
Node Labels调度实践
Node Labels是YARN提供的节点分区功能,使得YARN在调度时能够在物理层面上对不同类型的作业进行有效隔离。本文为您介绍如何根据您的业务类型和节点类型创建相应的Node Labels。
基于Delta Table构建近实时增全量一体化链路实践
面对当前日益复杂且对数据时效性要求极高的近实时业务场景,MaxCompute基于Delta Table推出了集大规模存储、高效批量处理和近实时能力于一体的近实时增量一体化架构。本文为您介绍该架构的工作原理及其优势。
MaxCompute+DLF+OSS湖仓一体的湖查询和湖数据入仓实践
MaxCompute、DLF和OSS是阿里云提供的一体化解决方案,可以实现数据湖查询和湖数据入仓。通过配置DLF,将数据从OSS导入到MaxCompute中,并使用MaxCompute进行数据湖查询。该方案可以方便地进行数据分析和处理,并保证数据的可靠性和安全性。
MaxCompute近实时数仓数据入仓介绍
为满足业务对数据仓库中高度时效性数据的需求,MaxCompute基于Delta Table实现了分钟级近实时数据写入和主键更新功能,显著提升了数据仓库的数据更新效率。
镜像管理场景实践
MaxCompute提供用户自定义函数(UDF)及Python(PyODPS和MaxFrame)开发能力,本文为您介绍如何在MaxCompute UDF、PyODPS及MaxFrame作业开发中使用镜像。
六、【计算】大数据Shuffle原理与实践(下) | 青训营笔记
引言学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。 热爱写作,愿意让自己成为更好的人............铭记于心✨我唯一知道的,便是我一无所知✨四、Push Shuffle0 概述为什么需要Push Shuffle,因为一般shuffle过程存在不可避免的问题:数据存储在本地磁盘,没有备份IO 并发:大量 RPC 请求(M*R)IO 吞吐:随机读、写放大(3....
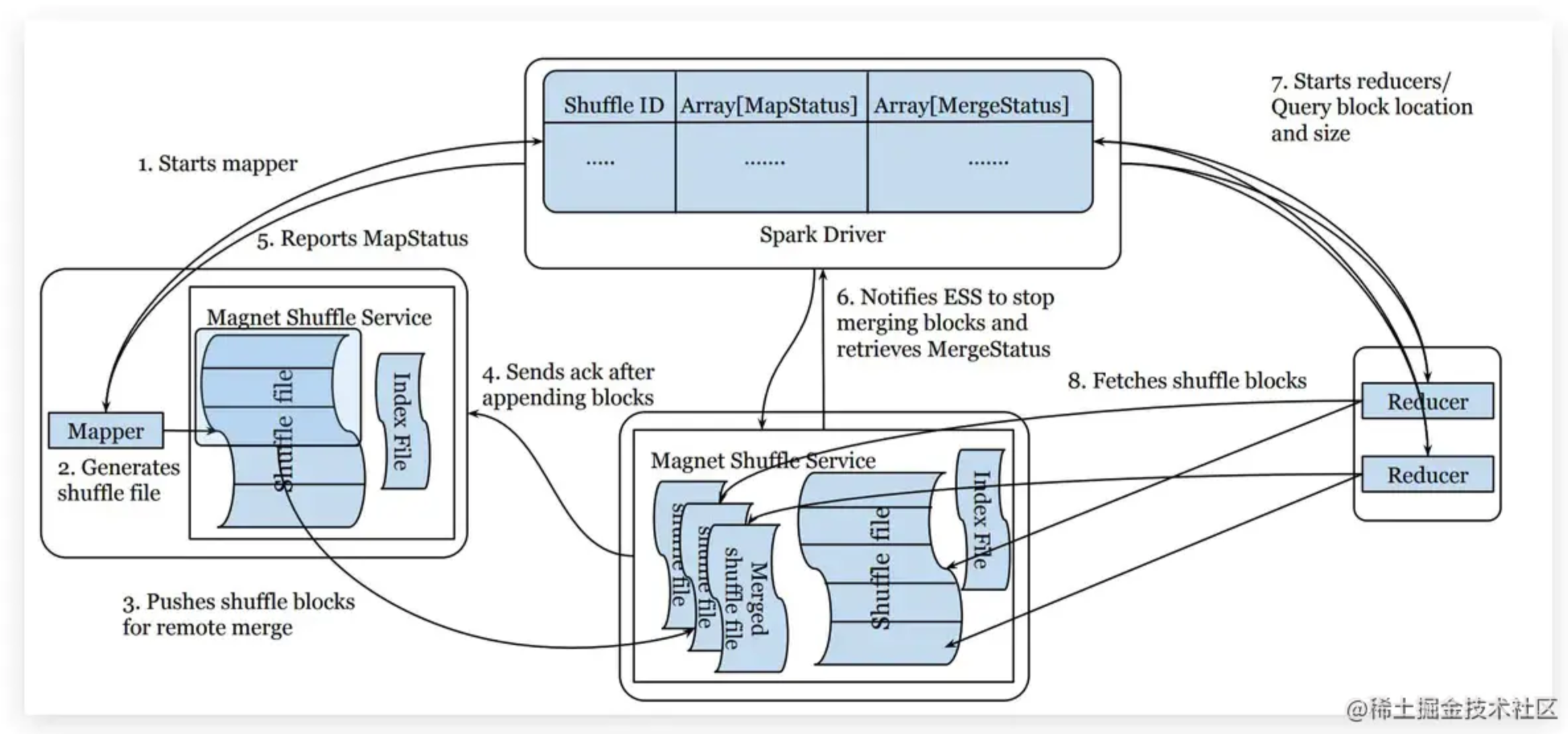
大数据 Shuffle 原理与实践|青训营笔记
课程资料课程视频:https://live.juejin.cn/4354/yc_Shuffle课程PPT:https://bytedance.feishu.cn/file/boxcnQaV9uaxTp4xF0d1vEK5W3c学员手册:https://juejin.cn/post/7123908203590451207/#heading-46完整手册:https://bytedance.feis....
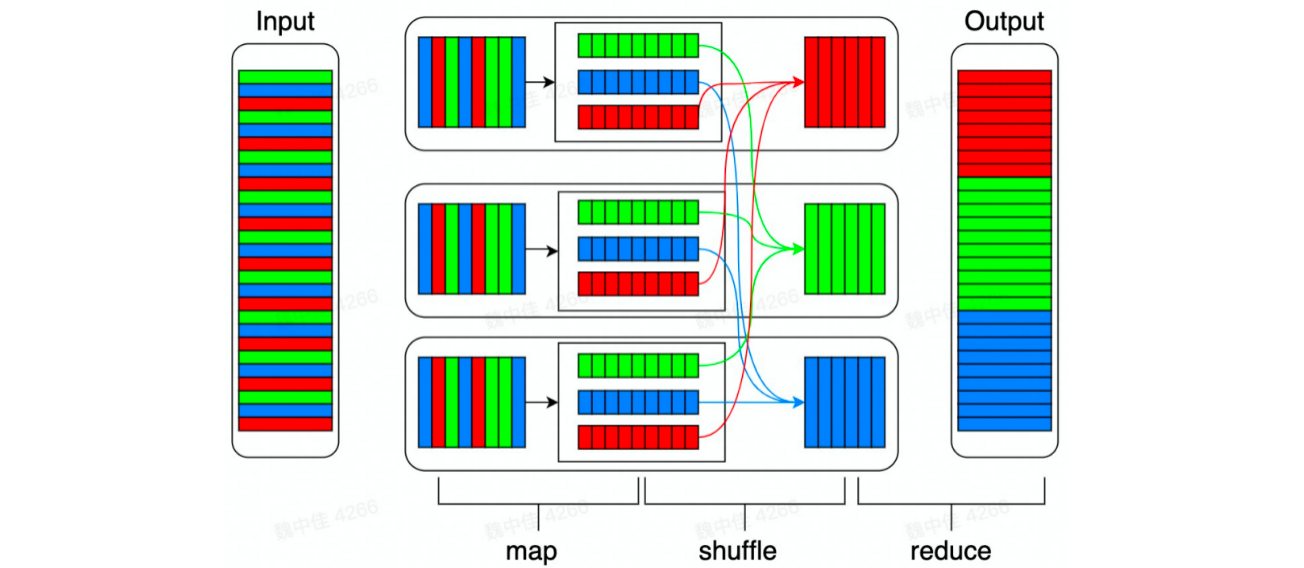
大数据Shuffle原理与实践
