Hadoop(HDFS+MapReduce+Hive+数仓基础概念)学习笔记(自用)
修改虚拟机IP复制网卡的配置第一种方式:配置文件向识别的网卡兼容1、 通过一个主机复制出多个主机2、 开启复制的主机,启动时选择“复制”3、 启动后查看IP ifconfig查看系统识别的网卡Ifconfig -a这里ifconfig看不到IP 是因为系统识别的设备名称与系统配置文件不同导致。配置文件名称解决方案:修改配置文件名为系统识别的名称(将eth0改为eth1)修改eth1内的配置保存退....
干翻Hadoop系列文章【03】:MapReduce概念详解
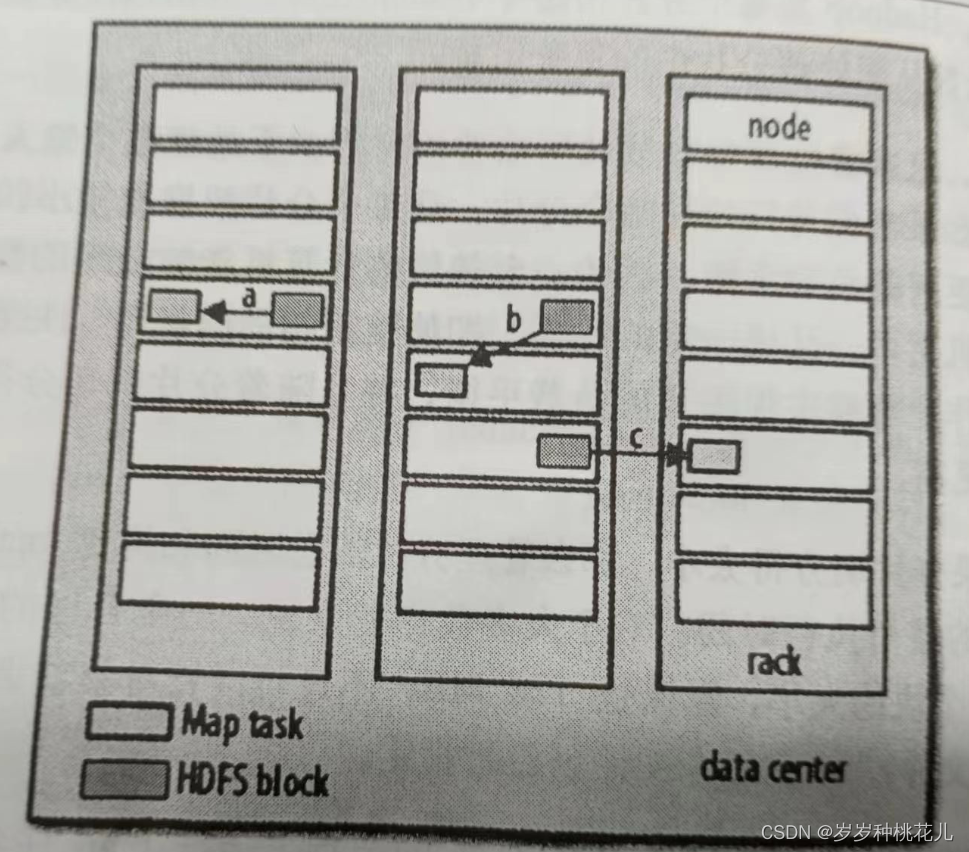
引言数据存储在分布式文件系统中HDFS里边,通过使用Hadoop资源管理系统YARN,Hadoop可以将MapReduce计算,转移到有存储部分的数据的各台机器上。一:概念和原理1:MapReduce作业MapReduce作业被称为一个工作单元。1:一个工作单元的逻辑组成元素:输入数据、MapReduce程序、配置信息。2:Hadoop将工作单元划分成多个任务(Task)任务有两类(Map和Re....
