
【Python强化学习】时序差分法Sarsa算法和Qlearning算法在冰湖问题中实战(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~时序差分算法时序差分法在一步采样之后就更新动作值函数Q(s,a),而不是等轨迹的采样全部完成后再更新动作值函数。在时序差分法中,对轨迹中的当前步的(s,a)的累积折扣回报G,用立即回报和下一步的(s^′,a^′)的折扣动作值函数之和r+γQ(s^′,a^′)来计算,即:G=r+γQ(s^′,a^′)在递增计算动作值函数时,用一个[0,1]之间的步长α来....
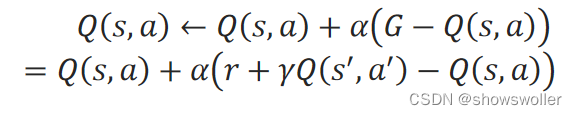
深度强化学习中利用Q-Learngin和期望Sarsa算法确定机器人最优策略实战(超详细 附源码)
需要源码和环境搭建请点赞关注收藏后评论区留下QQ~~~一、Q-Learning算法Q-Learning算法中动作值函数Q的更新方向是最优动作值函数q,而与Agent所遵循的行为策略无关,在评估动作值函数Q时,更新目标为最优动作值函数q的直接近似,故需要遍历当前状态的所有动作,在所有状态都能被无限次访问的前提下,Q-Learning算法能以1的概率收敛到最优动作值函数和最优策略下图是估算最优策略的....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
算法更多源码相关

智能引擎技术
AI Online Serving,阿里巴巴集团搜推广算法与工程技术的大本营,大数据深度学习时代的创新主场。
+关注