
大数据-90 Spark 集群 RDD 编程-高阶 RDD容错机制、RDD的分区、自定义分区器(Scala编写)、RDD创建方式(一)
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-90 Spark 集群 RDD 编程-高阶 RDD容错机制、RDD的分区、自定义分区器(Scala编写)、RDD创建方式(二)
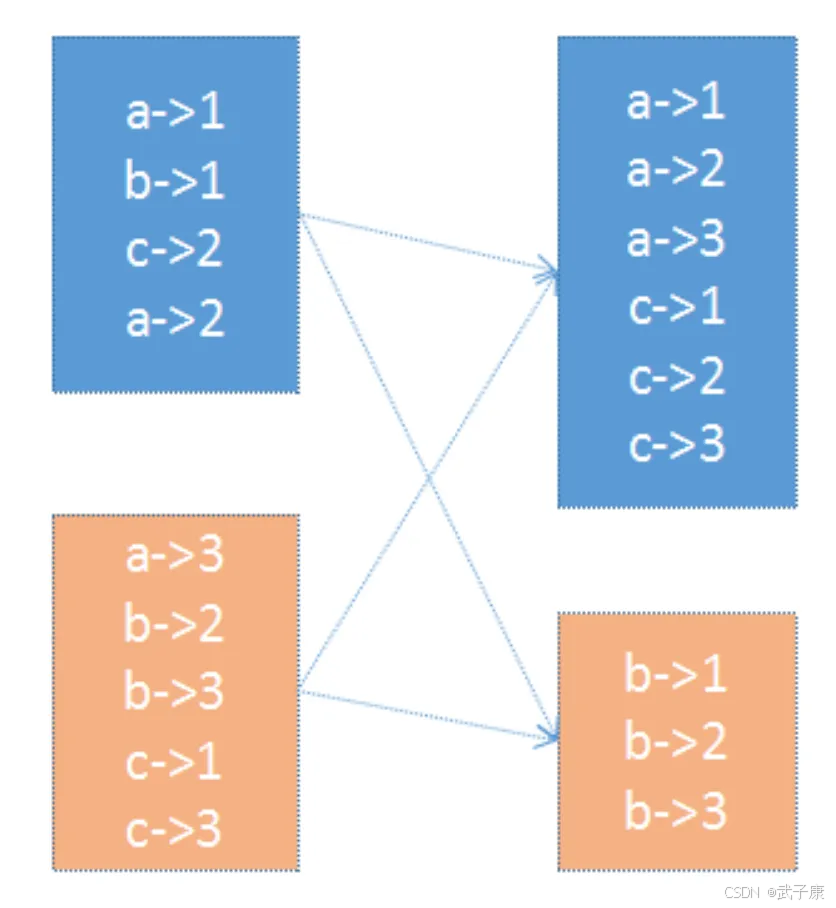
接上篇:https://developer.aliyun.com/article/1622537?spm=a2c6h.13148508.setting.20.27ab4f0eUI7v7p 分区器作用与分类 在PairRDD(key,value)中,很多操作都是基于Key的,系统会按照Key对数据进行重组,如 GroupByKey 数据重组需要规则,最常见的就是基于Hash...
