
分布式爬虫框架Scrapy-Redis实战指南
引言 在当今数字化的时代背景下,互联网技术的蓬勃兴起极大地改变了旅游酒店业的运营模式与市场格局。作为旅游产业链中的关键一环,酒店业的兴衰与互联网技术的应用程度紧密相连。分布式爬虫技术,尤其是基于 Scrapy 框架的 Scrapy-Redis 扩展,为酒店业的数据采集与分析开辟了新的途径。本次实战聚焦于利用 Scrapy-Redis 采集携程机票平台上国内热门城市酒店价格和评价信息,旨在通过分析....

聚焦Python分布式爬虫必学框架Scrapy打造搜索引擎
CSS选择器 XPath的用法一、选取节点常用的路劲表达式:表达式描述实例 nodename选取nodename节点的所有子节点xpath(‘//div’)选取了div节点的所有子节点/从根节点选取xpath(‘/div’)从根节点上选取div节点//选取所有的当前节点,不考虑他们的位置xpath(‘//div’)选取所有的div节点.选取当前节点xpath(....
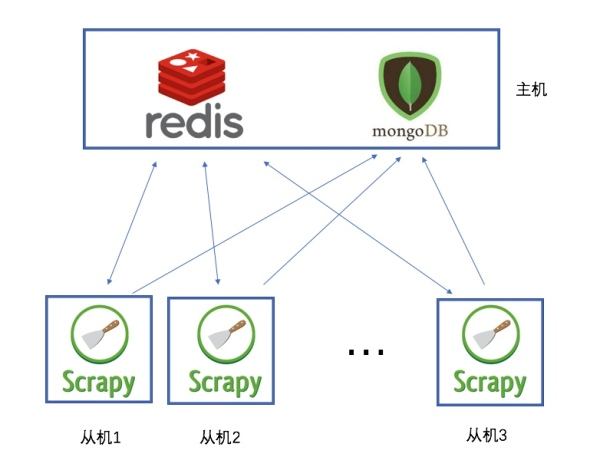
在阿里云Centos7.6上面部署基于redis的分布式爬虫scrapy-redis
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取。但是当我们要爬取的页面非常多的时候,单个服务器的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来。 而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(Sc.....
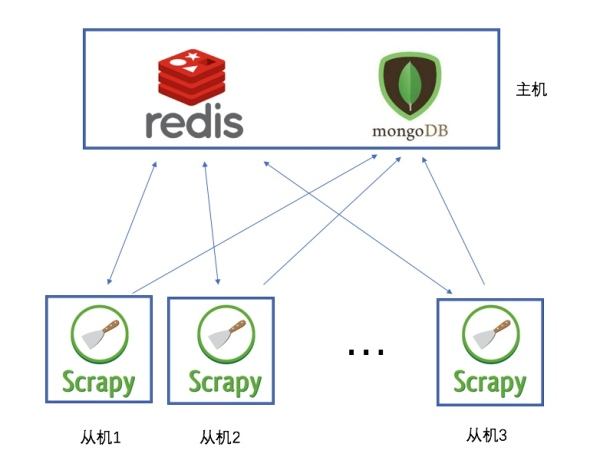
阿里云Centos7.6上面部署基于redis的分布式爬虫scrapy-redis将任务队列push进redis
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取。但是当我们要爬取的页面非常多的时候,单个服务器的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来。 而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(Sch....
24、Python快速开发分布式搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
【百度云搜索:http://www.lqkweb.com】 【搜网盘:http://www.swpan.cn】 1、基本概念 2、反爬虫的目的 3、爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图

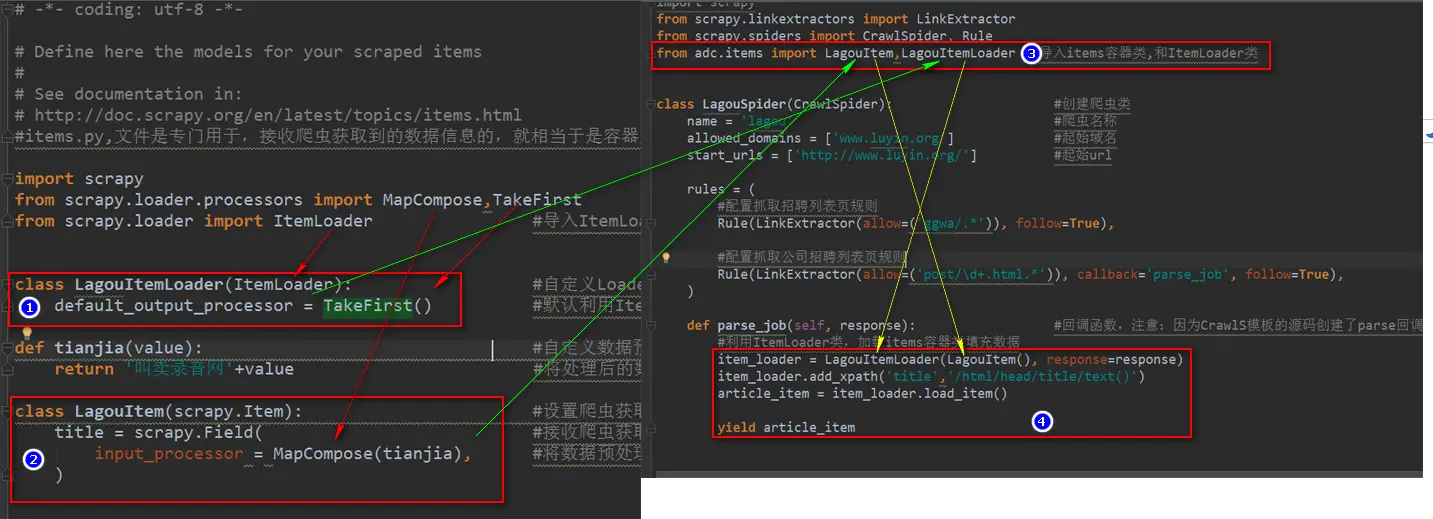
23、 Python快速开发分布式搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
转: http://www.bdyss.cn http://www.swpan.cn 用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates:母版说明 basic 创建基础爬虫文件 crawl ...