【大数据技术Hadoop+Spark】MapReduce之单词计数和倒排索引实战(附源码和数据集 超详细)
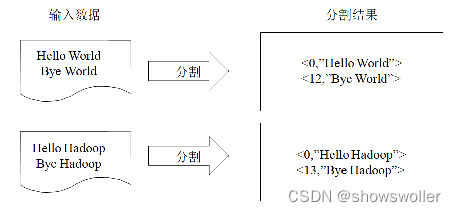
源码和数据集请点赞关注收藏后评论区留言私信~~~一、统计单词出现次数单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版“Hello World。其主要功能是统计一系列文本文件中每个单词出现的次数程序解析首先MapReduce将文件拆分成splits,由于测试用的文件较小,只有二行文字,所以每个文件为一个split,并将文件按行分割形成<key, va....
【大数据技术Hadoop+Spark】MapReduce概要、思想、编程模型组件、工作原理详解(超详细)
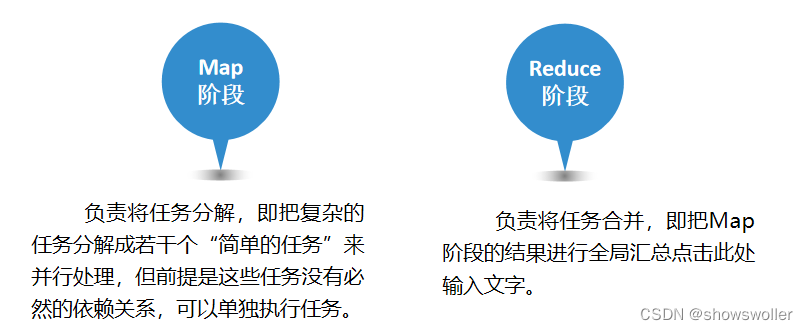
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。一、MapReduce核心思想MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结....
【云计算与大数据计算】Hadoop MapReduce实战之统计每个单词出现次数、单词平均长度、Grep(附源码 )
需要全部代码请点赞关注收藏后评论区留言私信~~~下面通过WordCount,WordMean等几个例子讲解MapReduce的实际应用,编程环境都是以Hadoop MapReduce为基础一、WordCountWordCount用于计算文件中每个单词出现的次数,非常适合采用MapReduce进行处理,处理单词计数问题的思路很简单,在 Map阶段处理每个文本split中的数据,产生<word....
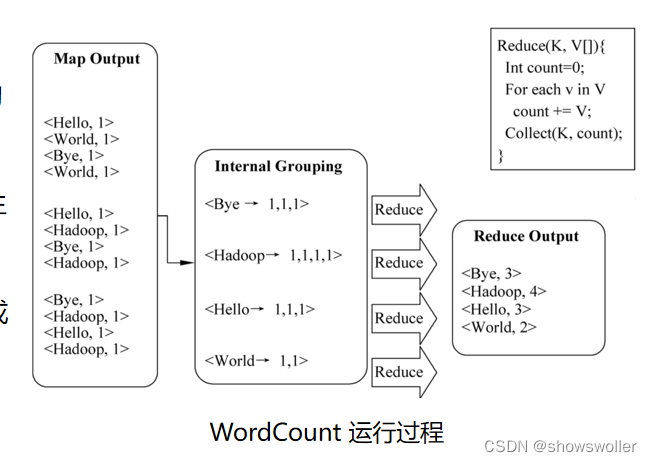
【云计算与大数据技术】Hadoop MapReduce的讲解(图文解释,超详细必看)
一、Hadoop MapReduce架构MapReduce 是一种分布式计算框架,能够处理大量数据 ,并提供容错 、可靠等功能 , 运行部署在大规模计算集群中,MapReduce计算框架采用主从架构,由 Client、JobTracker、TaskTracker组成Client的作用用户编写 MapReduce程序,通过Client提交到JobTrackerJobTracker的作用JobTra....
