
25 MAPREDUCE的shuffle机制
概述mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle;shuffle: 洗牌、发牌——(核心机制:数据分区,排序,缓存);具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;主要流程Shuffle缓存流程:shuffle是MR处理....

Mapreduce执行机制之提交任务和切片原理
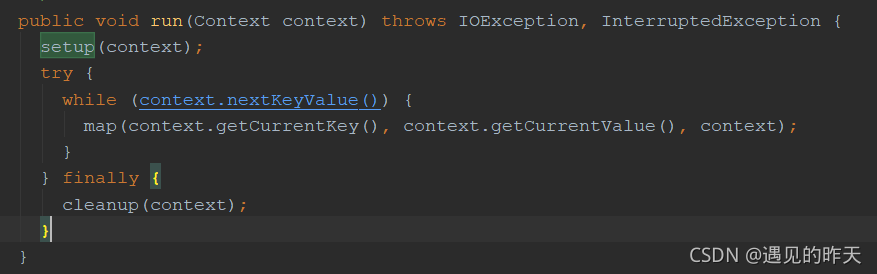
1、Mapper 类 * Maps input key/value pairs to a set of intermediate key/value pairs. * * <p>Maps are the individual tasks which transform input records into a * intermediate records. The tr...
MapReduce执行机制之Map和Reduce源码分析
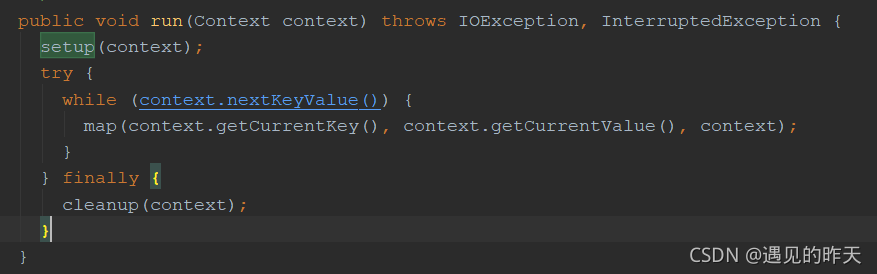
