
如何使用Blade优化通过TensorFlow训练的BERT模型
BERT(Bidirectional Encoder Representation from Transformers)是一个预训练的语言表征模型。作为NLP领域近年来重要的突破,BERT模型在多个自然语言处理的任务中取得了最优结果。然而BERT模型存在巨大的参数规模和计算量,因此实际生产中对该模型具有强烈的优化需求。本文主要介绍如何使用Blade优化通过TensorFlow训练的BERT模型。
预训练语言模型中Transfomer模型、自监督学习、BERT模型概述(图文解释)
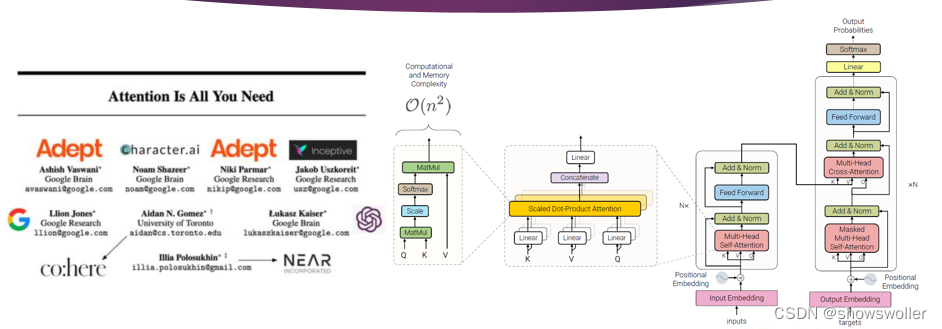
一、Transformer变换器模型Transformer模型的编码器是由6个完全相同的层堆叠而成,每一层有两个子层 。第一个子层是多头自注意力机制层,第二个子层是由一一个简单的、按逐个位置进行全连接的前馈神经网络。在两个子层之间通过残差网络结构进行连接,后接一一个层正则化层。可以得出,每一一个子层的输出通过公式可以表示为LayerNorm(x + Sublayer(x)),其中,Sublaye....
AI加速:使用TorchAcc实现Bert模型分布式训练加速_人工智能平台 PAI(PAI)
阿里云PAI为您提供了部分典型场景下的示例模型,便于您便捷地接入TorchAcc进行训练加速。本文为您介绍如何在BERT-Base分布式训练中接入TorchAcc并实现训练加速。
大语言模型的预训练[1]:基本概念原理、神经网络的语言模型、Transformer模型原理详解、Bert模型原理介绍
大语言模型的预训练[1]:基本概念原理、神经网络的语言模型、Transformer模型原理详解、Bert模型原理介绍 1.大语言模型的预训练 1.LLM预训练的基本概念 预训练属于迁移学习的范畴。现有的神经网络在进行训练时,一般基于反向传播(Back Propagation,BP)算法,先对网络中的参数进行随机初始化,再利用随机梯度下降(Stochastic Gradient Descen...
![大语言模型的预训练[1]:基本概念原理、神经网络的语言模型、Transformer模型原理详解、Bert模型原理介绍](https://ucc.alicdn.com/fnj5anauszhew_20230717_e843a02529534b84bf8ff46d8b43e094.png)
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
bert模型相关内容
- bert模型架构
- 模型bert
- 训练bert large模型
- bert模型训练
- 训练模型bert
- nlp bert模型
- bert模型方法
- 部署bert模型
- bert模型文件
- bert文本分类模型
- 模型bert预训练
- bert模型原理
- 预训练模型bert
- bert模型配置
- bert模型推理
- transformer模型bert
- 模型推理bert
- 模型推理onnx bert特征抽取
- 模型推理bert方案
- bert模型框架
- 模型xlnet bert
- 任务bert模型
- bert文本分类实战模型
- 文本分类bert模型
- bert谷歌模型
- 构建bert模型蒸馏textcnn
- 怎么使用构建bert模型蒸馏textcnn
- bert模型nlp