
使用WebTracking收集网站、小程序端用户的浏览器、浏览行为记录、停留时间等日志
如果您需要收集和分析用户在浏览器、小程序上的信息,例如用户的浏览器、浏览行为记录、购买行为记录、停留时间,可以使用WebTracking功能。只需对业务代码进行较少的改动,例如在前端页面中添加追踪像素或集成JavaScript SDK,就可以将用户行为信息上传到日志服务的Logstore中。
使用浏览器浏览网页时发生了什么?
写的很简单,后续会不断补充完善 我们打开一个浏览器,在地址栏输入正确的URL,例如http://www.baidu.com 按下回车,浏览器开始解析这个URL, 并使用socket库提供的gethostbyname查询域名对应的ip, 而调用gethostbyname用到了协议栈向DNS服务器进行通信,返回查询到的ip 有了...
还有这种骚操作:使用Golang实现无头浏览器浏览和截图
前言在Web开发中,有时需要对网页进行截图,以便进行页面预览、测试等操作。而使用无头浏览器来实现截图功能,可以避免手动操作的繁琐和不稳定性。这篇文章将介绍:使用Golang进行无头浏览器的截图,轻松实现页面预览、测试和模拟用户操作。有趣这篇文章发完,有朋友在朋友圈留言说:没想到还有这种骚操作~还有朋友思路打开了:问我能不能自动实现移动滑块识别验证、能不能实现自动登录?什么是无头浏览器无头浏览器(....
我FC搭建的flask服务,浏览器打开默认是下载,怎么设置成是 浏览器浏览?
我FC搭建的flask服务,浏览器打开默认是下载,怎么设置成是 浏览器浏览?
在上传文件后,返回的文件url在浏览器打开默认会下载;如何变为直接在浏览器浏览?
看了这个文档管理文件元信息,不是很明白如何操作。 尝试了在上传时设置headers为 headers: { 'Content-Disposition': 'inline', 'x-oss-meta-Content-Disposition': 'inline', 'x-oss-meta-content-disposition': 'inl...
我们设计的RPA流程跑一段时间后,图形验证码识别通过率断崖式下降,需要清理浏览器浏览数据后才能恢复正
我们设计的RPA流程跑一段时间后,图形验证码识别通过率断崖式下降,需要清理浏览器浏览数据后才能恢复正常 请问在RPA中如何清理浏览数据?
