
hadoop YARN配置参数剖析—MapReduce相关参数
MapReduce相关配置参数分为两部分,分别是JobHistory Server和应用程序参数,Job History可运行在一个独立节点上,而应用程序参数则可存放在mapred-site.xml中作为默认参数,也可以在提交应用程序时单独指定,注意,如果用户指定了参数,将覆盖掉默认参数。 以下这些参数全部在mapred-site.xml中设置。 1. MapR...
hadoop之 node manager起不来, 执行mapreduce 程序hang住
现象: node manager起不来, 执行mapreduce 程序hang住 namenode 进程状态查询 [root@hadp-master sbin]# jps 8608 ResourceManager 8257 NameNode 9268 Jps 8453 SecondaryNameNode datanode 进程状态查询 , 发现 nodemanager 没有起来 [root@ha....
Hadoop中HDFS和MapReduce节点基本简介
Hadoop提供存储文件和分析文件的机制。 HDFS负责文件的存储,MapReduce负责文件的分析过程。 HDFS主要组件由NameNode和DataNode组成 HDFS文件切分成块(默认大小64M),以块为单位,每个块有多个副本存储在不同的机器上,副本数可在文件生成时指定(默认3) NameNode是主节点,存储文件的元数据如文件名,文...
【问题】spark运行python写的mapreduce任务,hadoop平台报错,java.net.ConnectException: 连接超时
问题: 用spark-submit以yarn-client方式提交任务,在集群的某些节点上的任务出现连接超时的错误,排查过各种情况后,确定在防火墙配置上出现问题。 原因: 我猜测是python程序启动后,作为Server,hadoop中资源调度是以java程序作为Client端访问, Python启动的Server端需要接受localhost的client访问。 当你从一台linux主机向自身发....
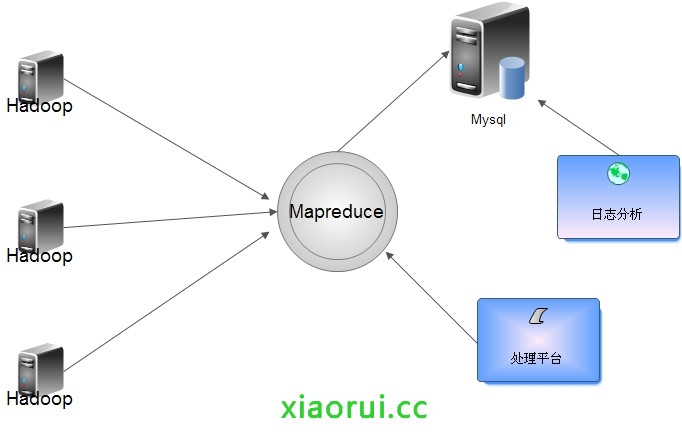
使用python构建基于hadoop的mapreduce日志分析平台
出处:http://rfyiamcool.blog.51cto.com/1030776/1340057 流量比较大的日志要是直接写入Hadoop对Namenode负载过大,所以入库前合并,可以把各个节点的日志凑并成一个文件写入HDFS。 根据情况定期合成,写入到hdfs里面。 咱们看看日志的大小,200G的dns日志...
Hadoop MapReduce编程 API入门系列之计数器(二十七)
MapReduce 计数器是什么? 计数器是用来记录job的执行进度和状态的。它的作用可以理解为日志。我们可以在程序的某个位置插入计数器,记录数据或者进度的变化情况。 MapReduce 计数器能做什么? M...

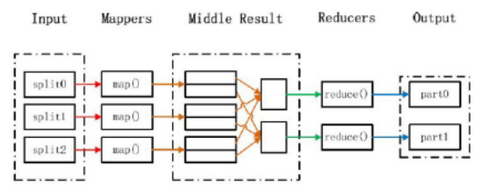
Hadoop的MapReduce执行流程图
Hadoop的MapReduce shuffle过程,非常重要。只有熟悉整个过程才能对业务了如指掌。 MapReduce执行流程 输入和拆分: 不属于map和reduce的主要过程,但属于整个计算框架消耗时间的一部分,该部分会为正式的map准备数据。 分片(split)操作: split只是将源文件的内容分片形成一...
Hadoop MapReduce概念学习系列之map并发任务数和reduce并发任务数的原理和代码实现(十八)
首先,来说的是,reduce并发任务数,默认是1。 即,在jps后,出现一个yarnchild。之后又消失。 这里,我控制reduce并发任务数6。 有多少个reduce的并发任务数可以在程序里控制,但有多少个map的并发任务数还没...
Spark 概念学习系列之Spark相比Hadoop MapReduce的特点(二)
Spark相比Hadoop MapReduce的特点 (1)中间结果输出 基于MapReduce的计算引擎通常会将中间结果输出到磁盘上,进行存储和容错。 出于任务管道承接的考虑,当一些查询翻译到MapReduce任务时,往往会产生多个Stage,而这些串联的Stage又依赖于底层文件系统(如HDFS)来存储每...
E-MapReduce Hadoop Streaming是什么?
python 写hadoop streaming作业 mapper代码如下 #!/usr/bin/env pythonimport sysfor line in sys.stdin: line = line.strip() words = line.split() &nbs...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce您可能感兴趣
- mapreduce自定义
- mapreduce groupingcomparator
- mapreduce分组
- mapreduce pagerank
- mapreduce应用
- mapreduce算法
- mapreduce shuffle
- mapreduce区别
- mapreduce大规模
- mapreduce数据
- mapreduce集群
- mapreduce spark
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式
- mapreduce服务