Hadoop快速入门——第三章、MapReduce案例(字符统计)(2)
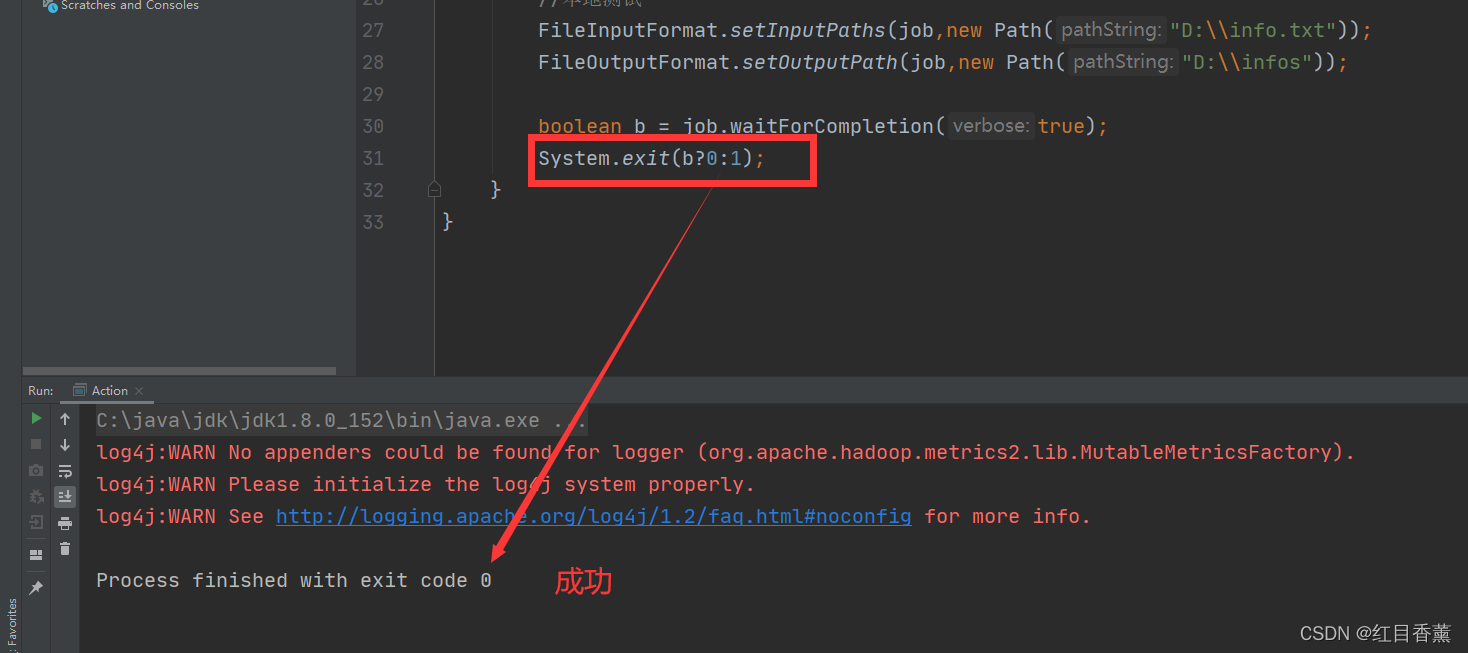
4、本地文件测试本地测试文件【D:\\info.txt】:Accept that this is your starting point.Instead of placing judgements on it,see the real,positive value that’s already yours.You cannot change where your past priorities ....