Shuffle概述在开源实现的MapReduce中,存在Map、 Shuffle、 Reduce三个阶段。Shuffle过程是MapReduce的核心。 Map阶段:是在单机上进行的针对-一小块数据的计算过程。Shuffle阶段:在map阶段的基础,上,进行数据移动,为后续的reduce阶段做准备。reduce阶段:对移动后的数据进行处理,依然是在单机上处理一小份数据。 为什么...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute实践相关内容
- 云原生大数据计算服务 MaxCompute场景实践
- 云栖云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute智能实践
- 云原生大数据计算服务 MaxCompute运维实践
- 构建云原生大数据计算服务 MaxCompute平台实践
- 构建云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute框架实践
- 实践云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute营销实践
- 云原生大数据计算服务 MaxCompute集群实践
- 云原生大数据计算服务 MaxCompute flink实践
- 云原生大数据计算服务 MaxCompute案例实践
- 云原生大数据计算服务 MaxCompute实践构建
- 云原生大数据计算服务 MaxCompute实践系统
- 阿里云云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute实践数据建模
- 阿里巴巴云原生大数据计算服务 MaxCompute实践
- 混合云云原生大数据计算服务 MaxCompute实践
- 模式云原生大数据计算服务 MaxCompute实践
- 实践polardb-x云原生大数据计算服务 MaxCompute系统互通
- apache云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute存储实践
- hbase云原生大数据计算服务 MaxCompute实践
- 阿里云ecs云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute实践案例
- 云原生大数据计算服务 MaxCompute策略实践
- 云原生大数据计算服务 MaxCompute优化实践
- 云原生大数据计算服务 MaxCompute云原生实践
- 小米云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute应用场景实践
云原生大数据计算服务 MaxCompute更多实践相关
