
flink cdc写hdfs文件的时候,如果开启文件合并的话,最终的文件不能通过hive映射读取吗?
flink cdc写hdfs文件的时候,文件格式设置为parquet,压缩方式为GZIP,如果开启文件合并的话,最终的文件不能通过hive映射读取,这个怎么解决啊?
Flink CDC里flinksql写hive一直包这个错误,报错怎么办?
Caused by: org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'hive' that implements 'org.apache.flink.table.planner.delegation.ParserFactory' in the classpath.....
Flink CDC + Hudi + Hive + Presto构建实时数据湖最佳实践
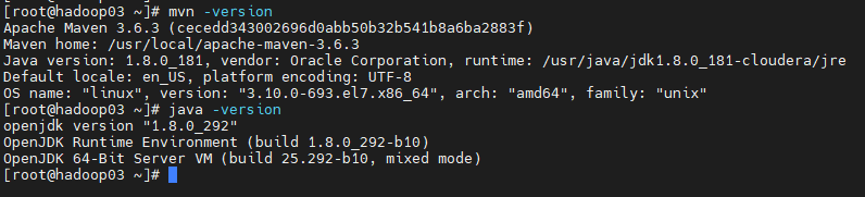
1. 测试过程环境版本说明 Flink1.13.1 Scala2.11 CDH6.2.0 Hadoop3.0.0 Hive2.1.1 Hudi0.10(master) PrestoDB0.256 Mysql5.7 2. 集群服务器基础环境 2.1 Maven和JDK环境版本 ...
Flink CDC同步到hudi 可以直接读取hudi 的数据吗 例如用hive 或者spark?
Flink CDC同步到hudi 可以直接读取hudi 的数据吗 例如用hive 或者spark?
Flink CDC里我现在想postgresql 能实时入库 hive,并且能实现断点续传,怎么办?
Flink CDC里我现在想postgresql 能实时入库 hive,并且能实现断点续传,有什么好的建议吗?
Flink CDC里从mysql读数据写到hive报这个错,大家有什么解决方法吗?
Flink CDC里从mysql读数据写到hive报这个错,大家有什么解决方法吗?mysql-cdc的版本是2.3.0,
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。