
Spark 与 MapReduce 的 Shuffle 的区别?
park 和 MapReduce 在 Shuffle 过程中有一些重要的区别。以下是它们的主要区别: 1. 执行模型 MapReduce:MapReduce 是一个两阶段的执行模型,包括 Map 阶段和 Reduce 阶段。在 Map 阶段,数据被处理并生成中间键值对;在 Reduce 阶段,这些键值对被聚合和处理。 Spark:Spark 使用基于内存的执...
【底层服务/编程功底系列】「大数据算法体系」带你深入分析MapReduce算法 — Shuffle的执行过程
Shuffle是什么 Shuffle作为MapReduce的核心步骤,扮演着重要的角色。对于深入理解MapReduce,对Shuffle的了解至关重要。然而,我发现在阅读相关资料时常常感到困惑,很难理清逻辑,反而越读越迷糊。最近,我为了进行MapReduce作业性能调优,不得不深入研究代码以了解Shuffle的运行机制。 Shuffle这个词通常意味着洗牌或弄乱,对于Java A...
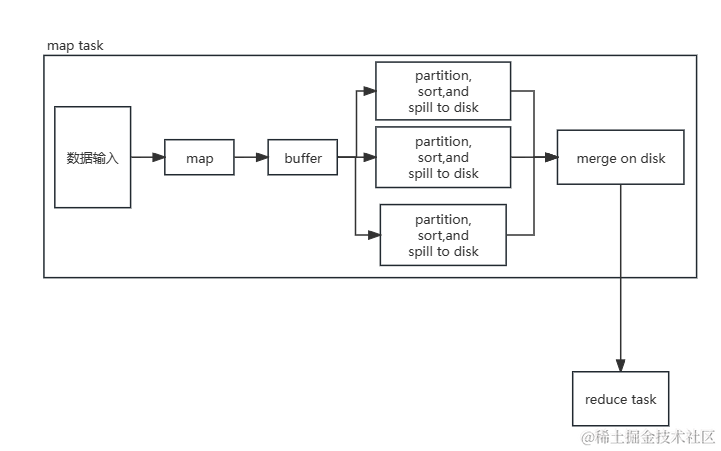
MapReduce中的Shuffle过程是什么?为什么它在性能上很关键?
MapReduce中的Shuffle过程是什么?为什么它在性能上很关键?在MapReduce中,Shuffle过程是指将Map函数的输出结果按照key进行分组和排序,然后将相同key的数据对传递给Reduce函数进行处理的过程。Shuffle过程在性能上非常关键,因为它决定了Reduce函数能够获取到正确的数据,以及数据的分布是否均衡。下面我将通过一个具体的案例来解释Shuffle过程的具体步骤....
MapReduce计数器,Tash的运行机制,shuffle过程,压缩算法
MapReduce当中的计数器计数器是收集作业统计信息的有效手段之一,用于质量控制或应用级统计。计数器还可辅助诊断系统故障。如果需要将日志信息传输到map 或reduce 任务, 更好的方法通常是看能否用一个计数器值来记录某一特定事件的发生。对于大型分布式作业而言,使用计数器更为方便。除了因为获取计数器值比输出日志更方便,还有根据计数器值统计特定事件的发生次数要比分析一堆日志文件容易得多。had....

25 MAPREDUCE的shuffle机制
概述mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle;shuffle: 洗牌、发牌——(核心机制:数据分区,排序,缓存);具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;主要流程Shuffle缓存流程:shuffle是MR处理....

MapReduce 的 shuffle 阶段【重要】
Map 阶段负责数据的过滤分发,将原始数据转化为键值对;Reduce 阶段是对数据进行合并,将具有相同的 key 值的 value 进行处理后再输出新的键值对作为最终结果。为了让 Reduce 可以并行处理 Map 的结果,必须对 Map 的输出进行一定的分区排序,然后再交给对应的 Reduce。(1)即 Map 方法之后 Reduce 方法之前的这段数据混洗的过程叫做 Shuffle 机制。(....