Hadoop快速入门——第三章、MapReduce案例(字符统计)(1)
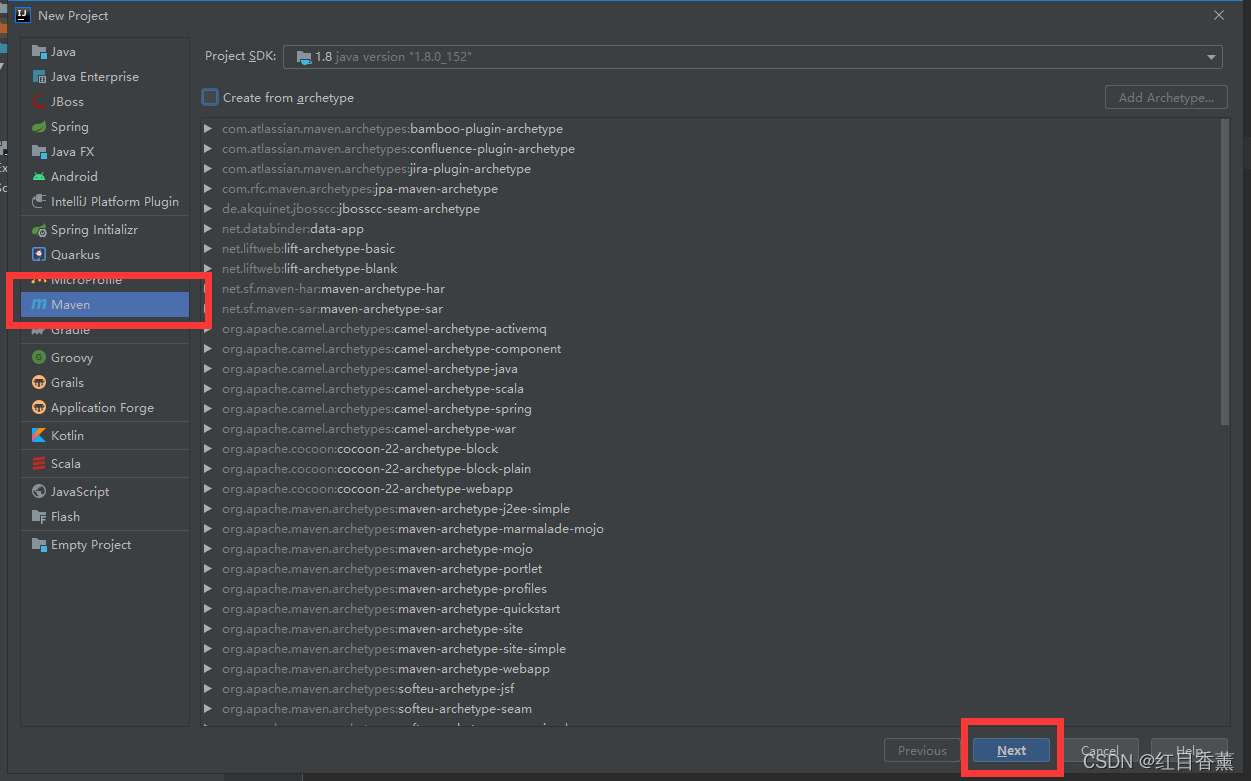
环境要求:1、分布式/伪分布式的hadoop环境【hadoop2.7.3】2、win10本地Java环境【jdk8】3、win10本地hadoop环境【2.7.3】4、win10本地Maven环境【Maven3】5、idea开发工具【IntelliJ IDEA 2020.1.3 x64】1、项目创建:需要建立【maven】项目,建立过程中项目名称无所谓:2、修改Maven点击【file】->...
Hadoop之初识MapReduce
1.MapReduce计算模型介绍1.1.理解MapReduce思想MapReduce的思想核心是“分而治之”。所谓“分而治之”就是把一个复杂的问题按一定的“分解”方法分为规模较小的若干部分,然后逐个解决,分别找出各部分的解,再把把各部分的解组成整个问题的解。这种朴素的思想来源于人们生活与工作的经验,也完全适合于技术领域。诸如软件的体系结构设计、模块化设计都是分而治之的具体表现。即使是发布过论文....

