Hadoop学习:深入解析MapReduce的大数据魔力(三)
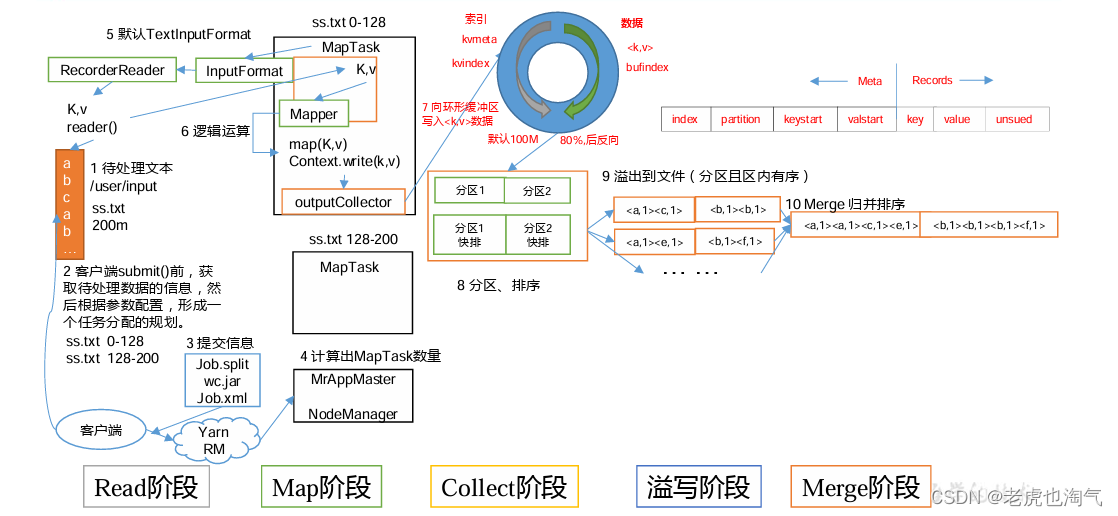
3.5 MapReduce 内核源码解析3.5.1 MapTask 工作机制(1)Read阶段:MapTask通过InputFormat获得的RecordReader,从输入InputSplit中解析出一个个key/value。(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。(3)Collect 收集阶段:在用户编写 ....
Hadoop学习:深入解析MapReduce的大数据魔力(二)
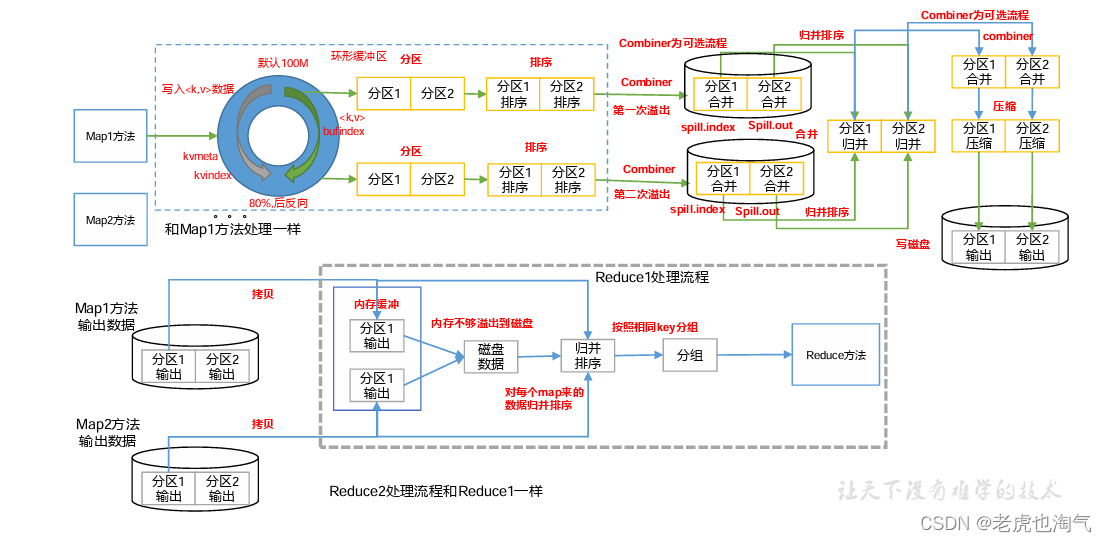
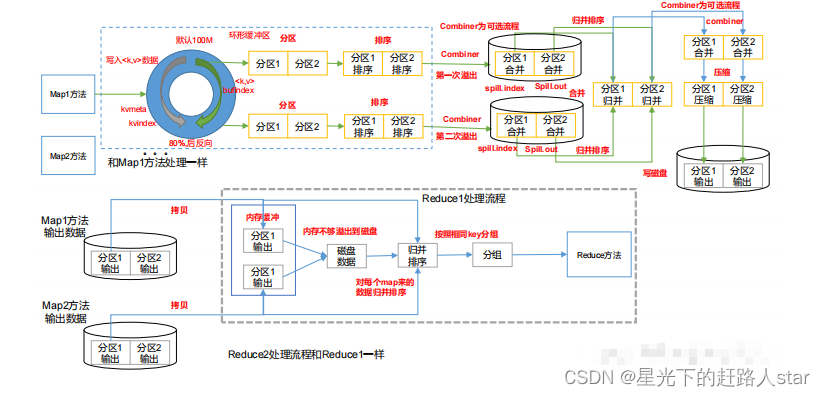
3.3 Shuffle 机制3.3.1 Shuffle 机制Map 方法之后,Reduce方法之前的数据处理过程称之为Shuffle。3.3.2 Partition 分区1、问题引出要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)2、默认Partitioner分区public class HashPartitioner<K, V....
Hadoop学习:深入解析MapReduce的大数据魔力(一)