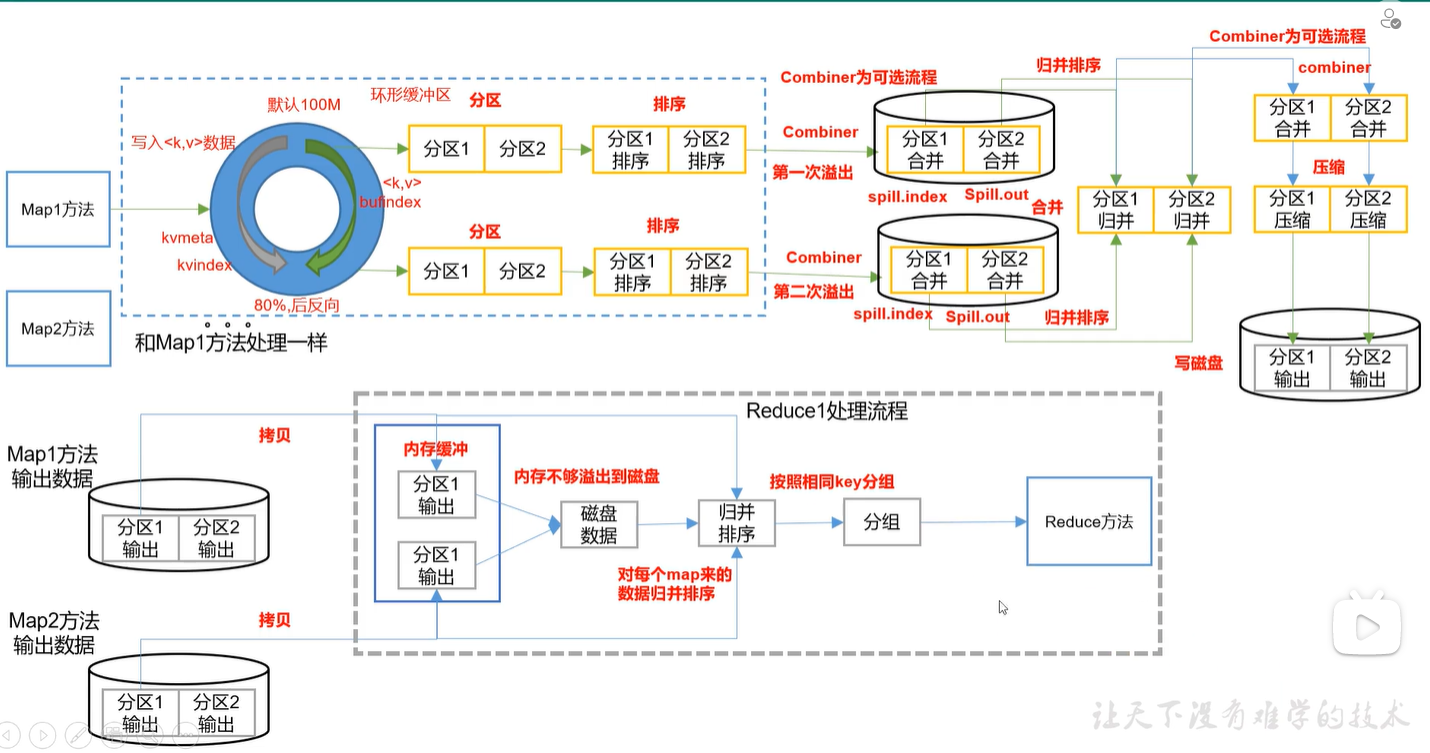
Hadoop知识点总结——MapReduce的Shuffle
Hadoop学习之路(二十三)MapReduce中的shuffle详解 <= 以下内容出自该博客 从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程,如图所示:Spill过程Spill过程包括输出、排序、溢写、合并等步骤,如图所示:Collect每个Map....
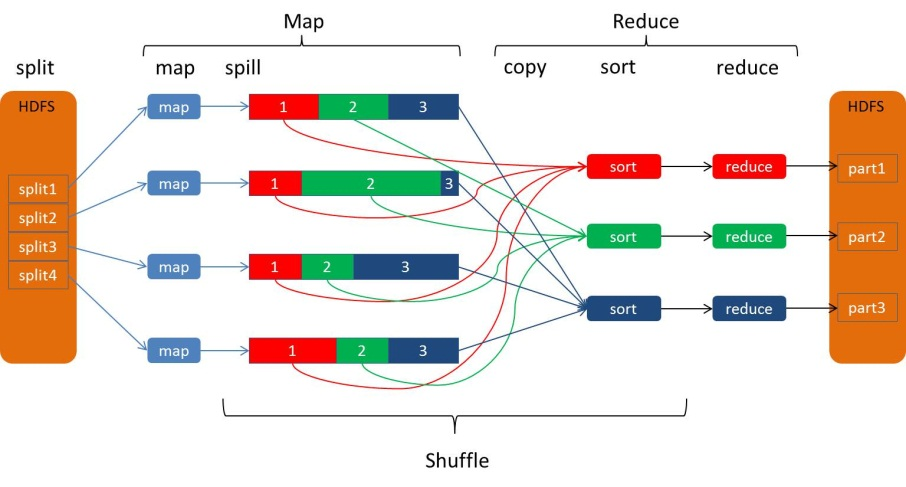
Hadoop中的MapReduce框架原理、Shuffle机制、Partition分区、自定义Partitioner步骤、在Job驱动中,设置自定义Partitioner、Partition 分区案例
13.MapReduce框架原理13.2MapReduce工作流程上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件(3)多个溢出文件会被合并成大的溢出文件(4)在溢出过程及合并的....
