
【CUDA学习笔记】第四篇:线程以及线程同步(附案例代码下载方式)(二)
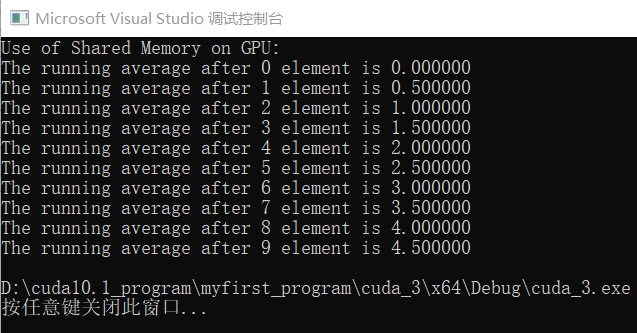
3、线程同步3.1、共享内存 共享内存位于芯片内部,因此它比全局内存快得多。(CUDA里面存储器的快慢有两方面,一个是延迟低,一个是带宽大。这里特指延迟低),相比没有经过缓存的全局内存访问,共享内存大约在延迟上低100倍。同一个块中的线程可以访问相同的一段共享内存(注意:不同块中的线程所见到的共享内存中的内容是不相同的),这在许多线程需要与其他线程共享它们的结果的应用程....
【CUDA学习笔记】第四篇:线程以及线程同步(附案例代码下载方式)(一)
1、CUDA线程 CUDA关于并行执行具有分层结构。每次内核启动时可以被切分成多个并行执行的块,而每个块又可以进一步地被切分成多个线程。 在上一推文我们已经知道,maxThreadPerBlock属性限制了每个块能启动的线程数量。这个值对于最新的GPU卡来说是1024。类似地,第二种方式能最大启动的块数量被限制成2^31-1个。 ....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。