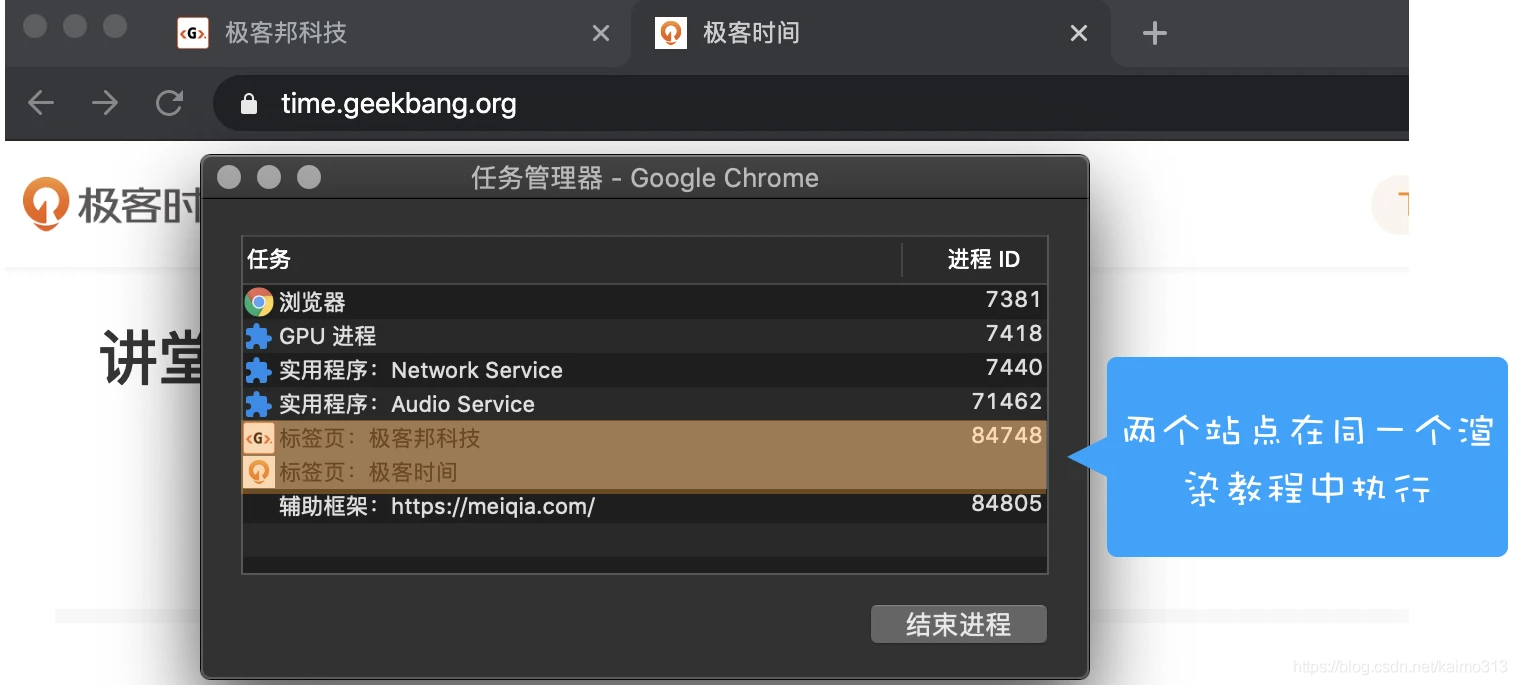
浏览器原理 36 # 浏览上下文组:如何计算Chrome中渲染进程的个数?
说明浏览器工作原理与实践专栏学习笔记前言在默认情况下,如果打开一个标签页,那么浏览器会默认为其创建一个渲染进程。如果从一个标签页中打开了另一个新标签页,当新标签页和当前标签页属于同一站点(相同协议、相同根域名)的话,那么新标签页会复用当前标签页的渲染进程。多个标签页运行在同一个渲染进程:从标签页中打开新的标签页多个标签页运行在不同的渲染进程中:新建一个标签页打开标签页之间的连接可以通过 wind....
百度浏览器内核太低,浏览京东有问题
柳鲲鹏 因为百度网盘的原因,吾平常多使用百度浏览器。近来用在逛京东的时候,发现一个奇怪的事情: 用着极速模式,打开京东一个网页,总是强制变成 IE兼容模式。不得不点击模式按钮再切换回来。麻烦的是,浏览器本身又不能设置模式。而且有提示如下: 今天打开购物车的时候,发现了网页底部有如下内容(红框标出): 这有点意思了。猜测: 百度浏览器内核....

Java:打开系统默认浏览器浏览指定的URL
JDK >= 6 package com.demo.desktop; import java.awt.Desktop; import java.io.IOException; import java.net.URI; /** * 打开系统默认浏览器浏览指定的URL */ public class Demo { public static void main(String[] a...
使用python获取浏览器收藏夹和历史浏览记录,然后可以...
在电脑上浏览个网页,都要用到浏览器,当你打开网页的那一刻,浏览器就会记录你的浏览信息,这些信息可能就是你的信息泄露的根源。下面看看如何使用python获取一下历史浏览记录;以chrome浏览器为例:找到浏览器数据存放位置数据存放位置一般都是固定的,基本都在以下位置C:\Users\Administrator\AppData\Local\Google\Chrome\User Data\Defaul....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。