
DataWorks中EMR Serverless Spark空间流程的环境准备
本教程以用户画像为例,在华东2(上海)地域演示如何使用DataWorks完成数据同步、数据加工和质量监控的全流程操作。为了确保您能够顺利完成本教程,您需要准备教程所需的 EMR Serverless Spark空间、DataWorks工作空间,并进行相关的环境配置。
用户画像分析案例环境准备-基于新版数据开发和Spark计算资源
本教程以用户画像为例,在华东2(上海)地域演示如何使用DataWorks完成数据同步、数据加工和质量监控的全流程操作。为了确保您能够顺利完成本教程,您需要准备教程所需的EMR Serverless Spark空间、DataWorks工作空间,并进行相关的环境配置。
用户画像分析案例环境准备-基于新版数据开发和EMR计算资源
本教程以用户画像分析为例,演示如何使用DataWorks完成数据同步、数据加工和质量监控的全流程操作。为确保您能够顺利完成本教程,请准备好所需的EMR集群、DataWorks工作空间,并完成相关的环境配置。
用户画像分析案例环境准备-基于新版数据开发和StarRocks计算资源
本教程以用户画像为例,在华东2(上海)地域演示如何使用DataWorks完成数据同步、数据加工和质量监控的全流程操作。为了确保您能够顺利完成本教程,您需要准备教程所需的EMR Serverless StarRocks集群、DataWorks工作空间,并进行相关的环境配置。
用户画像分析案例环境准备-基于新版数据开发和MaxCompute计算资源
本教程以构建用户画像为例,基于DataWorks预先提供的原始数据集,指导您在DataWorks 华东2(上海)地域完成数据同步、加工及质量监控全流程操作。请提前准备MaxCompute项目、DataWorks工作空间,并配置好数据源、计算及存储资源。
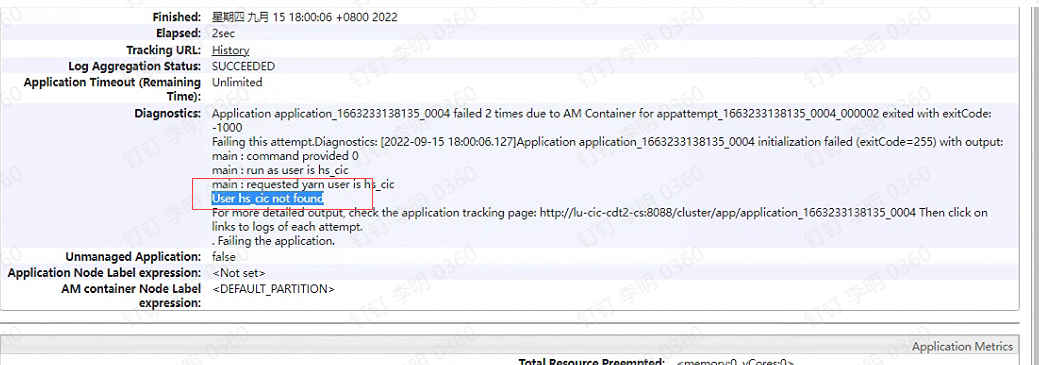
开启 Kerberos 安全的大数据环境中,Yarn Container 启动失败导致作业失败
大数据问题排查系列 - 开启 Kerberos 安全的大数据环境中,Yarn Container 启动失败导致 spark/hive 作业失败前言大家好,我是明哥!最近在若干个不同客户现场,都遇到了 大数据集群中开启 Kerberos 后,spark/hive 作业提交到YARN 后,因 YARN Container 启动失败作业无法执行的情况,在此总结下背后的知识点,跟大家分享下,希望大家有所....
大数据平台搭建(容器环境)——Spark3.X on Yarn安装配置
Spark3.X on Yarn安装配置 一、解压 1. 将Spark包解压到路径/opt/module路径中 tar -zxvf /opt/software/spark-3.1.1-bin-hadoop3.2.tgz -C /opt/module/ 2. 改名(可不做) mv spark-3.1.1-bin-hadoop3.2/ spark-3.1.1-yarn 二、配置 1....
大数据平台搭建(容器环境)——Flink on Yarn安装配置
Flink on Yarn安装配置 一、解压 1. 将Flink包解压到路径/opt/module路径中 tar -zxvf /opt/software/flink-1.14.0-bin-scala_2.12.tgz -C /opt/module/ 2. 改名(可不做) mv flink-1.14.0/ flink-yarn 二、配置 1.修改环境配置变量 vi /etc/pro...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute环境相关内容
- 云原生大数据计算服务 MaxCompute环境策略
- 环境云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute maxcompute环境配置
- 云原生大数据计算服务 MaxCompute maxcompute环境
- 云原生大数据计算服务 MaxCompute dev环境
- 云原生大数据计算服务 MaxCompute部署环境
- 云原生大数据计算服务 MaxCompute安装环境
- 云原生大数据计算服务 MaxCompute环境开发
- kerberos云原生大数据计算服务 MaxCompute环境
- 云原生大数据计算服务 MaxCompute组件环境
- 云原生大数据计算服务 MaxCompute环境hbase安装
- 云原生大数据计算服务 MaxCompute环境kafka
- 环境云原生大数据计算服务 MaxCompute引擎
- 云原生大数据计算服务 MaxCompute伪分布环境部署
- 云原生大数据计算服务 MaxCompute环境datax
- 云原生大数据计算服务 MaxCompute环境jdk
- mac构建云原生大数据计算服务 MaxCompute伪分布环境
- 云原生大数据计算服务 MaxCompute环境sqoop
- 云原生大数据计算服务 MaxCompute环境研究
- 云原生大数据计算服务 MaxCompute环境方法
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute电子
- 云原生大数据计算服务 MaxCompute伦理
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute决策
- 云原生大数据计算服务 MaxCompute契机
- 云原生大数据计算服务 MaxCompute企业
- 云原生大数据计算服务 MaxCompute版本
- 云原生大数据计算服务 MaxCompute挖掘
- 云原生大数据计算服务 MaxCompute机器学习
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute平台
