
Python pickle 二进制序列化和反序列化 - 数据持久化
模块 pickle 实现了对一个 Python 对象结构的二进制序列化和反序列化。 "pickling" 是将 Python 对象及其所拥有的层次结构转化为一个字节流的过程,而 "unpickling" 是相反的操作,会将(来自一个 binary file 或者 bytes-like object 的)字节流转化回一个对象层次结构。 pickling(和 unpickling)也被称为“序列化”....
iOS的数据序列化(又称持久化)的两类使用方式
java,mac,object c都有各自的序列化保存方法。 现在介绍下iOS的数据序列化保存。 一般分为用单例来实现数据的序列化保存和用对象来实现数据的序列化保存。 第一类:用单例来实现数据的序列化保存。 用户登录数据的序列化保存一般使用单例来实现,根据是否有登录信息来决定是到登录页面还是到其它页面。 它通常包含获取用户信息,得到用户信息(读取文件),清...
数据序列化和持久化是什么
蚂蚁区块链智能合约平台分别提供了基础数据类型的序列化和用户自定义数据类型的持久化方法。基础数据序列化使用 Schema 持久化数据基础数据序列化可序列化的数据可以使用 pack() 函数序列化为字节串(即std::string),并且可以使用unpack()函数将对应的字节串反序列化为原来的值。pa...
如何实现数据序列化和持久化
蚂蚁区块链智能合约平台分别提供了基础数据类型的序列化和用户自定义数据类型的持久化方法。基础数据序列化使用 Schema 持久化数据基础数据序列化可序列化的数据可以使用 pack() 函数序列化为字节串(即std::string),并且可以使用unpack()函数将对应的字节串反序列化为原来的值。pa...
Spark学习--3、WordCount案例、RDD序列化、RDD依赖关系、RDD持久化(二)
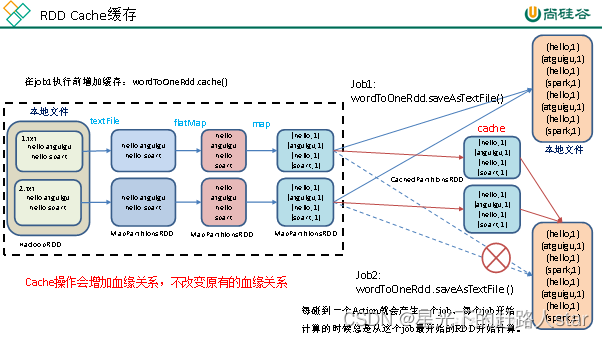
4、RDD持久化4.1 RDD Cache缓存1、RDD Cache缓存(1)RDD通过Cache或者persist方法将前面的计算结果缓存(2)默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。(3)但是并不是这个两个方法被调用时立即缓存,而是触发后面的action算子时,该RDD将会被缓存在计算节点的内存中,并供后面重用。2、创建包名com.zhm.spark.operator.cac....
Spark学习--3、WordCount案例、RDD序列化、RDD依赖关系、RDD持久化(一)
1、WordCount案例实操导入项目依赖<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <versi...
对象持久化和数据序列化
对象持久化(Persistence)对象持久化就是将对象存储在可持久保存的存储介质上,例如主流的关系数据库中。对象持久化就是让对象的生存期超越使用对象的程序的运行期,就是save/load数据序列化(Serialization)数据序列化就是将对象或者数据结构转化成特定的格式,使其可在网络中传输,或者可存储在内存或者文件中。二进制序列化保持类型保真度,这对于在应用程序的不同调用之间保留对象的状态....
.NET简谈组件程序设计之(初识序列化、持久化)
今天我们来学习在组件开发中经常用到的也是比较重要的技术“序列化”。 序列化这个名词对初学者来说不太容易理解,有点抽象。我们还是用传统的分词解释吧,肯定能搞懂它的用意是什么。 解释:数学上,序列是被排成一列的对象(或事件);这样,每个元素不是在其他元素之前,就是在其他元素之后。这里,元素之间的顺序非常重要。 那么我们对照这样的解释来分析一下我们程序中的序列化什么意思。都知道对象的状态是在内存中实时....
iOS archive(归档)的总结 (序列化和反序列化,持久化到文件)
http://www.cnblogs.com/ios8/p/ios-archive.html
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。