
windows下使用Eclipse编译运行MapReduce程序 Hadoop2.6.0/Ubuntu
一、环境介绍 宿主机:windows8 虚拟机:Ubuntu14.04 hadoop2.6伪分布:搭建教程http://blog.csdn.net/gamer_gyt/article/details/46793731 Eclipse:eclipse-jee-luna-SR2-win32-x86_64 二、准备阶段 网上下载hadoop-eclipse-plugin-2.6.0.jar (点击下载....
Hadoop学习笔记(二):MapReduce的特性-计数器、排序
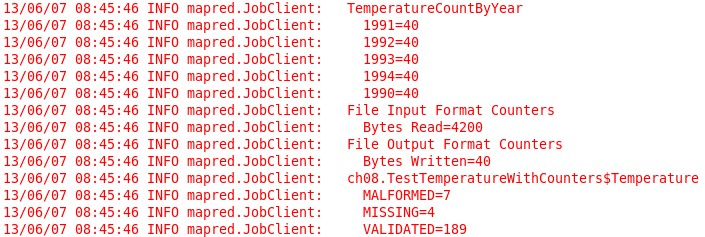
计数器 计数器是一种收集作业统计信息的有效手段,用于质量控制或应用级统计。说白了就是统计整个mr作业所有数据行中符合某个if条件的数量,(除某些内置计数器之外)。仅当一个作业执行成功之后,计数器的值才是完整可靠的。如果一个任务在作业执行期间失败,则相关计数器值会减小,计数器是全局的。 计数器...
Hadoop学习笔记(一):MapReduce的输入格式
Hadoop学习有一段时间了,但是缺乏练手的项目,老是学了又忘。想想该整理一个学习笔记啥的,这年头打字比写字方便。果断开博客,咩哈哈~~ 开场白结束(木有文艺细胞) 默认的MapReduce作业 import org.apache.hadoop.conf.Configuration; import org.apac...

从Hadoop框架与MapReduce模式中谈海量数据处理(含淘宝技术架构)
文章转载自: http://blog.csdn.net/v_july_v/article/details/670407 从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显兴奋,觉得它们很是神秘,而神秘的东西常能勾起我的兴趣,在看过介绍...
【案例】从hadoop框架与MapReduce模式中谈海量数据处理
首先申明,不是我原创,但是我看到比较不错的一片讲大数据分析处理的文章。谈到的阿里使用的云梯1,确实是使用的如下文的机制。但云梯1在阿里已经下线,目前使用的云梯2是用的ODPS的机制。技术架构和思路都可以参考和讨论。呵呵,特别是还有淘宝的数据魔方产品作为案例讲解,不错不错,就转了 第一部分、mapreduce模式与hadoop框架深入浅...
hadoop MapReduce示例
之前记录了hadoop的安装配置,今天记录以下hadoop+eclipse集成环境的配置,流程就不写了,主要记录一些问题。 1.首先要编译hadoop的eclipse插件,也可以直接到网上下hadoop-eclipse-plugin1.1.0.jar。然后将此包复制到eclipse的plugins文件夹下。 2.重启eclipse,选择Window->Preference->Hado....
[Hadoop系列]Hadoop的MapReduce中多文件输出
inkfish原创,请勿商业性质转载,转载请注明来源(http://blog.csdn.net/inkfish )。 Hadoop默认的输出是TextOutputFormat,输出文件名不可定制。hadoop 0.19.X中有一个org.apache.hadoop.mapred.lib.MultipleOutputFormat,可以输出多份文件且可以自定义文件名,但是从hadoop 0.....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce您可能感兴趣
- mapreduce自定义
- mapreduce groupingcomparator
- mapreduce分组
- mapreduce pagerank
- mapreduce应用
- mapreduce算法
- mapreduce shuffle
- mapreduce区别
- mapreduce大规模
- mapreduce数据
- mapreduce集群
- mapreduce spark
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式
- mapreduce服务