Spark学习--day04、RDD依赖关系、RDD持久化、RDD分区器、RDD文件读取与保存
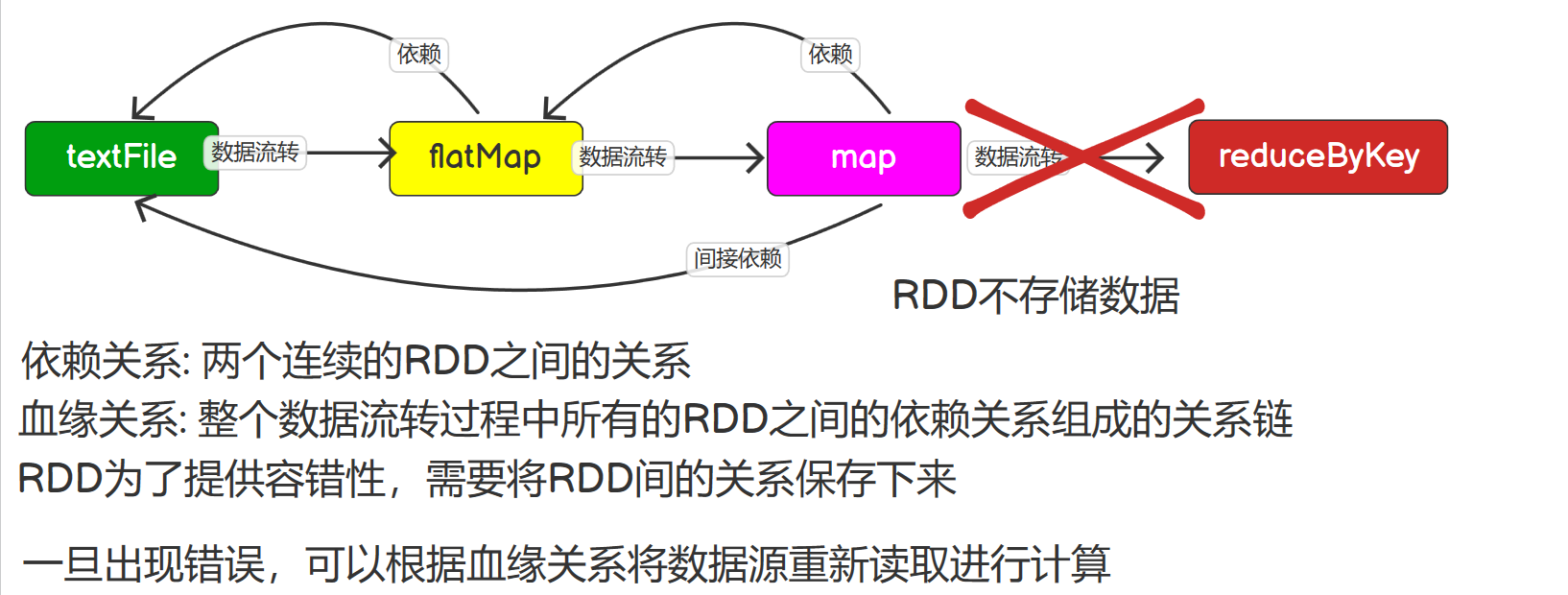
RDD依赖关系 查看血缘关系 RDD只支持粗粒度转换,每一个转换操作都是对上游RDD的元素执行函数f得到一个新的RDD,所以RDD之间就会形成类似流水线的前后依赖关系。 将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算丢失的RDD的...
Spark学习---day03、Spark核心编程(RDD概述、RDD编程(创建、分区规则、转换算子、Action算子))(二)
Action行动算子 行动算子是触发了整个作业的执行。因为转换算子都是懒加载,并不会立即执行。 创建包名:com.zhm.spark.operator.action 1)reduce 聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据 packa...

Spark学习---day02、Spark核心编程(RDD概述、RDD编程(创建、分区规则、转换算子、Action算子))(一)
前言 Spark计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是: RDD : 弹性分布式数据集 累加器:分布式共享只写变量 广播变量:分布式共享只读变量 接下来我们一起看看这三大数据结构是如何在数据处理中使用的。...
Spark学习---day02、Spark核心编程(RDD概述、RDD编程(创建、分区规则、转换算子、Action算子))(一)
前言 Spark计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是: RDD : 弹性分布式数据集 累加器:分布式共享只写变量 广播变量:分布式共享只读变量 接下来我们一起看看这三大数据结构是如何在数据处理中使用的。...
Spark RDD分区和数据分布:优化大数据处理
在大规模数据处理中,Spark是一个强大的工具,但要确保性能达到最优,需要深入了解RDD分区和数据分布。本文将深入探讨什么是Spark RDD分区,以及如何优化数据分布以提高Spark应用程序的性能。 什么是RDD分区? 在Spark中,RDD(弹性分布式数据集)是数据处理的核心抽象,而RDD的分区是Spark中的重要概念之一。分区是将RDD的数据划分成多个逻辑块的方式,每个分区都包含数据的...