- 云原生大数据计算服务 MaxCompute研究实践
- 云原生大数据计算服务 MaxCompute方案实践
- 云原生大数据计算服务 MaxCompute hive实践
- pdf下载云原生大数据计算服务 MaxCompute实践
- 金融云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute实践数据平台
- 云原生大数据计算服务 MaxCompute实践数据仓库
- dataworks实践云原生大数据计算服务 MaxCompute
- 阿里实践云原生大数据计算服务 MaxCompute
- 阿里巴巴云原生大数据计算服务 MaxCompute实践onedata
- 视角云原生大数据计算服务 MaxCompute实践
- ibm云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute解决方案实践
- 云原生大数据计算服务 MaxCompute开放实践
- 云原生大数据计算服务 MaxCompute调度实践
- 携程云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute实践常见问题
- 云原生大数据计算服务 MaxCompute数据服务实践
- 云原生大数据计算服务 MaxCompute存储异构实践
- 云原生大数据计算服务 MaxCompute智能计算实践
- 数据处理实践云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute客户实践
- 云原生大数据计算服务 MaxCompute实践加载
- 云原生大数据计算服务 MaxCompute pai实践
- 云原生大数据计算服务 MaxCompute复杂数据分布实践
- 云原生大数据计算服务 MaxCompute团队实践
- 云原生大数据计算服务 MaxCompute套件配置实践任务
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute投放
- 云原生大数据计算服务 MaxCompute营销
- 云原生大数据计算服务 MaxCompute场景
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute医疗保健
- 云原生大数据计算服务 MaxCompute金融行业
- 云原生大数据计算服务 MaxCompute动力
- 云原生大数据计算服务 MaxCompute金融科技
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目
大数据计算 MaxCompute
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
+关注