
选择业务场景
阿里云EMR针对不同业务场景提供了数据湖集群、数据分析集群、实时数据流集群、数据服务集群四类预定义业务场景。若您的业务需集成特定组合的组件,您可创建自定义集群,灵活组合EMR提供的组件,打造适配业务特性的大数据平台。本文将为您介绍这些集群的区别,帮助您快速选型。
与自建集群的对比优势
与自建Hadoop集群相比,开源大数据开发平台EMR提供弹性资源管理和自动化运维,降低运维复杂度,通过用户管理、数据加密和权限管理等为数据安全保驾护航,同时EMR集成了丰富的开源组件并打通开源生态与阿里云生态,便于快速搭建大数据处理和分析场景。
使用Hadoop命令操作OSS/OSS-HDFS
在使用阿里云EMR Serverless Spark的Notebook时,您可以通过Hadoop命令直接访问OSS或OSS-HDFS数据源。本文将详细介绍如何通过Hadoop命令操作OSS/OSS-HDFS。
大数据技术:Hadoop与Spark的对比
一、引言 随着数据量的爆炸性增长,大数据技术成为了处理和分析这些海量数据的关键。Hadoop和Spark作为当前最流行的大数据处理框架,各自具有独特的优势和适用场景。本文将对Hadoop和Spark进行详细的对比,帮助读者更好地理解两者的异同,以便在实际应用中做出明智的选择。 二、Hadoop概述 Hadoop是一个由Apache基金会开发...
探索大数据技术:Hadoop与Spark的奥秘之旅
在当今这个信息爆炸的时代,大数据已经成为了推动社会进步和企业发展的重要力量。为了更好地利用这些海量的数据资源,大数据技术如Hadoop和Spark应运而生,为我们提供了强大的数据处理和分析能力。本文将带领大家深入探索Hadoop和Spark的技术奥秘,解析它们的工作原理、应用场景以及未来发展趋势。 一、Hadoop:大数据处理...
大数据技术与Python:结合Spark和Hadoop进行分布式计算
随着互联网的普及和技术的飞速发展,大数据已经成为当今社会的重要资源。大数据技术是指从海量数据中提取有价值信息的技术,它包括数据采集、存储、处理、分析和挖掘等多个环节。Python作为一种功能强大、简单易学的编程语言,在数据处理和分析领域具有广泛的应用。本文将介绍如何使用Python结合Spark和Hadoop进行分布式计算,以应对大数据挑战...
迁移Hadoop集群至DataLake集群
本文将详细阐述如何将您已有的旧版数据湖集群(Hadoop),高效地迁移至数据湖集群(DataLake),以下分别简称“旧集群”和“新集群”。迁移过程将充分考虑旧集群的版本、元数据类型以及存储方式,并针对这些因素,提供适应新集群的迁移策略与步骤。
【大数据技术Hadoop+Spark】Flume、Kafka的简介及安装(图文解释 超详细)
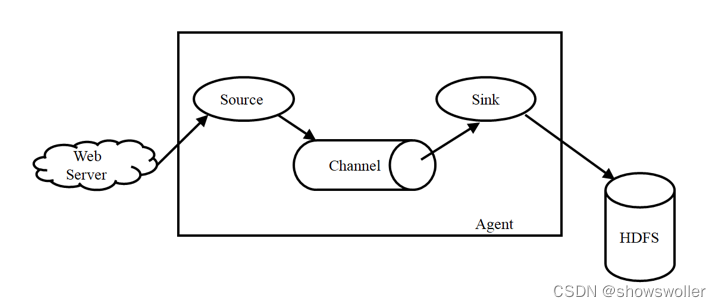
Flume简介Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume主要由3个重要的组件构成:1)Source:完成对日志数据的收集,分成transtion 和 event 打入到channel之中。2)Cha....
【大数据技术Hadoop+Spark】Spark SQL、DataFrame、Dataset的讲解及操作演示(图文解释)
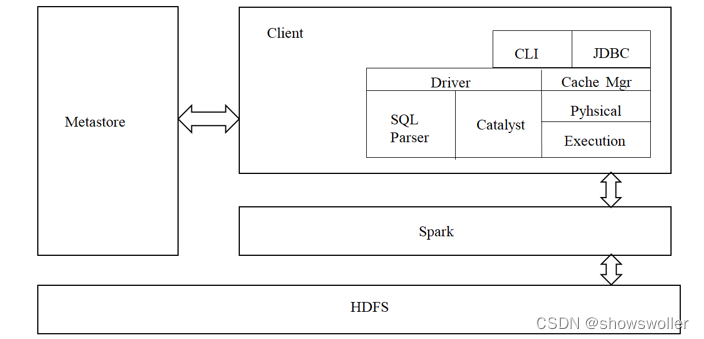
一、Spark SQL简介park SQL是spark的一个模块,主要用于进行结构化数据的SQL查询引擎,开发人员能够通过使用SQL语句,实现对结构化数据的处理,开发人员可以不了解Scala语言和Spark常用API,通过spark SQL,可以使用Spark框架提供的强大的数据分析能力。spark SQL前身为Shark。Shark是Spark上的数据仓库,最初设计成与Hive兼容,但是该项目....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop大数据相关内容
- hadoop spark大数据
- hadoop spark大数据协同
- 大数据hadoop环境
- 大数据学习hadoop
- 大数据hadoop
- 大数据hadoop分析
- 大数据spark模式hadoop
- 大数据模式hadoop
- 大数据部署hadoop
- 大数据hadoop mapreduce
- 大数据hadoop yarn
- 大数据hadoop节点
- 大数据hadoop笔记
- 大数据hadoop分发
- 大数据hadoop配置
- 大数据环境搭建hadoop
- 大数据组件hadoop
- hadoop入门大数据
- hadoop构建大数据分析
- hadoop概述大数据
- hadoop构建大数据
- hadoop系统大数据
- 大数据hadoop spark
- 大数据maxcompute hadoop
- 阿里巴巴大数据hadoop系统
- 大数据hadoop系统
- 大数据hadoop安装
- 大数据hadoop集成
- 大数据java hadoop
- hadoop大数据工具
hadoop更多大数据相关
- 大数据hadoop集群搭建
- hadoop系统大数据技术
- hadoop大数据入门
- 大数据hadoop伪分布
- 大数据hadoop安装教程
- 大数据hadoop教程
- 大数据hadoop入门
- 大数据hadoop简介
- 大数据hadoop mapreduce编程
- 大数据hadoop实践
- 大数据开发hadoop
- 大数据hadoop编程
- 大数据面试hadoop
- 大数据hadoop分布式
- 大数据实战hadoop
- 大数据hadoop开发
- 大数据实践hadoop
- 大数据hadoop应用
- 大数据面试题百日hadoop
- 大数据hadoop原理
- 大数据开发hadoop安装
- 大数据hadoop hive
- hadoop分布式大数据
- 大数据hadoop部署
- 大数据hadoop hbase
- 大数据hadoop运行
- 大数据hadoop技术
- 大数据框架hadoop
- 大数据环境hadoop
- 大数据hadoop命令
hadoop您可能感兴趣
- hadoop入门
- hadoop系统
- hadoop spark
- hadoop技术
- hadoop集群管理
- hadoop架构
- hadoop hdfs
- hadoop数据
- hadoop技术选型
- hadoop分布式
- hadoop集群
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop hbase
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作
- hadoop apache