Spark学习--4、键值对RDD数据分区、累加器、广播变量、SparkCore实战(Top10热门品类)
一、键值对RDD数据分区Spark目前支持Hash分区、Range分区和用户自定义分区。Hash分区为当前默认的分区。分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle后进入哪个分区和Reduce的个数。1、注意:(1)只有Key-Value类型的RDD才有分区器,非Key-Value类型的RDD分区器的值是None。(2)每个RDD的分区ID范围:0~(numPartiti....

Spark学习---2、SparkCore(RDD概述、RDD编程(创建、分区规则、转换算子、Action算子))(二)
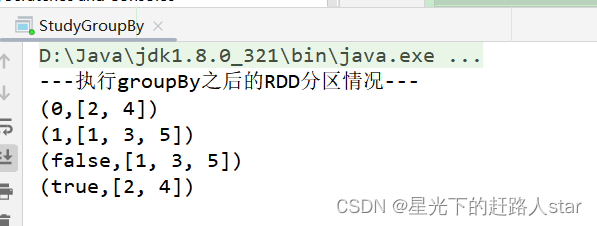
2.3.1.4 groupBy()分组1、用法:groupBy(f) ,以元素为粒度对每个元素执行函数f。2、函数f:(1)函数f为用户自定义实现内容,返回值任意(2) 函数返回值为算子groupBy返回值的key,元素为value。(3)算子groupBy的返回值为新的重新分区的K—V类型RDD3、功能说明:分组,按照传入函数的返回值进行分组。将相同的key对应的值放入一个迭代器。4、案例说明....
Spark学习---2、SparkCore(RDD概述、RDD编程(创建、分区规则、转换算子、Action算子))(一)
1、RDD概述1.1 什么是RDDRDD(Resilient Distributed Dataset)叫弹性分布式数据集,是Spark中对于分布式数据集的抽象。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。1.2 RDD五大特性1、一组分区,即是数据集的基本组成单位,标记数据是哪个分区的2、一个计算每个分区的函数3、RDD之间的依赖关系4、一个Partitio....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache sparkrdd相关内容
- apache spark rdd依赖
- apache spark集群rdd
- apache spark文件rdd
- 大数据apache spark rdd
- apache spark dataframe rdd
- apache spark rdd容错机制
- apache spark rdd编程分区
- apache spark rdd累加
- apache spark集群rdd编程
- apache spark集群rdd编程优化
- apache spark原理rdd
- apache spark rdd优化
- apache spark rdd变量
- apache spark RDD持久化
- apache spark RDD编程
- apache spark rdd文件
- apache spark rdd简介
- apache spark rdd rdd-transformation
- apache spark rdd区别
- apache spark rdd flatmap
- apache spark学习rdd依赖持久化
- apache spark编程rdd分区action
- apache spark rdd概述
- apache spark学习rdd
- apache spark学习rdd分区
- apache spark rdd action
- apache spark rdd分区规则
- apache spark rdd算子
- apache spark学习RDD算子
- apache spark rdd分区优化
apache spark更多rdd相关
- apache spark RDD操作
- apache spark精进rdd算子
- apache spark rdd map
- apache spark rdd实战
- apache spark rdd编程案例
- apache spark rdd函数
- apache spark rdd编程action
- apache spark rdd属性
- apache spark rdd dataframe区别
- apache spark rdd学习笔记
- apache spark rdd方法
- apache spark rdd学习
- apache spark rdd概念学习
- apache spark rdd作用是什么
- apache spark rdd方法作用是什么
- apache spark rdd容错
- apache spark rdd编程入门
- apache spark rdd func方法作用是什么
- apache spark RDD特性
- apache spark rdd core
- apache spark rdd特点
- apache spark rdd关系
- apache spark初次学习rdd笔记
- apache spark rdd宽依赖
- apache spark rdd弹性
- apache spark rdd groupbykey
- apache spark rdd saveastextfile
- apache spark RDD依赖关系
- apache spark rdd scala
- apache spark rdd应用
apache spark您可能感兴趣
- apache spark技术
- apache spark大数据
- apache spark优先级
- apache spark batch
- apache spark客户端
- apache spark任务
- apache spark调度
- apache spark yarn
- apache spark作业
- apache spark Hive
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark应用
- apache spark实战
- apache spark操作
- apache spark程序
- apache spark报错
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注