1、Mapper 类 * Maps input key/value pairs to a set of intermediate key/value pairs. * * <p>Maps are the individual tasks which transform input records into a * intermediate records. The tr...
Hadoop中的MapReduce框架原理、Shuffle机制、Partition分区、自定义Partitioner步骤、在Job驱动中,设置自定义Partitioner、Partition 分区案例
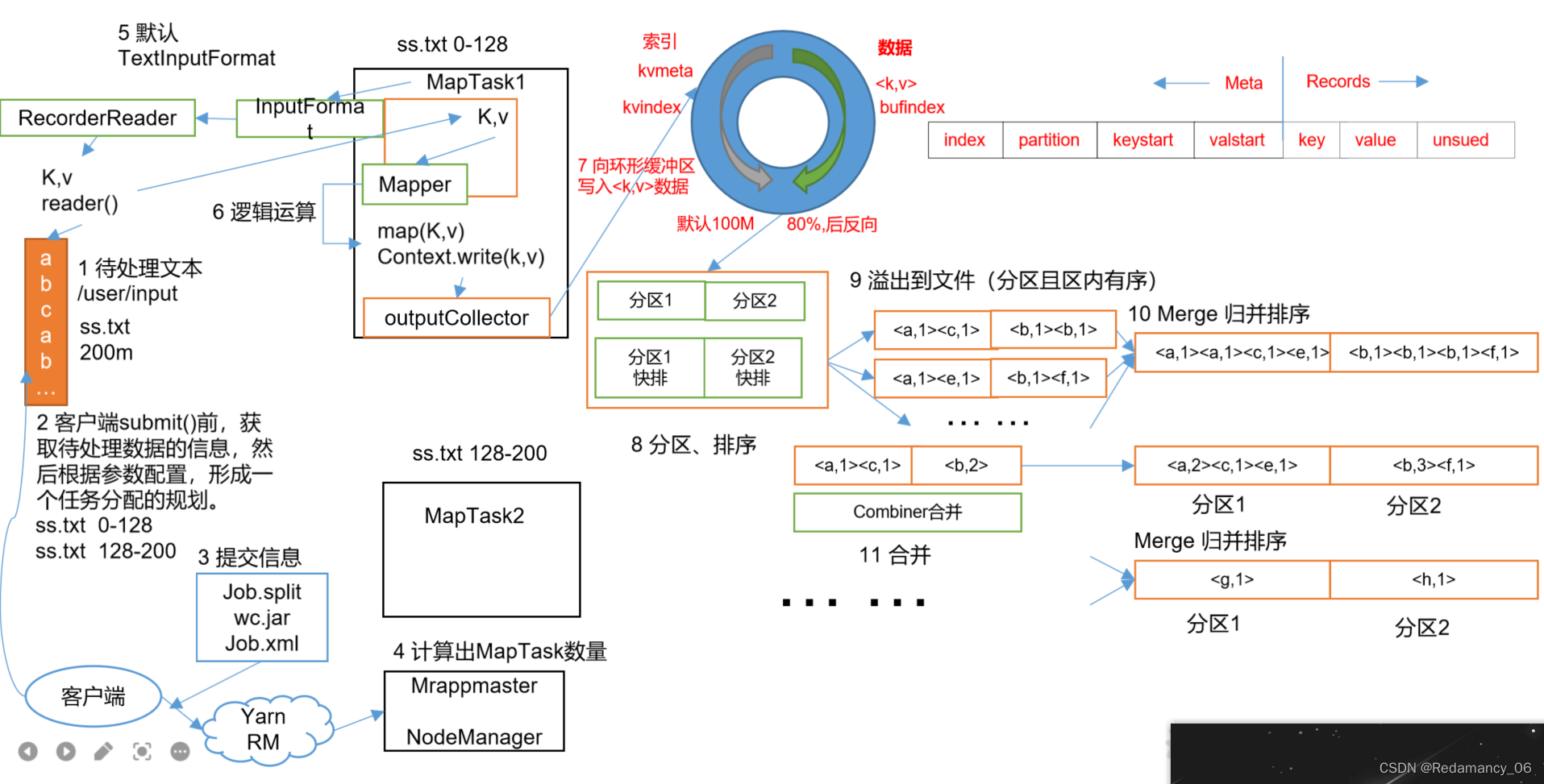
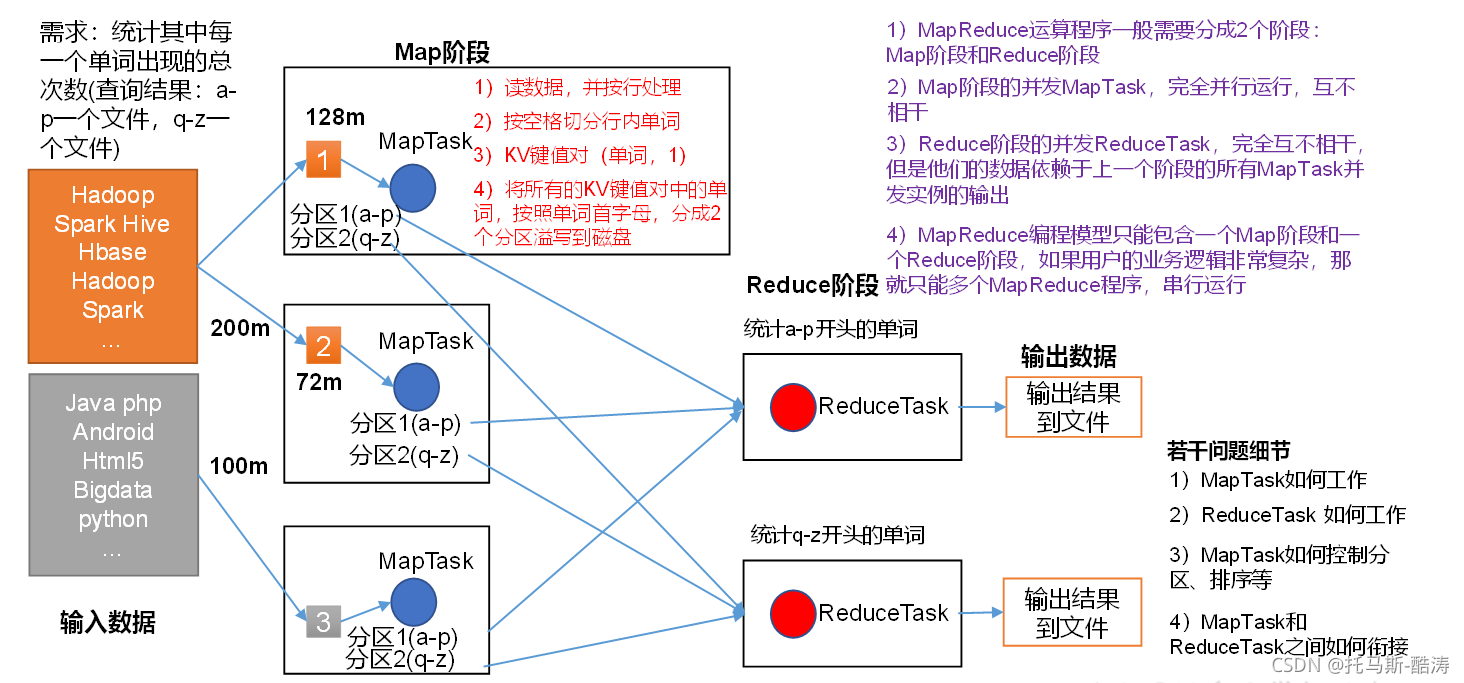
13.MapReduce框架原理13.2MapReduce工作流程上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件(3)多个溢出文件会被合并成大的溢出文件(4)在溢出过程及合并的....
