
简单通用:视觉基础网络最高3倍无损训练加速,清华EfficientTrain++入选TPAMI 2024
在深度学习领域,视觉基础网络(Visual Backbone Networks)是实现图像识别和其他视觉任务的关键组件。这些网络模型,如ResNet、ConvNeXt、DeiT等,因其卓越的性能而广受欢迎。然而,这些模型的训练过程往往耗时且成本高昂,这不仅限制了它们的应用范围,也对环境...
探索未来的视觉革命:卷积神经网络的崭新时代(二)
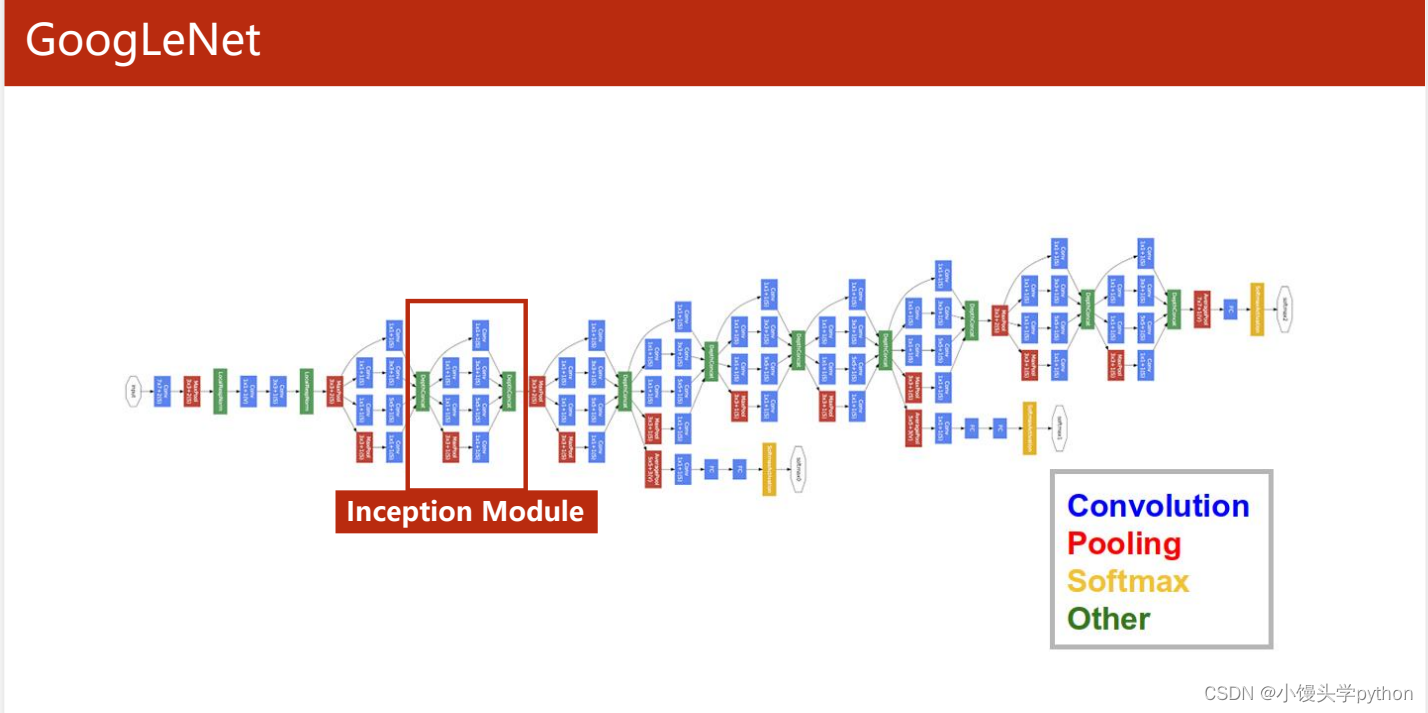
本节在学完刘二大人的卷积神经网络进阶篇,令我感受颇深,下面我先说一下知识点,文章的结尾我再表达一下我的个人看法以及刘二大人对我们的建议。 引言 本节介绍一下GoogleNet,首先说一下它的背景历史,GoogleNet是由Google研究员Christian Szegedy等人于2014年提出的深度卷积神经网络架构。它在当时的ImageNet图像分类挑战赛中取得了惊人...
探索未来的视觉革命:卷积神经网络的崭新时代(一)
引言 当谈到深度学习和计算机视觉时,卷积神经网络(Convolutional Neural Networks,CNNs)一直是热门话题。CNNs是一类专门设计用于处理图像数据的深度学习神经网络,已经在许多领域取得了重大成功,如图像分类、目标检测、人脸识别和自动驾驶。本文将探讨卷积神经网络的基本原理、应用领域以及一些最新趋势。 卷积神经网络的基本原理 ...

