
什么是索引重建的导数原理_OpenSearch-行业算法版_智能开放搜索 OpenSearch(Open Search)
不同操作触发的索引重建,根据用户配置的数据源的不同,其导入数据的来源以及继承老版本数据的方式也大有区别,为防止用户因误操作导致的部分数据无法同步引起的线上问题,在此进行详细说明。说明触发索引重建的操作:手动/定时索引重建、手动/定时清理文档、线下变更。触发索引重建的操作行业算法版数据源:表示在Ope...
OpenSearch同步数据的原理是什么_OpenSearch-行业算法版_智能开放搜索 OpenSearch(Open Search)
实时同步(增量数据)由上图所示,增量数据一共有两部分(DB更新的和API推送的),新数据从源到opensearch一共有3个步骤:1.用户更新DB(通过DTS服务订阅数据库的binlog实现)或者调用API接口将数据推送到OpenSearch离线,此时主+辅表有1500tps的限制2. 当数据抵达离...
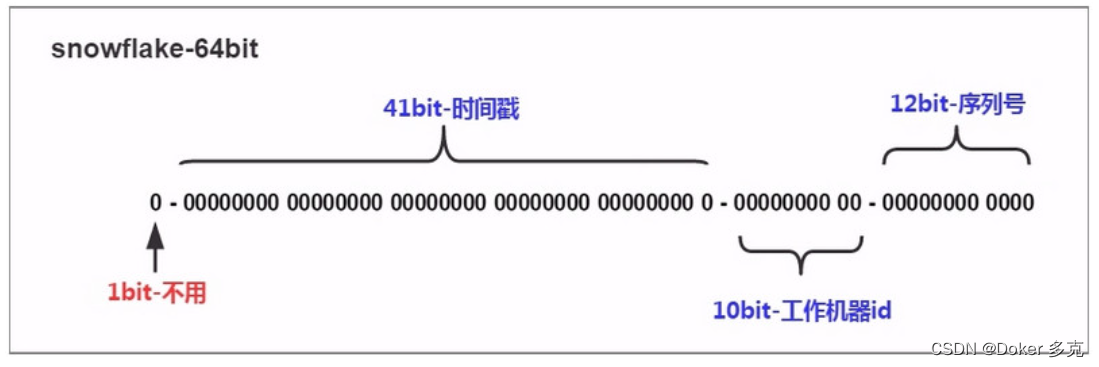
SnowFlake 雪花算法和原理(分布式 id 生成算法)
一、概述SnowFlake 算法:是 Twitter 开源的分布式 id 生成算法。核心思想:使用一个 64 bit 的 long 型的数字作为全局唯一 id。编辑算法原理 最高位是符号位,始终为0,不可用。 41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。 10位的机器标识,10位的长度最多支持部署1024个节点 12位的计数序列号....
冷饭新炒:理解Snowflake算法的实现原理
前提Snowflake(雪花)是Twitter开源的高性能ID生成算法(服务)。上图是Snowflake的Github仓库,master分支中的REAEMDE文件中提示:初始版本于2010年发布,基于Apache Thrift,早于Finagle(这里的Finagle是Twitter上用于RPC服务的构建模块)发布,而Twitter内部使用的Snowflake是一个完全重写的程序,在很大程度上依....

冷饭新炒:理解Snowflake算法的实现原理
前提 Snowflake(雪花)是Twitter开源的高性能ID生成算法(服务)。 上图是Snowflake的Github仓库,master分支中的REAEMDE文件中提示:初始版本于2010年发布,基于Apache Thrift,早于Finagle(这里的Finagle是Twitter上用于RPC服务的构建模块)发布,而Twitter内部使用的Snowflake是一个完全重写的程序,在很大程.....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
算法更多原理相关

智能搜索推荐
智能推荐(Artificial Intelligence Recommendation,简称AIRec)基于阿里巴巴大数据和人工智能技术,以及在电商、内容、直播、社交等领域的业务沉淀,为企业开发者提供场景化推荐服务、全链路推荐系统开发平台、工程引擎组件库等多种形式服务,助力在线业务增长。
+关注