前言在大数据时代,高效地处理海量数据成为了各行各业的迫切需求。Hadoop作为一种重要的大数据处理框架,其核心概念之一就是MapReduce。今天开始将深入了解MapReduce,探索其在大数据处理中的重要作用。1.MapReduce概述1.1MapReduce 定义MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce 核....
Hadoop学习笔记(三)之MapReduce
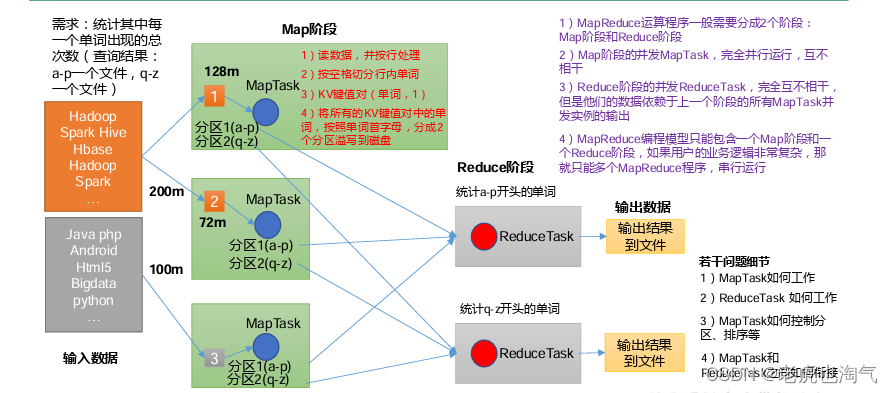
前情回顾Hadoop学习笔记(一)Hadoop学习笔记(二)之HDFSMapReduce1.MapReduce 编程模型1.1 基础1.1.1 是什么?是谷歌开源的一种大数据并行计算编程模型,它降低了并行计算应用开发的门槛。1.1.2 设计目标1) 分而治之。采用分布式并行计算,将计算任务进行拆分,由主节点下的各个子节点共同完成,最后汇总各子节点的计算结果,得出最终计算结果。2) 降低分布式并行....
Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(二)
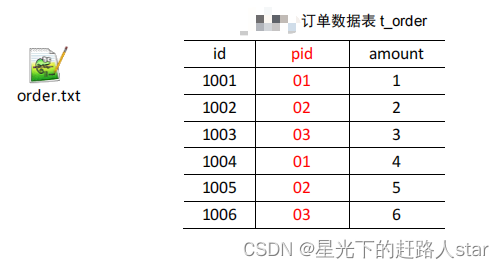
3、Join应用3.1 Reduce Join(1)Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。(2)Reduce端的主要工作:在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在Map阶段已经打标志)分开,最后进行合并....
Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(一)
1、OutputFormat数据输出1.1 OutputFormat接口实现类OutputFormat是MapReduce输出的基类,所以实现MapReduce输出都实现了OutputFormat接口。1、MapReduce默认的输出格式是TextOutputFormat2、也可以自定义OutputFormat类,只要继承就行。1.2 自定义OutputFormat案例实操1、需求过滤输入的 l....
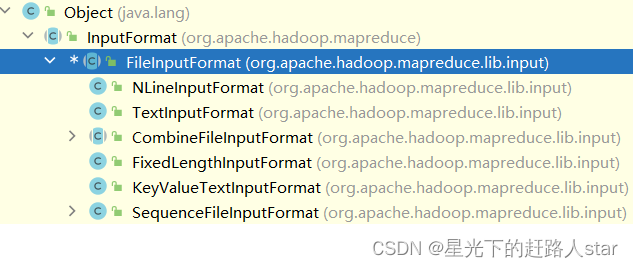
Hadoop基础学习---6、MapReduce框架原理(二)
1.3 Shuffle机制1.3.1 Shuffle机制Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。1.3.2 Partition1、问题引出要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照收集归属地不同省份输出到不同文件中。2、默认Partitioner分区默认分区时根据key的hashCode对ReduceTasks个数取模得到的。用户没法控制....
Hadoop基础学习---6、MapReduce框架原理(一)
1、MapReduce框架原理1.1 InputFormat数据输入1.1.1 切片与MapTask并行度决定机制1、问题引出MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个job的处理速度。2、MapTask并行度决定机制数据块:Block是HDFS物理上吧数据分成一块一块。数据块是HDFS储存数据单位。数据切片:数据切片只是在逻辑上对输出进行分片,并不会在磁盘上将其切分成....