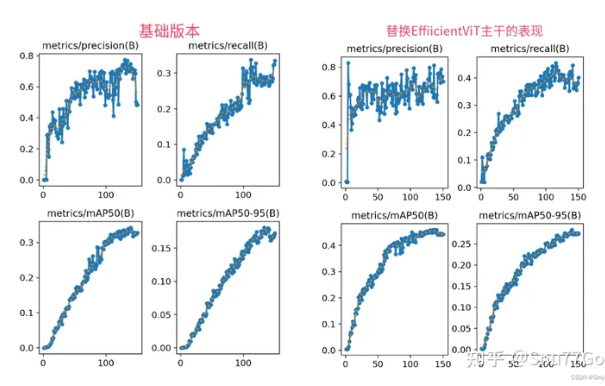
YOLOv5改进 | 2023主干篇 | EfficientViT替换Backbone(高效的视觉变换网络)
一、本文介绍 本文给大家带来的改进机制是EfficientViT(高效的视觉变换网络),EfficientViT的核心是一种轻量级的多尺度线性注意力模块,能够在只使用硬件高效操作的情况下实现全局感受野和多尺度学习。本文带来是2023年的最新版本的EfficientViT网络结构,论文题目是'EfficientViT: Multi-Scale Linear Attention for Hi...
CVPR2021 | 视觉推理解释框架VRX:用结构化视觉概念作为解释网络推理逻辑的「语言」
大家好,我是Charmve。今天分享的一篇文章来自葛云皓,本文主要介绍了被 CVPR 2021 录用的文章《A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts》。本文提出了一个视觉推理解释框架 (VRX: Visual Reasoning eXplanation), ....

首篇!BEV-Locator:多目端到端视觉语义定位网络(清华&轻舟智航)(下)
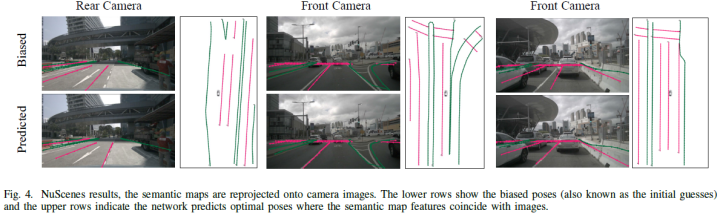
实验和讨论nuScenes数据集结果NuScenes数据集包含城市地区的700个训练场景和150个测试场景,图像由6个环视摄像机拍摄。论文在nuScenes数据集上进行实验,以验证BEV定位器的有效性(用35个epoch训练)。论文从地图界面中提取地图元素。元素类型包括道路边界、车道分隔线和人行横道。所有6个摄像机图像被组合以形成BEV特征。图4展示了定位过程。基于所提供的语义图、初始位姿和相机....
首篇!BEV-Locator:多目端到端视觉语义定位网络(清华&轻舟智航)(上)
摘要准确的定位能力是自动驾驶的基础。传统的视觉定位框架通过几何模型来解决语义地图匹配问题,几何模型依赖于复杂的参数调整,从而阻碍了大规模部署。本文提出了BEV定位器:一种使用多目相机图像的端到端视觉语义定位神经网络。具体地,视觉BEV(鸟瞰图)编码器提取多目图像并将其展平到BEV空间中。而语义地图特征在结构上嵌入为地图查询序列。然后,cross-model transformer将BEV特征和语....
视觉神经网络模型优秀开源工作:PyTorch Image Models(timm)库(下)
1.4. 特征提取timm 提供了很多不同类型网络中间层的机制,其有助于作为特征提取以应用于下游任务.1.4.1. 最终特征图from PIL import Image import matplotlib.pyplot as plt import numpy as np import torch image = Image.open('test.jpg') image = torch.a...
视觉神经网络模型优秀开源工作:PyTorch Image Models(timm)库(上)
视觉神经网络模型优秀开源工作:PyTorch Image Models(timm)库PyTorchImageModels,简称timm,是一个巨大的PyTorch代码集合,包括了一系列:image modelslayersutilitiesoptimizersschedulersdata-loaders / augmentationstraining / validation scripts旨在....
ViTGAN:用视觉Transformer训练生成性对抗网络 Training GANs with Vision Transformers
> @[TOC](目录)ViTGAN是加州大学圣迭戈分校与 Google Research提出的一种用视觉Transformer来训练GAN的模型。该论文已被NIPS(Conference and Workshop on Neural Information Processing Systems,计算机人工智能领域A类会议)录用,文章发表于2021年10月。论文地址:https://arx....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

域名解析DNS
关注DNS行业趋势、技术、标准、产品和最佳实践,连接国内外相关技术社群信息,追踪业内DNS产品动态,加强信息共享,欢迎大家关注、推荐和投稿。
+关注