
Node Labels调度实践
Node Labels是YARN提供的节点分区功能,使得YARN在调度时能够在物理层面上对不同类型的作业进行有效隔离。本文为您介绍如何根据您的业务类型和节点类型创建相应的Node Labels。
在EMR控制台上管理YARN分区
EMR支持在控制台上通过可视化UI管理YARN分区,同时可以批量建立节点组与分区的映射,方便操作。您可以直接在节点组上配置分区属性,扩容和弹性伸缩后,EMR会自动为新增节点打上Node Label,无需重新配置新节点。本文为您介绍如何在EMR控制台上管理YARN分区。
MapReduce 分区器的作用与重要性
在Hadoop的MapReduce编程模型中,分区器(Partitioner)是一个关键组件,它直接影响着作业的执行效率和最终结果。分区器的作用是在Map阶段和Reduce阶段之间,根据Map输出的键将数据分配到不同的Reduce任务中去。这一步骤对于整个MapReduce作业的性能和输出结果的准确性至关重要。本文将详细介绍分...
DataWorks产品使用合集之在DataWorks中,在MapReduce作业中指定两个表的所有分区如何解决
问题一:DataWorks想在mapreduce中指定两个表的所有分区,有什么办法吗? DataWorks想在mapreduce中指定两个表的所有分区,用 app_id=''不可以,有什么办法吗?job);InputUtils.addTable(TableInfo.builder().tableName("middleoffice_report_transaction_t_wi...

MapReduce编程:自定义分区和自定义计数器
MapReduce编程:自定义分区和自定义计数器一、实验目标熟练掌握Mapper类,Reducer类和main函数的编写方法掌握用mapreduce计算框架中本地聚合的基本用法掌握MapReduce编程的自定义分区操作掌握用mapreduce计算框架中partitioner的基本用法和实现效果掌握MapReduce编程的自定义计数器操作二、实验要求及注意事项给出每个实验的主要实验步骤、实现代码和....
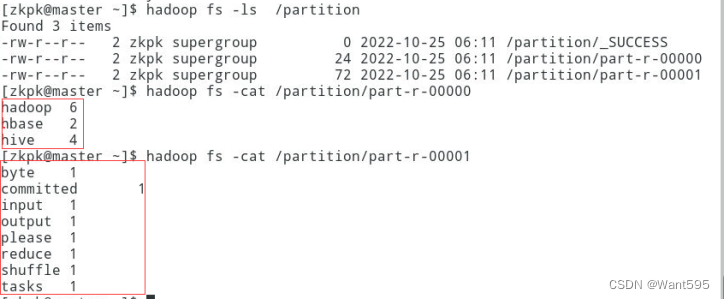
MapReduce【自定义分区Partitioner】
实际开发中我们可能根据需求需要将MapReduce的运行结果生成多个不同的文件,比如上一个案例【MapReduce计算广州2022年每月最高温度】,我们需要将前半年和后半年的数据分开写到两个文件中。默认分区默认MapReduce只能写出一个文件: 因为我们在提交job的时候未设置reduceTask的个数,所以默认reduceTask的个数为1,结果也就只能输出一个文件,下面是数据写入文件时,默....
DataWorks想在mapreduce中指定两个表的所有分区
使用 app_id='' 不可以指定所有的分区,您可以尝试使用通配符 "" 来代替空字符串,如 "app_id=''"。例如: InputUtils.addTable(TableInfo.builder().tableName("middleoffice_report...
DataWorks想在mapreduce中指定两个表的所有分区,有什么办法吗?
DataWorks想在mapreduce中指定两个表的所有分区,用 app_id=''不可以,有什么办法吗?job);InputUtils.addTable(TableInfo.builder().tableName("middleoffice_report_transaction_t_wideorder_dws").partSpec("app_id=''").build(), job);Out....
请问下阿里云E-MapReduce 能实现覆盖写单分区吗?
请问下阿里云E-MapReduce datax同步hdfs数据至sr的单个分区中 能实现覆盖写单分区吗? 目前2.3版本
29 MAPREDUCE中的分区Partitioner
需求根据归属地输出流量统计数据结果到不同文件,以便于在查询统计结果时可以定位到省级范围进行。分析Mapreduce中会将map输出的kv对,按照相同key分组,然后分发给不同的reducetask。默认的分发规则为:根据key的hashcode%reducetask数来分发。所以:如果要按照我们自己的需求进行分组,则需要改写数据分发(分组)组件Partitioner。自定义一个CustomPar....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce分区相关内容
mapreduce您可能感兴趣
- mapreduce shuffle
- mapreduce区别
- mapreduce大规模
- mapreduce数据
- mapreduce列表
- mapreduce集群
- mapreduce聚合
- mapreduce可视化
- mapreduce driver
- mapreduce序列化
- mapreduce hadoop
- mapreduce spark
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式
- mapreduce服务