编写MapReduce前置插件Hadoop-Eclipse-Plugin 安装
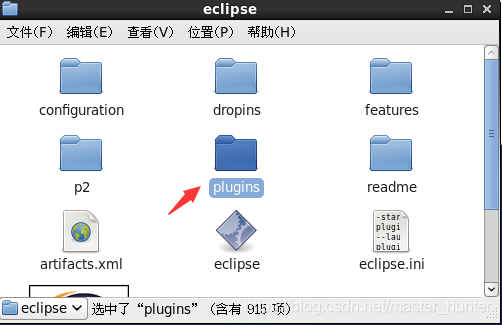
一、获取相应版本的hadoop-eclipse-plugin本人用的是2.2.0版本的插件,大家可以根据自己需求下载不同版本的插件,这里给出下载地址:https://pan.baidu.com/s/1bBvVl2Wc-dQJzBujB_XAKA提取码:0cn9二、解压并配置相应环境1.将hadoop-eclipse-plugin-2.6.0.jar,复制到eclipse安装目录下的plugins....
大数据技术之Hadoop(MapReduce核心思想和工作流程)
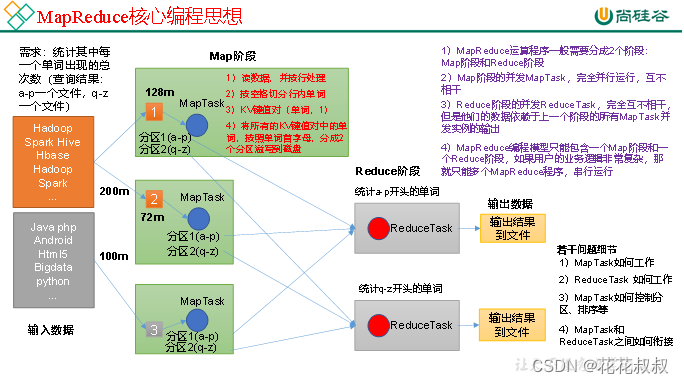
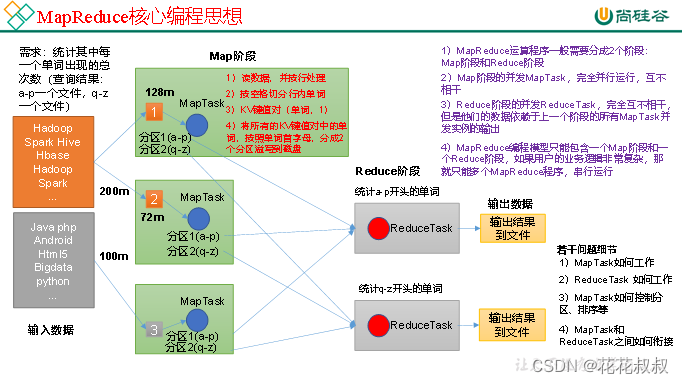
MapReduce 核心思想MapReduce分为Map阶段和Reduce阶段。Map阶段:前两个MapTask对黄色的区域进行统计,最后一个MapTask对灰色区域进行统计,Map阶段先将数据读到内存,之后对数据进行处理,按照空格将单词且分为一个一个的单词,KV键值第一个是单词,第二个是1,因为每一个单词被统计时候,就是相当于出现过一次,然后对所有的KV键值对,按照单词的首字母进行分区处理,分....
大数据技术之Hadoop(MapReduce)
MapReduce定义MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。MapReduce核心思想(1)分布式的运算程序往往需要分成至少2个阶段。(2)第一个阶段的MapTask并发实例,完全并行运行,互不相干....
