
PyTorch CUDA内存管理优化:深度理解GPU资源分配与缓存机制
在深度学习工程实践中,当训练大型模型或处理大规模数据集时,上述错误信息对许多开发者而言已不陌生。这是众所周知的 CUDA out of memory 错误——当GPU尝试为张量分配空间而内存不足时发生。这种情况尤为令人沮丧,特别是在已投入大量时间优化模型和代码后遭遇此类问题。 torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to ...
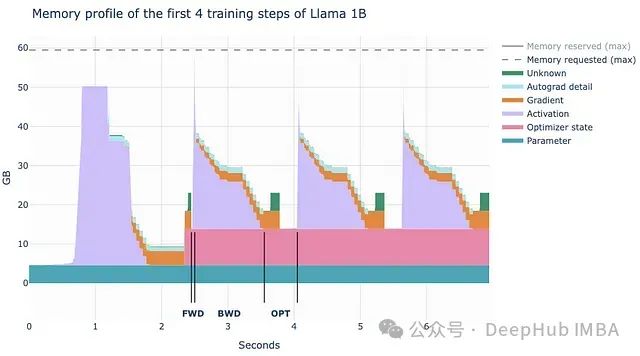
PyTorch Profiler 性能优化示例:定位 TorchMetrics 收集瓶颈,提高 GPU 利用率
指标收集是每个机器学习项目不可或缺的组成部分,它使我们能够跟踪模型性能并监控训练进度。理想情况下,我们希望在不给训练过程带来额外开销的前提下收集和计算指标。与训练循环的其他部分一样,低效的指标计算可能会引入不必要的开销,延长训练步骤的耗时,并增加训练成本。 本文是将聚焦于指标收集,演示指标收集的一种简单实现如何对运行时性能产生负面影响,并探讨用于分析和优化它的工具与技术。 为了实现指标收集,我们....

在Linux系统GPU实例中使用PyTorch时,出现“undefined symbol: __nvJitLinkAddData_12_1, version libnvJitLink.so.12”报错
在Linux系统GPU实例中,可能会因为GPU实例所安装的CUDA版本与PyTorch版本不兼容,导致使用PyTorch时出现报错现象,本文介绍这种情况的解决方案。
【Pytorch】查看GPU是否可用
使用pytorch,可以使用如下语句查询GPU是否可用: import torch print(torch.__version__) # 查看torch当前版本号 print(torch.version.cuda) # 编译当前版本的torch使用的cuda版本号 print(torch.cuda.is_available()) # 查看当前cuda是否可...
【从零开始学习深度学习】20. Pytorch中如何让参数与模型在GPU上进行计算
前言 之前我们一直在使用CPU计算。对复杂的神经网络和大规模的数据来说,使用CPU来计算可能不够高效。本文我们将介绍如何使用单块NVIDIA GPU来计算。所以需要确保已经安装好了PyTorch GPU版本。准备工作都完成后,下面就可以通过nvidia-smi命令来查看显卡信息了。 ...
如果要用gpu的版本直接安装pytorch是gpu的,ModelScope默认也是gpu的吗?
如果要用gpu的版本直接安装pytorch是gpu的,ModelScope默认也是gpu的吗?
Anaconda+Cuda+Cudnn+Pytorch(GPU版)+Pycharm+Win11深度学习环境配置
一、准备工作 个人电脑配置:RTX4060 win11 个人配置版本:cuda(11.7)+ pytorch(2.0.1) + python(3.9) 所需工具: 1、python集成开发环境:Anaconda 2、CUDA、cuDNN:英伟达提供的针对英伟达显卡的运算平台。用来提升神经网络的运行效率,如果电脑显卡不满足要求也是可以不用安装,使用cpu来进...

