
【Python机器学习】Sklearn库中Kmeans类、超参数K值确定、特征归一化的讲解(图文解释)
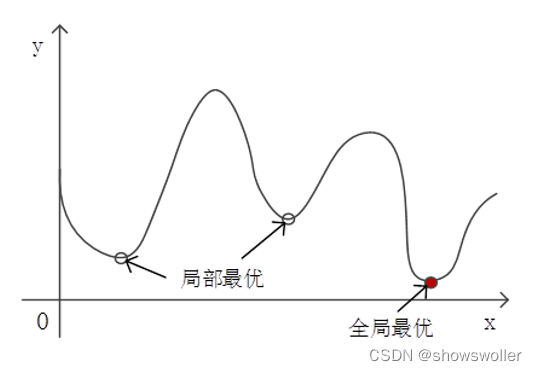
一、局部最优解采用随机产生初始簇中心 的方法,可能会出现运行 结果不一致的情况。这是 因为不同的初始簇中心使 得算法可能收敛到不同的 局部极小值。不能收敛到全局最小值,是最优化计算中常常遇到的问题。有一类称为凸优化的优化计算,不存在局部最优问题。凸优化是指损失函数为凸函数的最优化计算。在凸函数中,没有局部极小值这样的小“洼地”,因此是最理想的损失函数。如果能将优化目标转化为凸函数,就可以解决局部....
详解机器学习中的数据处理(二)——特征归一化
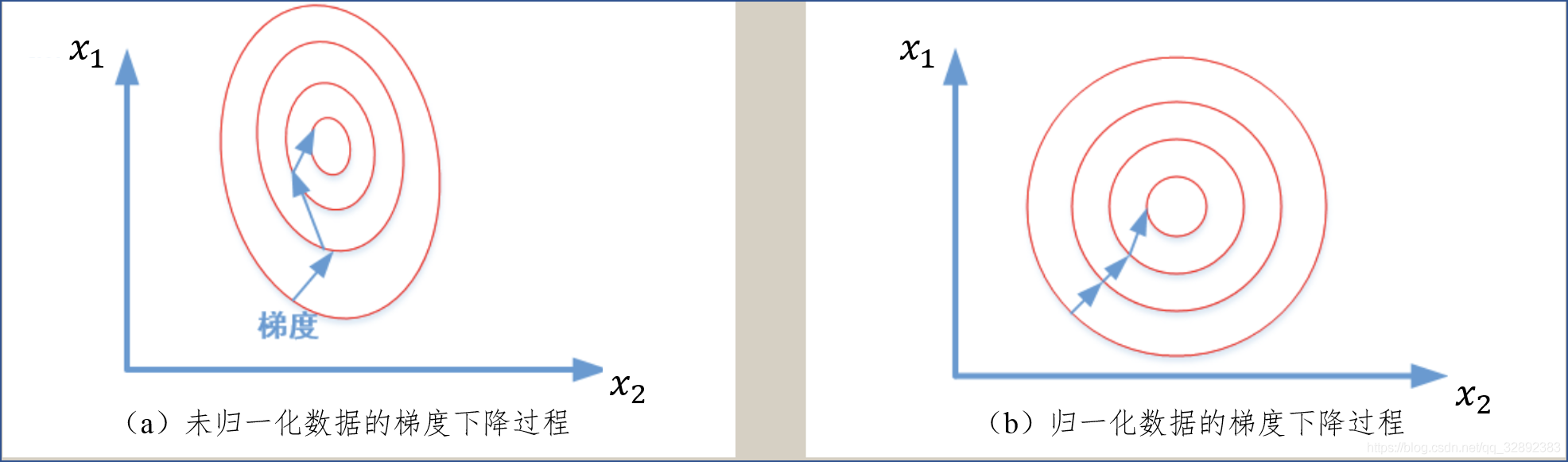
1.特征归一化 特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上来讲,特征工程是一个表示和展现数据的过程。在实际工作中,特征工程旨在去除原始数据中的杂质和冗余,设计更高效的特征以刻画求解的问题与预测模型之间的关系。 归一化和标准化都可以使特征无量纲化,归一化使得数据放缩在[0, 1]之间并且使得特征之间的权值相同,改变....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
机器学习平台 PAI特征相关内容
- 机器学习平台 PAI样本特征
- 机器学习平台 PAI特征标签
- 机器学习平台 PAI特征选择特征
- 机器学习平台 PAI包裹特征选择递归特征
- 机器学习平台 PAI embedding特征
- 机器学习平台 PAI特征配置
- 机器学习平台 PAI序列特征
- 机器学习平台 PAI特征分桶
- 机器学习平台 PAI tag特征
- 机器学习平台 PAI计算特征
- 机器学习平台 PAI特征emb
- 机器学习平台 PAI kv特征
- 机器学习平台 PAI特征序列
- 机器学习平台 PAI统计特征
- 机器学习平台 PAI特征embedding
- 机器学习平台 PAI特征映射
- 机器学习平台 PAI特征变量
- 机器学习平台 PAI特征降维
- 机器学习平台 PAI pai特征等长
- 机器学习平台 PAI feature_config特征
- 机器学习平台 PAI特征编码
- 机器学习平台 PAI特征重要性
- 机器学习平台 PAI特征怎么处理
- 机器学习平台 PAI特征工程特征
- 机器学习平台 PAI数学特征分解
- 机器学习平台 PAI特征离散
- 阿旭机器学习平台 PAI特征
- 机器学习平台 PAI特征特征向量
机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI scikit-learn
- 机器学习平台 PAI python
- 机器学习平台 PAI代码
- 机器学习平台 PAI论文
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI实战
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI模型
- 机器学习平台 PAI构建
- 机器学习平台 PAIpai
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI数据
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI方法
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI分类
- 机器学习平台 PAI平台
- 机器学习平台 PAI笔记
- 机器学习平台 PAI学习
- 机器学习平台 PAI实践
- 机器学习平台 PAI决策
- 机器学习平台 PAIai
- 机器学习平台 PAI部署
- 机器学习平台 PAI网络
- 机器学习平台 PAI线性回归