
Hive性能优化之计算Job执行优化 2
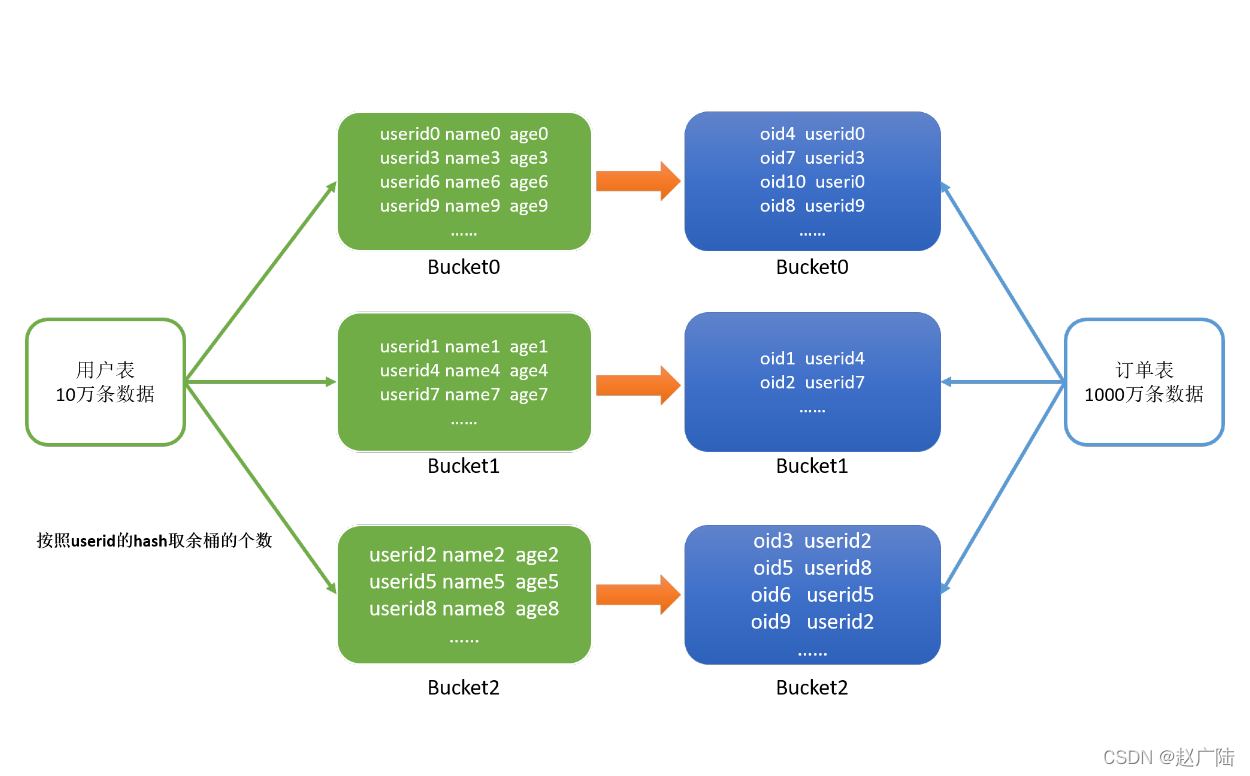
3.4 Bucket Join⚫ 应用场景适合于大表Join大表⚫ 原理◼ 将两张表按照相同的规则将数据划分,根据对应的规则的数据进行join,减少了比较次数,提高了性能⚫ 使用◼ Bucket Join语法:clustered by colName参数– 开启分桶 joinset hive.optimize.bucketmapjoin = true;要求分桶字段 = Join字段 ,桶的个数相....
Hive性能优化之计算Job执行优化 1
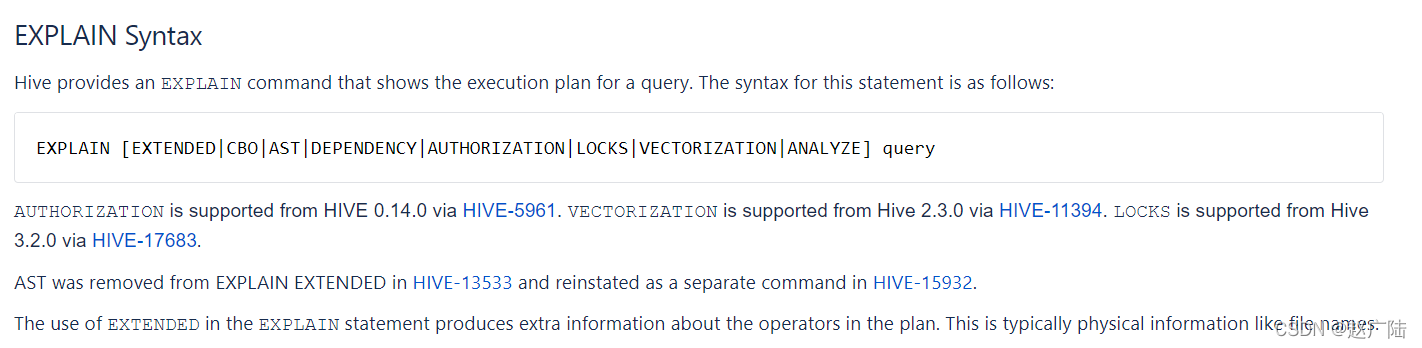
1 Explain1.1 功能HiveQL是一种类SQL的语言,从编程语言规范来说是一种声明式语言,用户会根据查询需求提交声明式的HQL查询,而Hive会根据底层计算引擎将其转化成Mapreduce/Tez/Spark的 job。大多数情况下,用户不需要了解Hive内部是如何工作的,不过,当用户对于Hive具有越来越多的经验后,尤其是需要在做性能优化的场景下,就要学习下Hive背后的理论知识以及....
Flink是否能只启动一个job的情况下写入多张hive数据表?
Flink是否能只启动一个job的情况下写入多张hive数据表?我这边用的flink版本是1.13.2的,需要对接kafka的数据写入到多张hive数据表,在使用tableapi的时候发现会启动多个job,
flink 能否在一个job里 既有批又有流呢?比如从hive里查出历史数据写入redis,然后ka
flink 能否在一个job里 既有批又有流呢?比如从hive里查出历史数据写入redis,然后kafka再续上实时数据。
Flink 1.12 job on yarn 集成hive时如何配置 hiveConf?
请问在flink在集成hive时候,需要配置hive的conf目录,我的job是on yarn提交的,那么如何配置这个hive conf路径呢? String name = "myhive"; String defaultDatabase = "mydatabase"; String hiveConfDir = ""; // hive-site.xml路径&nb...
Hive job,抛错could only be replicated to 0 nodes instead of minReplication(=1)
场景: hive执行一条sql语句,然后map,reduce做完了,写数据over了hive> select dday.full_day, sum(quantity_ordered) from fact_order as fact inner join dim_day as dday on fact.time_key == dday.day_key and dday.full_d...
Hive job,抛错java.io.FileNotFoundException:/.../container_000001(Is a directory)
场景: 跑hive job时,夯住 错误: 查看RM WebSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/hadoop/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