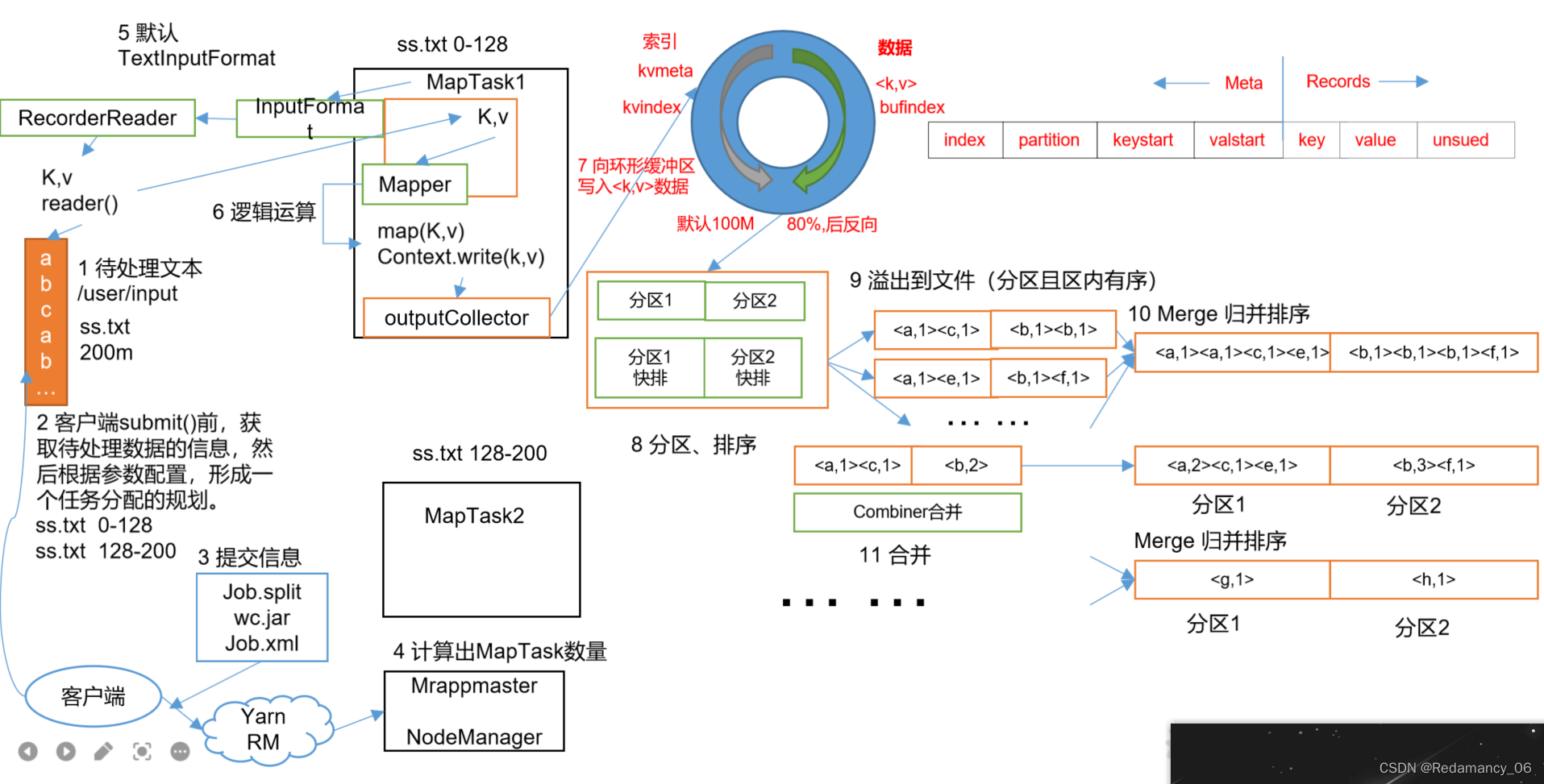
MapReduce shuffle过程详解!
一、MR的shuffle过程MR的shuffle过程:input -> map -> shuffle -> reduce ->outputMR的原理图:二、Map shuffle1.map()的数据会写入到内存(环形缓冲区:默认大小:100mb),当数据达到缓冲区总容量的80%(阈值)时,会将我们的数据spill到本地磁盘1)分区(partitioner):...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
mapreduce您可能感兴趣
- mapreduce区别
- mapreduce大规模
- mapreduce数据
- mapreduce列表
- mapreduce集群
- mapreduce聚合
- mapreduce可视化
- mapreduce driver
- mapreduce序列化
- mapreduce日志
- mapreduce hadoop
- mapreduce spark
- mapreduce编程
- mapreduce报错
- mapreduce hdfs
- mapreduce作业
- mapreduce任务
- mapreduce maxcompute
- mapreduce配置
- mapreduce运行
- mapreduce yarn
- mapreduce程序
- mapreduce hive
- mapreduce文件
- mapreduce oss
- mapreduce节点
- mapreduce版本
- mapreduce优化
- mapreduce模式
- mapreduce服务