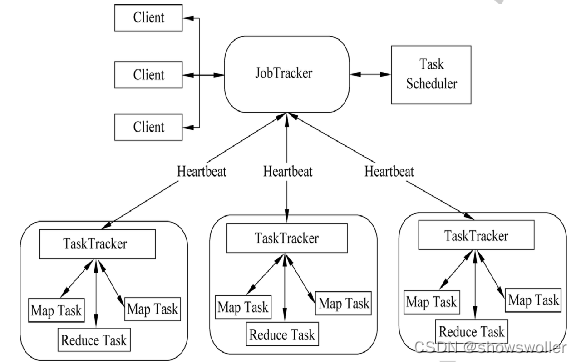
【云计算与大数据技术】大数据系统总体架构概述(Hadoop+MapReduce )
一、总体架构设计原则企业级大数据应用框架需要满足业务的需求,一是要求能够满足基于数据容量大,数据类型多,数据流通快的大数据基本处理需求,能够支持大数据的采集,存储,处理和分析,二是要能够满足企业级应用在可用性,可靠性,可扩展性,容错性,安全性和隐私性等方面的基本准则,三是要能够满足用原始技术和格式来实现数据分析的基本要求满足大数据的V3要求 大数据容量的加载、处理和分析 - 要求大数....
centos7 伪分布式 hadoop 利用 python 执行 mapreduce
阅读本文之前 需要先在 服务器端配置好 伪分布的 hadoop可以参考博主之前的文章!!!!先记录一下自己遇到的坑hadoop 找不到python安装python 后还需要在 py文件中添加#! python执行路径#!/usr/local/python3/Python-3.6.5/python3否则会出现很多莫名其妙的 bug!!!!hadoop 需要开启的端口不是一般的的多,,,所以在服务器....
阿里云E-MapReduce 还需要搭建Hadoop环境吗?
阿里云E-MapReduce flume通过jindosdk写入oss的话,还需要搭建Hadoop环境吗?
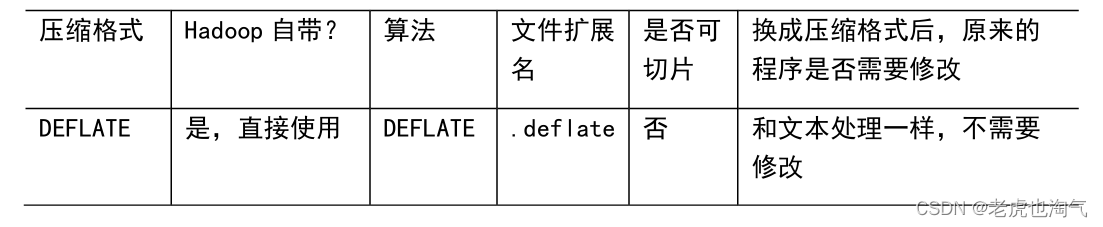
Hadoop学习:深入解析MapReduce的大数据魔力之数据压缩(四)
4.1 概述1)压缩的好处和坏处压缩的优点:以减少磁盘IO、减少磁盘存储空间。压缩的缺点:增加CPU开销。2)压缩原则(1)运算密集型的Job,少用压缩(2)IO密集型的Job,多用压缩4.2 MR 支持的压缩编码1)压缩算法对比介绍2)压缩性能的比较4.3 压缩方式选择压缩方式选择时重点考虑:压缩/解压缩速度、压缩率(压缩后存储大小)、压缩后是否可以支持切片。4.3.1 Gzip 压缩优点:压....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce您可能感兴趣
- mapreduce自定义
- mapreduce groupingcomparator
- mapreduce分组
- mapreduce pagerank
- mapreduce应用
- mapreduce算法
- mapreduce shuffle
- mapreduce区别
- mapreduce大规模
- mapreduce数据
- mapreduce集群
- mapreduce spark
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式
- mapreduce服务