
DataWorks OpenAPI最佳实践
DataWorks提供了丰富的OpenAPI,您可以根据需要使用DataWorks的OpenAPI等开放能力实现各种业务场景,本文为您介绍DataWorks OpenAPI的最佳实践。
黑马程序员-大数据入门到实战-MapReduce & YARN入门
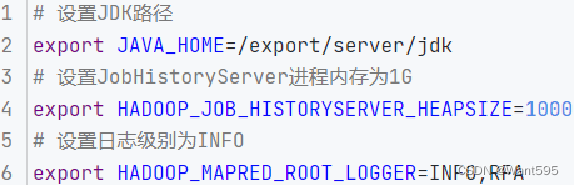
1. 分布式计算概述计算与分布式计算计算:对数据进行处理,使用统计分析等手段得到需要的结果分布式计算:多台服务器协同工作,共同完成一个计算任务分布式计算的两种工作模式分散→汇总(MapReduce)中心调度→步骤执行(Spark、Flink)2. MapReduce概述MapReduceHadoop中分布式计算组件分散→汇总模式主要接口map接口:“分散”功能reduce接口:“汇总”功能运行机....
JindoFS实战的详细文档和演示视频_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
通过JindoFS,您可以完成数据迁移、OSS访问加速、缓存加速、AI训练加速和JindoTable计算加速。本文为您介绍JindoFS实战的详细文档和演示视频。
Hadoop大数据平台实战(05):深入Spark Cluster集群模式YARN vs Mesos vs Standalone vs K8s
Spark可以以分布式集群架构模式运行,如果我们不熟Spark Cluster,这个时候需要集群管理器帮助我们管理Spark 集群。 集群管理器根据需要为所有工作节点提供资源,操作所有节点。负责管理和协调集群节点的程序一般叫做:Cluster Manager,集群管理器。目前搭建Spark 集群,可以的选择包括Standalone,YARN,Mesos,K8s,这么多工具,在部署Spark集群时....
史上最快! 10小时大数据入门实战(四)-分布式资源调度YARN
1 YARN 产生背景 2 YARN 架构 3 YARN 执行流程 1.client向yarn提交job,首先找ResourceManager分配资源, 2.ResourceManager开启一个Container,在Container中运行...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute实战相关内容
- 云原生大数据计算服务 MaxCompute构建实战
- 实战云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute flink实战
- 企业云原生大数据计算服务 MaxCompute实战
- 云原生大数据计算服务 MaxCompute实战统计
- 云原生大数据计算服务 MaxCompute案例实战
- apache云原生大数据计算服务 MaxCompute实战
- 云原生大数据计算服务 MaxCompute实战案例
- 云原生大数据计算服务 MaxCompute实战实践
- 云原生大数据计算服务 MaxCompute实战mapreduce
- 云原生大数据计算服务 MaxCompute实战环境搭建
- 金融云原生大数据计算服务 MaxCompute实战
- 云原生大数据计算服务 MaxCompute实战应用
- 云原生大数据计算服务 MaxCompute实战spark
- 云原生大数据计算服务 MaxCompute flume实战
- 云原生大数据计算服务 MaxCompute mapreduce实战
- 云原生大数据计算服务 MaxCompute实战源码
- 云原生大数据计算服务 MaxCompute集群实战
- 云原生大数据计算服务 MaxCompute实战pdf
- 云原生大数据计算服务 MaxCompute部署实战
- 程序员云原生大数据计算服务 MaxCompute实战
- 云原生大数据计算服务 MaxCompute入门实战hdfs
- 云原生大数据计算服务 MaxCompute入门实战yarn
- 云原生大数据计算服务 MaxCompute企业实战
- 云原生大数据计算服务 MaxCompute开发实战
- 云原生大数据计算服务 MaxCompute azkaban实战
- 云原生大数据计算服务 MaxCompute apache spark入门实战
- 云原生大数据计算服务 MaxCompute apache实战
- 云原生大数据计算服务 MaxCompute实战电子版地址
- hbase lindorm云原生大数据计算服务 MaxCompute入门实战
云原生大数据计算服务 MaxCompute更多实战相关
- 实战任务云原生大数据计算服务 MaxCompute
- 开源云原生大数据计算服务 MaxCompute实战
- 下载云原生大数据计算服务 MaxCompute实战
- 下载云上云原生大数据计算服务 MaxCompute实战
- 云原生大数据计算服务 MaxCompute实战安装
- 保险云原生大数据计算服务 MaxCompute实战
- lindorm云原生大数据计算服务 MaxCompute入门实战
- 云原生大数据计算服务 MaxCompute开源实战
- 云原生大数据计算服务 MaxCompute实战训练营
- 云原生大数据计算服务 MaxCompute挖掘实战
- 智能数据云原生大数据计算服务 MaxCompute实战
- 智能数据云原生大数据计算服务 MaxCompute实战评估
- 智能数据云原生大数据计算服务 MaxCompute实战大数据处理
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute点燃
- 云原生大数据计算服务 MaxCompute智能电商
- 云原生大数据计算服务 MaxCompute购物
- 云原生大数据计算服务 MaxCompute算法
- 云原生大数据计算服务 MaxCompute脏数据
- 云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute潜能
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute oss
- 云原生大数据计算服务 MaxCompute分布式
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
大数据计算 MaxCompute
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
+关注