E-MapReduce索引时MiddleManager提示找不到类com.hadoop.com...
E-MapReduce索引时MiddleManager提示找不到类com.hadoop.compression.lzo.LzoCodec
hadoop的mapreduce和mongodb的mapreduce有什么区别?
hadoop的mapreduce和mongodb的mapreduce有什么区别?
Hadoop MapReduce 调优参数
@[toc] 前言: 下列参数基于 hadoop v3.1.3 版本,共三台服务器,配置都为 4 核,4G 内存。 MapReduce 调优参数详解 这个参数定义了在 Reduce 阶段同时进行的拷贝操作的数量,用于从 Map 任务获取数据,增加此值可以加速 Shuffle 阶段的执行。 <prop...
Hadoop MapReduce计算框架
Hadoop MapReduce是一个使用简便的软件框架,它是Google云计算模型MapReduce的Java开源实现。基于这个框架写出来的应用程序能够运行在由上千万台普通机器组成的大型集群系统中,以可靠且容错的方式并行处理上T级别的数据集。 Hadoop MapReduce具有以下几个技术特点: 分布式处理:MapReduce将问题分解成独立的任务,并在多台计算机上并行处理,从而提高...

大数据实战——基于Hadoop的Mapreduce编程实践案例的设计与实现
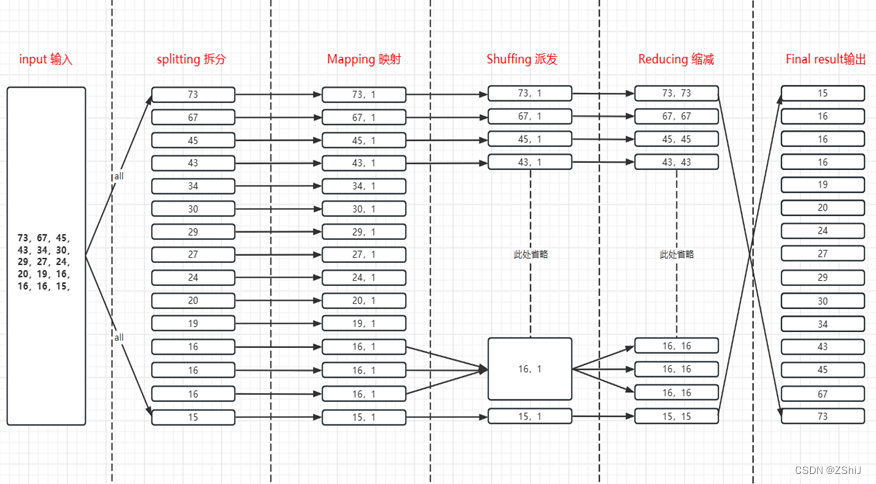
一、数据排序案例的设计与实现 1.1设计思路 图1:MaxCompute MapReduce各个阶段思路设计 设计思路分析分为六个模块:input输入数据、splitting拆分、Mapping映射、Shuf...
java与大数据:Hadoop与MapReduce
Hadoop和MapReduce是由Apache软件基金会开发和维护的开源项目。它们的出现主要是为了解决传统的数据处理工具无法处理大数据量的局限性。 首先,让我们深入了解一下Hadoop。Hadoop是一个分布式计算框架,旨在处理大规模数据集并提供可靠性和可扩展性。它由两个核心组件组成: Hadoop分布式文件系统(HDFS):HDFS是Hadoo...
Hadoop【基础知识 02】【分布式计算框架MapReduce核心概念+编程模型+combiner&partitioner+词频统计案例解析与进阶+作业的生命周期】(图片来源于网络)
1. 概述 同 HDFS 一样,Hadoop MapReduce 也采用了 Master/Slave(M/S)架构,具体如图所示。它主要由以下几个组件组成:Client、JobTracker、TaskTracker 和 Task。 下面分别对这几个组件进行介绍。 Client 我们将编写的 MapReduce 程序通过 Client 提交到 JobTracker 端;同时也可通过 Clie...

迁移Hadoop集群至DataLake集群
本文将详细阐述如何将您已有的旧版数据湖集群(Hadoop),高效地迁移至数据湖集群(DataLake),以下分别简称“旧集群”和“新集群”。迁移过程将充分考虑旧集群的版本、元数据类型以及存储方式,并针对这些因素,提供适应新集群的迁移策略与步骤。
Hadoop的JobTracker和TaskTracker在MapReduce中的作用是什么?
Hadoop的JobTracker和TaskTracker在MapReduce中的作用是什么?在Hadoop的MapReduce框架中,JobTracker和TaskTracker是两个关键组件,分别扮演着不同的角色。JobTracker:JobTracker是MapReduce的主要组件之一,负责协调和管理整个作业(Job)的执行过程。JobTracker接收客户端提交的作业请求,并将作业划分....
Hadoop系列 mapreduce 原理分析
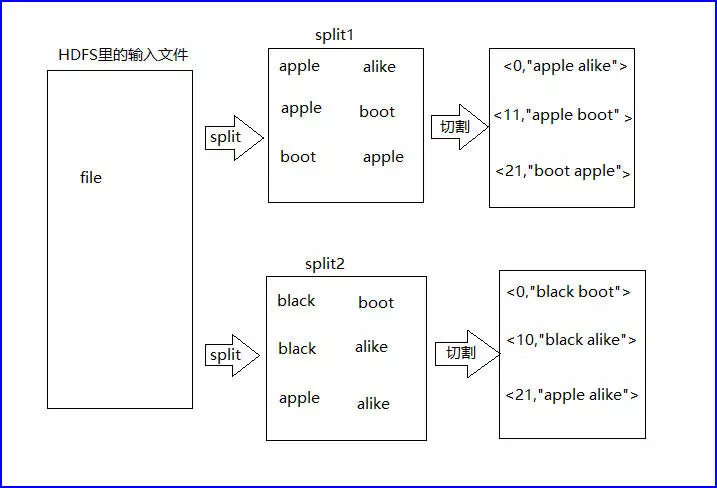
以wordcount 为例https://blog.csdn.net/weixin_43291055/article/details/106488839步骤一:split步骤二:map阶段步骤三:combine阶段(可选)---将同一台机器上的相同的数据进行合并,减少网络传输combiner其实也是一种reduce操作,因此我们看见WordCount类里是用reduce进行加载的。Combine....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce您可能感兴趣
- mapreduce自定义
- mapreduce groupingcomparator
- mapreduce分组
- mapreduce pagerank
- mapreduce应用
- mapreduce算法
- mapreduce shuffle
- mapreduce区别
- mapreduce大规模
- mapreduce数据
- mapreduce集群
- mapreduce spark
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式
- mapreduce服务