
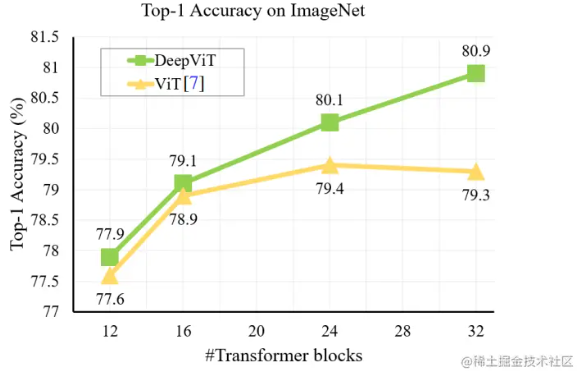
【DeepViT】我们能否通过使用更深层来进一步提高vit的性能,就像cnn一样?
前言 DeepVit是一种基于基于VIT进行拓展的模型,因为ViT在本质上与cnn不同与cnn在很大程度上依赖于自我关注机制。本篇博客将详细介绍DeepVit模型是如何进行深度拓展性以及相应的基本原理和特点,希望对读者深入了解深度学习技术以及图像与语言任务有所帮助。 实践结论 transformer blocks模块 ...
YOLOv5改进 | 2023主干篇 | RepViT从视觉变换器(ViT)的视角重新审视CNN
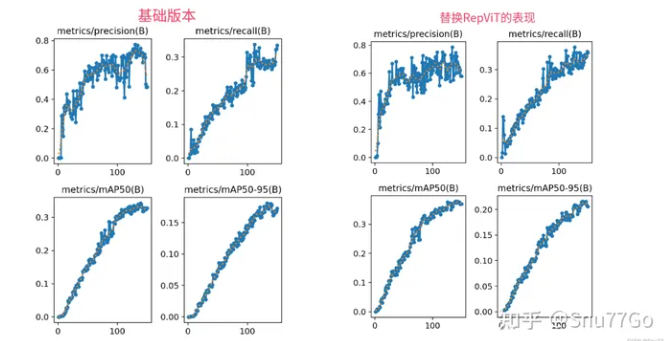
一、本文介绍 本文给大家来的改进机制是RepViT,用其替换我们整个主干网络,其是今年最新推出的主干网络,其主要思想是将轻量级视觉变换器(ViT)的设计原则应用于传统的轻量级卷积神经网络(CNN)。我将其替换整个YOLOv5的Backbone,实现了大幅度涨点。我对修改后的网络(我用的最轻量的版本),在一个包含1000张图片包含大中小的检测目标的数据集上(共有20+类别),进行训练测试,...
将大核卷积分三步,清华胡事民、南开程明明团队全新视觉骨干VAN,超越SOTA ViT和CNN
来自清华大学和南开大学的研究者提出了一种新型大核注意力(large kernel attention,LKA)模块,并在 LKA 的基础上构建了一种性能超越 SOTA 视觉 transformer 的新型神经网络 VAN。作为基础特征提取器,视觉骨干(vision backbone)是计算机视觉领域的基础研究课题。得益于卓越的特征提取性能,CNN 成为过去十年中不可或缺的研究课题。在 AlexN....

计算机视觉论文速递(七)FAN:提升ViT和CNN的鲁棒性和准确性
相关资源来自集智书童1. 摘要 最近的研究表明,Vision Transformers对各种Corruptions表现出很强的鲁棒性。虽然这一特性部分归因于Self-Attention机制,但目前仍缺乏系统的理解。 在本文中研究了Self-Attention在学习鲁棒表征中的作用。本研究是基于Vision Transformer中新出现的Visual Grouping的特....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。