22、Python快速开发分布式搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
转自: http://www.bdyss.cn http://www.swpan.cn 第一步。首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://github.com/muchrooms/zheye 注意:此程序依赖以下模块包 Keras==2.0.1 Pillow==3.4.2 jupyter==1.0.0 matplotlib==1.5.3 numpy==1.....
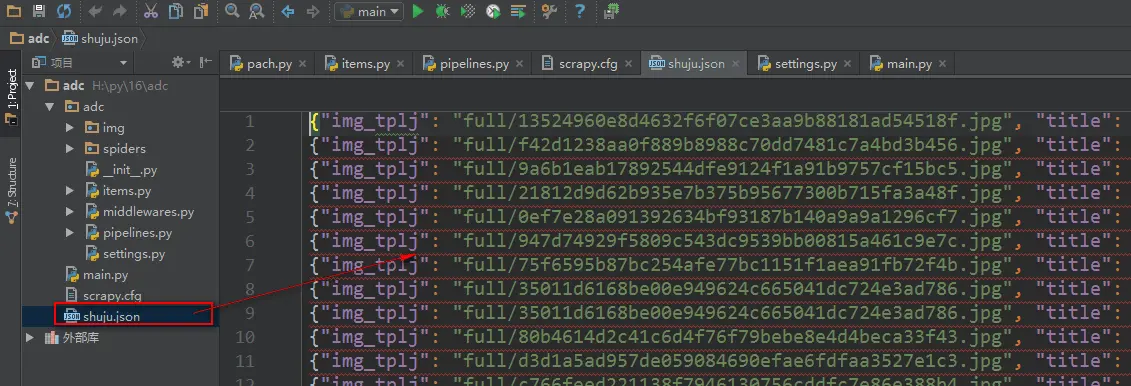
21、 Python快速开发分布式搜索引擎Scrapy精讲—爬虫数据保存
注意:数据保存的操作都是在pipelines.py文件里操作的 将数据保存为json文件 spider是一个信号检测 # -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to&nbs...
20、 Python快速开发分布式搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
编写spiders爬虫文件循环抓取内容 Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数, 参数: url='url' callback=页面处理函数 使用时需要yield Request() parse.urljoin()方法,是urllib库下的方法,是自动url拼接,如果第二个参数的url地址是相对路径会自动与第一个参数拼接 # -*- ...
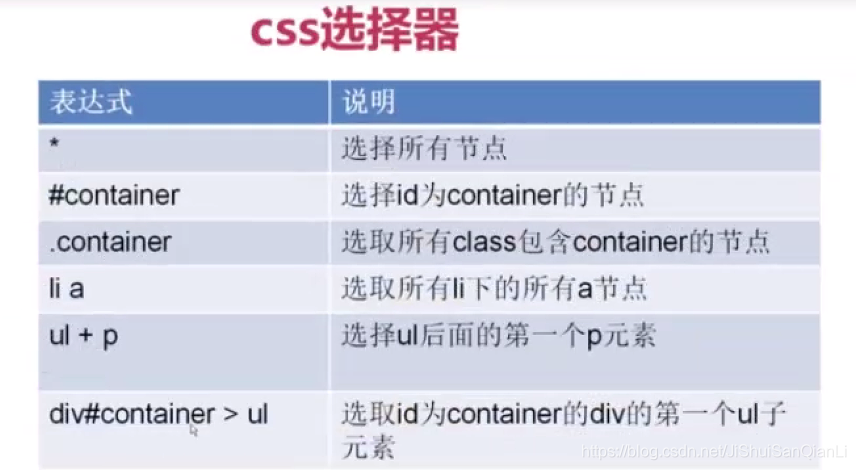
19、 Python快速开发分布式搜索引擎Scrapy精讲—css选择器
css选择器 1、 2、 3、 ::attr()获取元素属性,css选择器 ::text获取标签文本 举例: extract_first('')获取过滤后的数据,返回字符串,有一个默认参数,也就是如果没有数据默认是什么,一般我们设置为空字符串 extract()获取过滤后的数据,返回字符串列表 # -*- coding: utf-8 -*- im...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注