Hadoop中的MapReduce框架原理、Shuffle机制、Partition分区、自定义Partitioner步骤、在Job驱动中,设置自定义Partitioner、Partition 分区案例
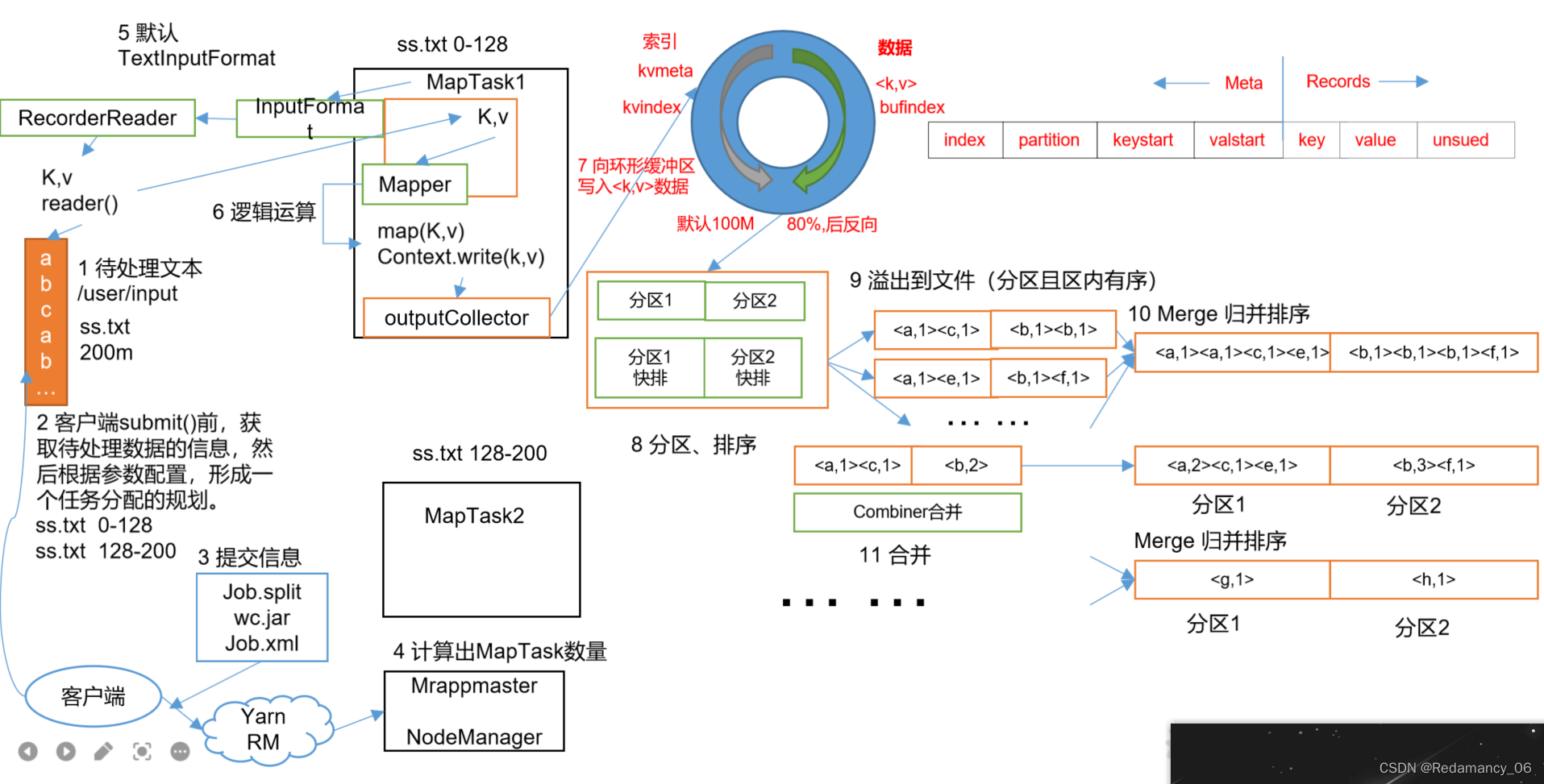
13.MapReduce框架原理13.2MapReduce工作流程上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件(3)多个溢出文件会被合并成大的溢出文件(4)在溢出过程及合并的....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce您可能感兴趣
- mapreduce自定义
- mapreduce groupingcomparator
- mapreduce分组
- mapreduce pagerank
- mapreduce应用
- mapreduce算法
- mapreduce shuffle
- mapreduce区别
- mapreduce大规模
- mapreduce数据
- mapreduce集群
- mapreduce spark
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式
- mapreduce服务