
Hadoop专业解决方案-第3章:MapReduce处理数据
前言:非常感谢团队的努力,最新的章节终于有了成果,因为自己的懒惰,好久没有最新的进展了,感谢群里兄弟的努力。 群名称是Hadoop专业解决方案群 313702010 本章主要内容: 理解MapReduce基本原理 了解MapReduce应用的执行 理解MapReduce应用的设计 截止到目前,我们已经知道Hadoop如何存储数据,但Hadoop不仅仅是一个高可用 的,规模巨大的数据存储...
【云计算 Hadoop】Hadoop 版本 生态圈 MapReduce模型(二)
3. Reduce 数据流Reduce任务 : map 任务的数量要远远多于 Reduce 任务;-- 无本地化优势 : Reduce 的任务的输入是 Map 任务的输出, reduce 任务的绝大多数数据 本地是没有的;-- 数据合并 : map 任务 输出的结果, 会通过网络传到 reduce 任务节点上, 先进行数据的合并, 然后在输入到reduce 任务中进行处理;-- 结果输出 : r....
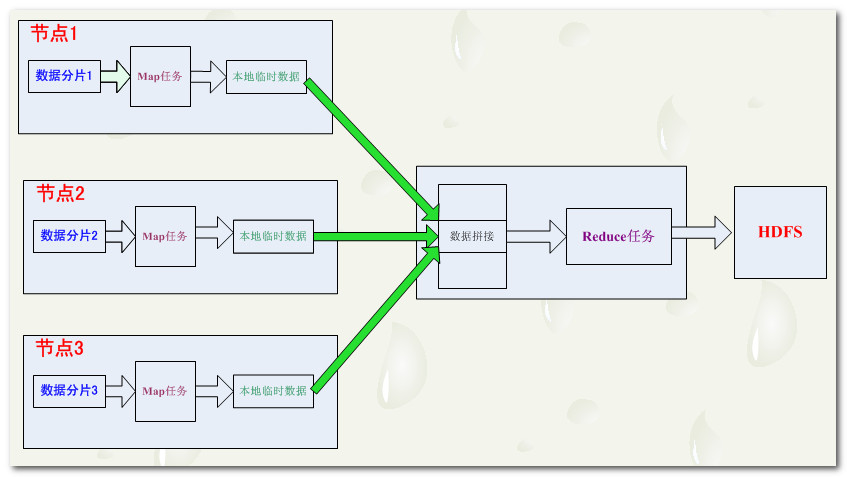
【云计算 Hadoop】Hadoop 版本 生态圈 MapReduce模型(一)
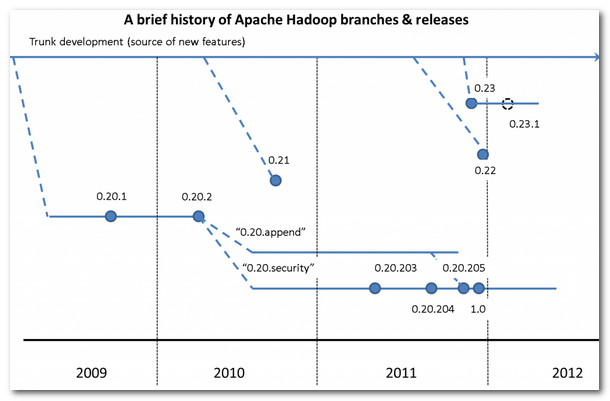
一 Hadoop版本 和 生态圈1. Hadoop版本(1) Apache Hadoop版本介绍Apache的开源项目开发流程 : -- 主干分支 : 新功能都是在 主干分支(trunk)上开发;-- 特性独有分支 : 很多新特性稳定性很差, 或者不完善, 在这些分支的独有特定很完善之后, 该分支就会并入主干分支;-- 候选分支 : 定期从主干分支剥离, 一般候选分支发布, 该分支就会停止更新新....
有什么方法可以解决Hadoop MapReduce和早期Spark在shuffle过程中的问题?
有什么方法可以解决Hadoop MapReduce和早期Spark在shuffle过程中的问题?
Hadoop中批hdfs的MapReduce启动与停止的相关命令以及使用方法分别是什么?
Hadoop中批hdfs的MapReduce启动与停止的相关命令以及使用方法分别是什么?
Hadoop中通过InputFormat,Mapreduce框架可以做到什么?
Hadoop中通过InputFormat,Mapreduce框架可以做到什么?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce您可能感兴趣
- mapreduce自定义
- mapreduce groupingcomparator
- mapreduce分组
- mapreduce pagerank
- mapreduce应用
- mapreduce算法
- mapreduce shuffle
- mapreduce区别
- mapreduce大规模
- mapreduce数据
- mapreduce集群
- mapreduce spark
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式
- mapreduce服务
