【CaiT】如何才能使VIT网络往更深层发展
前言 近些天综合看CNN 领域内的文章以及VIT领域内的文章,在比对这两大类模型设计的特点时有一篇文章提醒到我了,它与CNN领域内的里程碑网络结构RESNET有异曲同工之妙。《Going deeper with Image Transformers》这篇论文的出现,将我们带入了一个更加深入的探索,试图回答一个重要问题:我们是否能够用Transformer模型在图像处理中取得类似于在自...
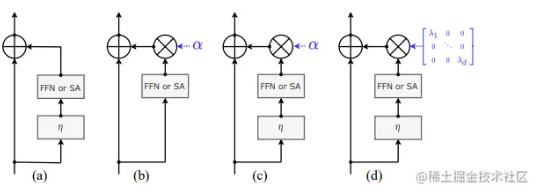
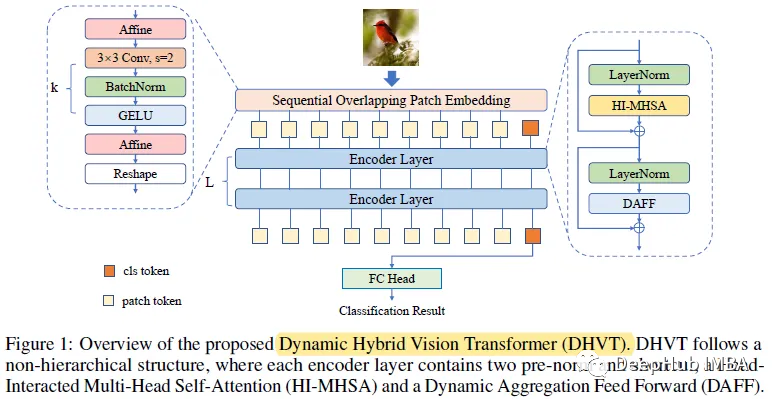
DHVT:在小数据集上降低VIT与卷积神经网络之间差距,解决从零开始训练的问题
在空间方面,采用混合结构,将卷积集成到补丁嵌入和多层感知器模块中,迫使模型捕获令牌特征及其相邻特征。 在信道方面,引入了MLP中的动态特征聚合模块和多头注意力模块中全新的“head token”设计,帮助重新校准信道表示,并使不同的信道组表示相互交互。 Dynamic Hybrid Vision Transformer (DHVT) 1、顺序重叠补丁嵌入 (Sequential Ove...
CVPR 2022 | 提高小数据集利用效率,复旦等提出分层级联ViT网络
来自复旦大学、上海市智能信息处理重点实验室和香港大学的研究者提出了一种基于 DINO 知识蒸馏架构的分层级联 Transformer (HCTransformer) 网络。 小样本学习是指从非常少量的标记数据中进行学习的问题,它有望降低标记成本,实现低成本、快速的模型部署,缩小人类智能与机器模型之间的差距。小样本学习的关键问题是如何高效地利用隐藏在标注数据中的丰富信息中进行学习。近年来,...

搭建小型ViT网络构架进行分类任务(Pytorch)
前言 在这里我们不过多叙述原理,为了实验的便捷性,我们选择最为常见的MNIST数据集,Demo的构架我们采用我往期的动手撸个MNIST分类(CPU版本+GPU版本) 中GPU版本作为母版Vision Transformers 大体框架 为了能够使用自己的ViT模型应用到MNIST分类中去(替换class Net(nn.Module) 模块)可搭建如下框架:class ViTNet(nn.Mo....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

域名解析DNS
关注DNS技术、标准、产品和行业趋势,连接国内外相关技术社群信息,加强信息共享。
+关注