Hadoop基础学习---5、MapReduce概述和WordCount实操(本地运行和集群运行)、Hadoop序列化
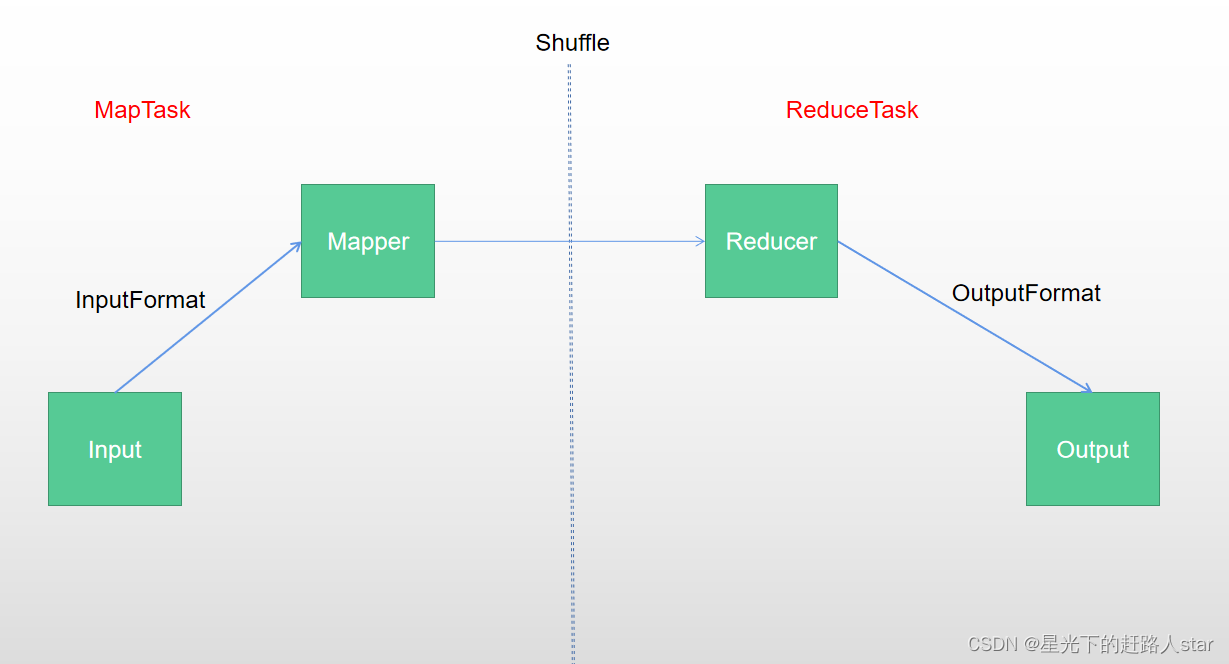
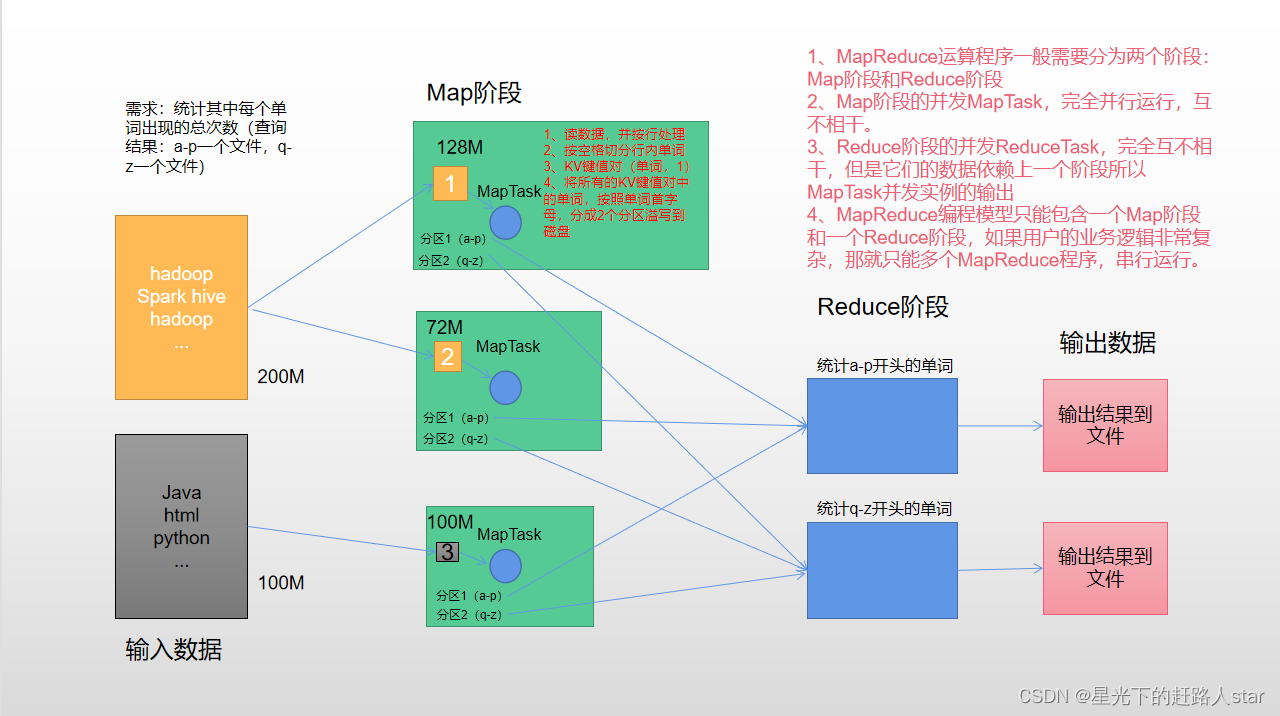
1、MapReduce概述1.1 MapReduce定义MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。1.2 MapReduce的优缺点1.2.1 优点1、易于编程它简单的实现一些接口,就可以完成一个分布式....
Hadoop生态系统中的数据处理技术:MapReduce的原理与应用
Hadoop生态系统是大数据处理的核心框架之一。在Hadoop生态系统中,MapReduce是一种常用的数据处理技术。本文将介绍MapReduce的原理和应用,并提供代码示例。 一、MapReduce的原理 MapReduce是一种分布式计算模型,用于处理大规模数据集。它的原理可以简单概括为“分而治之”。具体来说,MapReduce将数据分...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce您可能感兴趣
- mapreduce自定义
- mapreduce groupingcomparator
- mapreduce分组
- mapreduce pagerank
- mapreduce应用
- mapreduce算法
- mapreduce shuffle
- mapreduce区别
- mapreduce大规模
- mapreduce数据
- mapreduce集群
- mapreduce spark
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式
- mapreduce服务