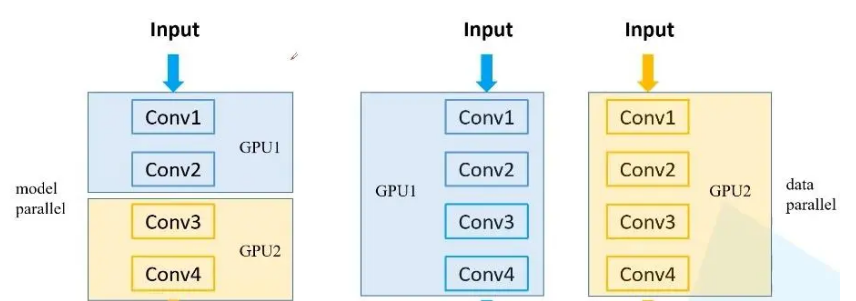
【多GPU炼丹-绝对有用】PyTorch多GPU并行训练:深度解析与实战代码指南
a. 数据拆分,模型不拆分 b. 数据不拆分,模型拆分 c. 数据拆分,模型拆分 在深度学习的炼丹之路上,多GPU的使用如同助燃剂,能够极大地加速模型的训练和测试。根据不同的GPU数量和内存配置,我们可以选择多种策略来充分利用这些资源。今天,我们将围绕“多GPU炼丹”这一主题,深度解析PyTorch多GPU并行训练的技巧,并为大家带来实战代码指南。在这个过程中,我们将不断探讨和展示如何...
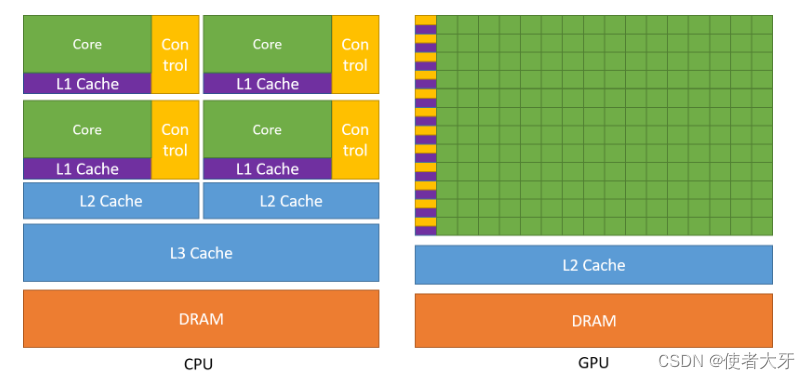
【PyTorch&TensorBoard实战】GPU与CPU的计算速度对比(附代码)
0. 前言 按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。 本文基于PyTorch通过tensor点积所需要的时间来对比GPU与CPU的计算速度,并介绍tensorboard的使用方法。 我在前面的科普文章——GPU如何成为AI的...
【AMP实操】解放你的GPU运行内存!在pytorch中使用自动混合精度训练
前言 自动混合精度(Automatic Mixed Precision,简称AMP)是一种深度学习加速技术,它通过在训练过程中自动选择合适的数值类型(如半精度浮点数和单精度浮点数)来加速计算,并减少内存占用,从而提高训练速度和模型性能。 精度 半精度 半精度浮点数(Half-Precision Floating Point)是一种浮点数数据类型,也被称为1...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
pytorch gpu相关内容
pytorch您可能感兴趣
- pytorch l2
- pytorch代码
- pytorch解析
- pytorch技术
- pytorch图像
- pytorch gat
- pytorch昇腾
- pytorch gemotric
- pytorch vggnet
- pytorch interest
- pytorch模型
- pytorch神经网络
- pytorch教程
- pytorch实战
- pytorch训练
- pytorch学习
- pytorch数据集
- pytorch tensorflow
- pytorch官方教程
- pytorch安装
- pytorch卷积
- pytorch构建
- pytorch卷积神经网络
- pytorch分类
- pytorch数据
- pytorch源码
- pytorch框架
- pytorch案例
- pytorch学习笔记
- pytorch版本
