相关
- Python爬虫性能
- Python爬虫解析
- Python爬虫实战
- Python爬虫库
- Python爬虫技术
- Python爬虫微信公众号
- Python爬虫aiohttp
- Python爬虫微信
- Python异步爬虫
- Python爬虫https
- Python爬虫scrapy
- Python爬虫数据
- Python爬虫爬取
- Python爬虫入门
- Python爬虫入门教程
- Python爬虫抓取
- Python爬虫网页
- Python爬虫Scrapy框架
- Python爬虫beautifulsoup
- Python爬虫分析
- Python爬虫数据抓取
- Python爬虫信息
- Python爬虫项目实战
- Python爬虫urllib
- Python爬虫网站
- Python爬虫请求
- Python爬虫策略
- Python爬虫代理
- Python爬虫报错
- Python爬虫xpath