Hadoop中的MapReduce框架原理、Job提交流程源码断点在哪断并且介绍相关源码、切片与MapTask并行度决定机制、MapTask并行度决定机制
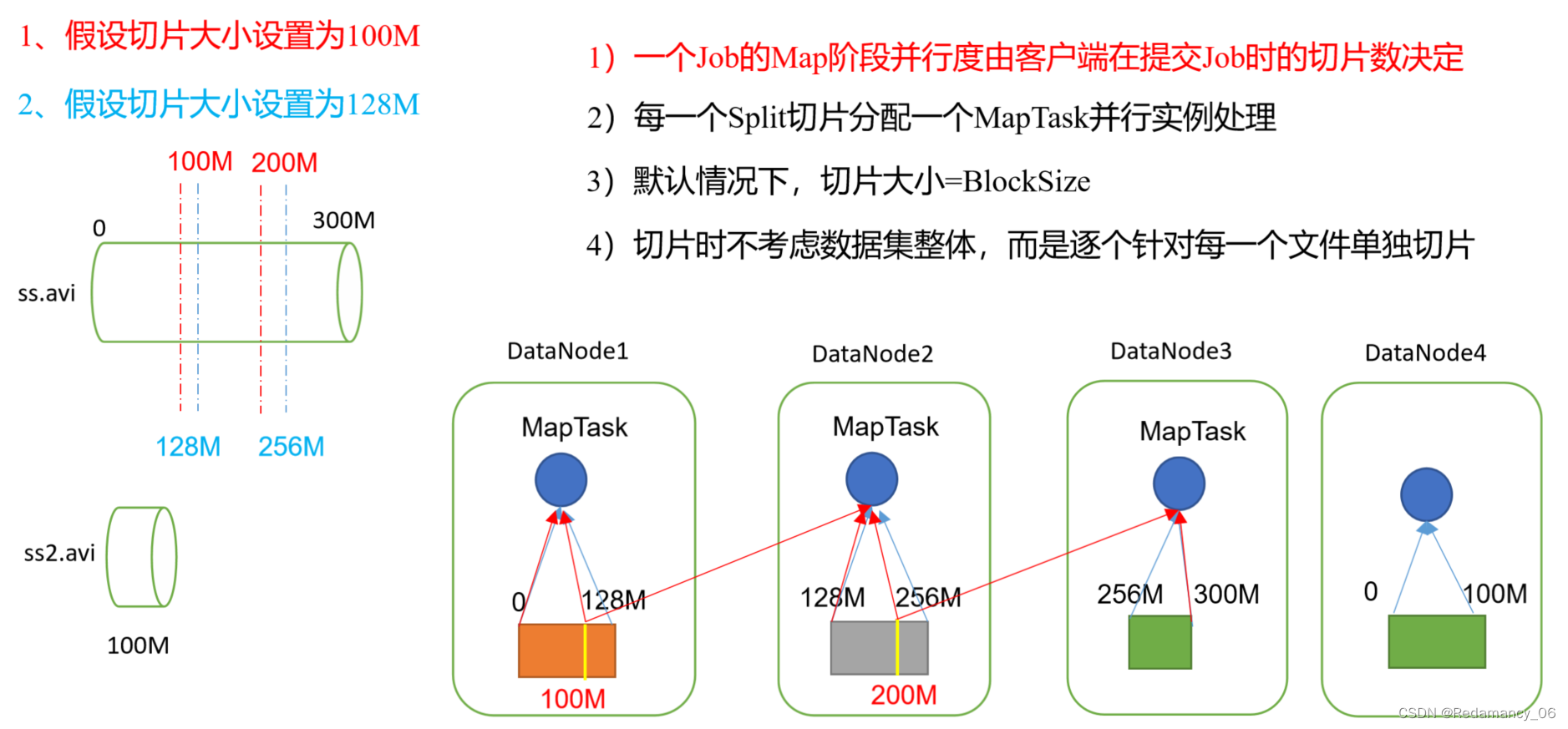
@[toc]13.MapReduce框架原理13.1InputFormat数据输入13.1.1切片与MapTask并行度决定机制13.1.1.1问题引出MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度 思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是....
二十四、MapReduce工作机制
MapReduce概述:1 、MapReduce定义 Mapredude是一个分布式运算程序的编程框架,是用户开发" 基于Hadoop 的数据分析应用" 的核心框架。 MapReduce的核心功能是将用户编写.....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce机制相关内容
mapreduce您可能感兴趣
- mapreduce自定义
- mapreduce groupingcomparator
- mapreduce分组
- mapreduce pagerank
- mapreduce应用
- mapreduce算法
- mapreduce shuffle
- mapreduce区别
- mapreduce大规模
- mapreduce数据
- mapreduce hadoop
- mapreduce集群
- mapreduce spark
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式
