
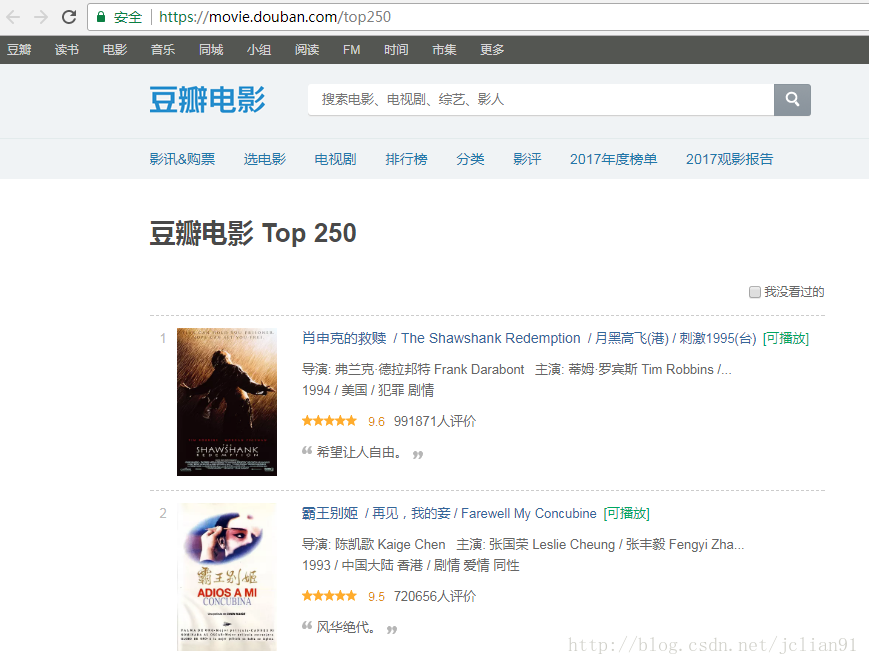
Scrapy爬虫(4)爬取豆瓣电影Top250图片
在用Python的urllib和BeautifulSoup写过了很多爬虫之后,本人决定尝试著名的Python爬虫框架——Scrapy. 本次分享将详细讲述如何利用Scrapy来下载豆瓣电影Top250, 主要解决的问题有: 如何利用ImagesPipeline来下载图片 如何对下载后的图片重命名,这是因为Scrapy默认用Hash值来保存文件,这并不是我们想要的 首先我们要爬...
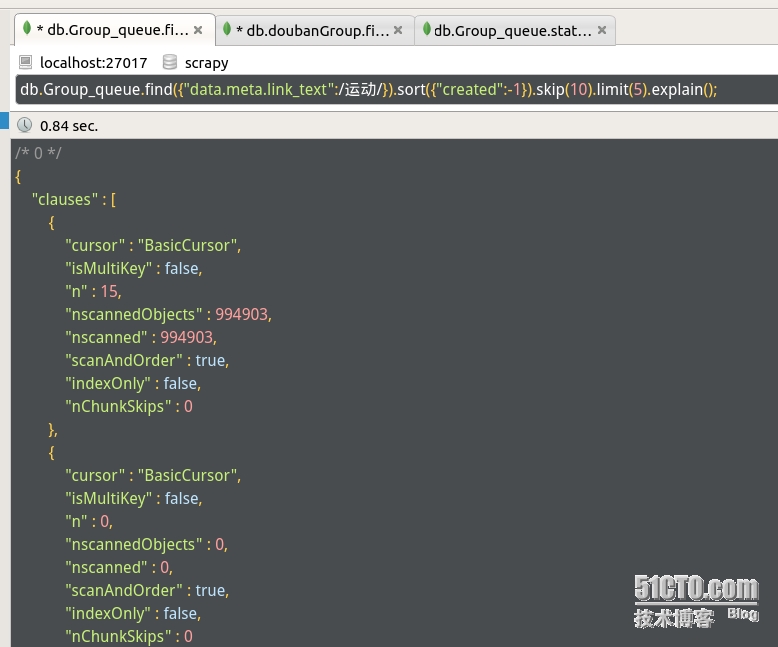
Scrapy 爬虫实例 抓取豆瓣小组信息并保存到mongodb中
这个框架关注了很久,但是直到最近空了才仔细的看了下 这里我用的是scrapy0.24版本 先来个成品好感受这个框架带来的便捷性,等这段时间慢慢整理下思绪再把最近学到的关于此框架的知识一一更新到博客来。 最近想学git 于是把代码放到 git-osc上了: https://git.oschina.net/1992mrwang/doubangroupspider 先说明下这个玩具爬虫的目的...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
爬虫scrapy相关内容
- scrapy框架爬虫
- scrapy爬虫策略
- 爬虫框架scrapy
- scrapy爬虫应用
- 爬虫scrapy框架
- 爬虫scrapy数据
- scrapy爬虫自定义
- 爬虫开发scrapy
- 爬虫scrapy入门
- 爬虫scrapy爬取
- scrapy爬虫爬取数据
- scrapy爬虫数据
- scrapy爬虫爬取
- 配置scrapy爬虫
- 爬虫库scrapy
- 爬虫scrapy豆瓣
- 爬虫scrapy xpath
- 爬虫scrapy安装
- 爬虫scrapy框架爬取
- 爬虫scrapy管理工具
- 爬虫scrapy工具
- 爬虫scrapy功能
- 爬虫scrapy代理
- 爬虫scrapy爬虫框架
- 爬虫scrapy框架安装
- scrapy爬虫项目
- scrapy爬虫调试
- scrapy爬虫教程
- scrapy爬虫实例
- scrapy爬虫报错
爬虫更多scrapy相关
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注