
实时计算 Flink版产品使用合集之部署yarn模式,怎么实现峰谷动态并行度扩容缩容
问题一:filnk-operator 不用强制在服务器上在搞一个jdk11 版本吧? filnk-operator 不用强制在服务器上在搞一个jdk11 版本吧。 我现在用k8s 上安装了operator1.6 版本,我的flink 任务也正常跑起来了啊。 有大佬知道吗?, 还是说 代码里面调 flink-operator-api的时候需要使用jdk11 参考...
实时计算 Flink版产品使用合集之1.13版本上部署一个flink1.17为什么任务启动一直accepted状态yarn的,有什么排查方向吗资源什么的都是充足的
问题一:yarn上不能部署两个不同版本的flink客户端吗? yarn上不能部署两个不同版本的flink客户端吗? 这个状态一直这样 参考回答: YARN上确实不能同时部署两个不同版本的Fl...

在部署flink ha时,为什么yarn-session启动时会提示认证失败?
在部署flink ha时,zookeeper服务没有配置认证,为什么yarn-session启动时会提示认证失败?有人遇到过吗这个报错好像不影响启动运行,我看web界面还是存在的。
Flink--day02、Flink部署(Yarn集群搭建下的会话模式部署、单作业模式部署、应用模式部署)
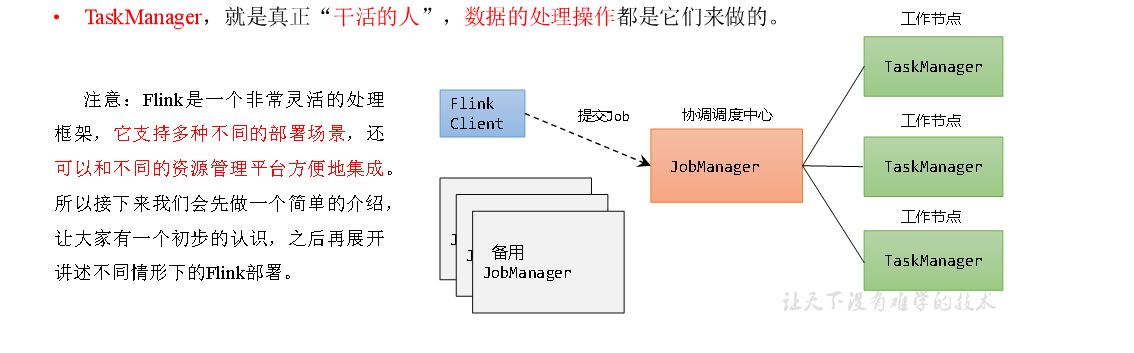
1、Flink部署 1.1 集群角色 Flink提交作业和执行任务,需要几个关键组件: 客户端(Client):代码由客户端获取并做转换,之后提交给JobManager JobManager就是Flink集群里的“管事人”,对作业进行中央调度管理,而它获取到要执行的作业后,会进一步处理转换,然后分发给众多的TaskManager。 Ta...
Spark学习--1、Spark入门(Spark概述、Spark部署、Local模式、Standalone模式、Yarn模式)(一)
1、Spark概述 1.1 什么是Spark Spark是一个基于内存的快速、通用、可扩展的大数据分析计算引擎。 spark基于内存的快速、通用、可扩展的大数据分析计算引擎,是基于内存的,通过DAG(有向无环图)执行引擎支持无环数据流 弹性分布式数据集(RDD)...

想请教下 部署flink集群的话 Standalone模式 Yarn模式 模式用哪个模式好一点?
想请教下 部署flink集群的话 Standalone模式 Yarn模式 Kubernetes模式用哪个模式好一点?另外需要安装zookeeper来实现高可用么?
Hadoop【部署 02】hadoop-3.1.3 单机版YARN(配置、启动停止shell脚本修改及服务验证)
1. 修改配置进入 ${HADOOP_HOME}/etc/hadoop/ 目录下,修改以下配置:mapred-site.xml[root@tcloud ~]# vim /usr/local/hadoop-3.1.3/etc/hadoop/mapred-site.xml<configuration> <property> <name>mapreduce....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
阿里巴巴终端技术
阿里巴巴终端技术最新内容汇聚在此,由阿里巴巴终端委员会官方运营。阿里巴巴终端委员会是阿里集团面向前端、客户端的虚拟技术组织。我们的愿景是着眼用户体验前沿、技术创新引领业界,将面向未来,制定技术策略和目标并落地执行,推动终端技术发展,帮助工程师成长,打造顶级的终端体验。同时我们运营着阿里巴巴终端域的官方公众号:阿里巴巴终端技术,欢迎关注。
+关注