
【Python机器学习】文本特征提取及文本向量化讲解和实战(图文解释 附源码)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~文本提取及文本向量化词频和所谓的Tf-idf是传统自然语言处理中常用的两个文本特征。以词频特征和Tf-idf特征为基础,可以将一段文本表示成一个向量。将多个文本向量化后,然后就可以运用向量距离计算方法来比较它们的相似性、用聚类算法来分析它们的自然分组。如果文本有标签,比如新闻类、军事类、财经类等等,那么还可以用它们来训练一个分类模型,用于对未知....

【Python机器学习】朴素贝叶斯分类的讲解及预测决策实战(图文解释 附源码)
需要代码请点赞关注收藏后评论区留言私信~~~朴素贝叶斯分类朴素贝叶斯(naïve Bayes)分类是基于贝叶斯定理与特征条件独立假定的分类方法。设试验E的样本空间为S,A为E的事件,B_1,B_2,⋯,B_n为S的一个划分,且P(A)>0,P(B_i)>0(i=1,2,…,n),则贝叶斯公式为:P(B_i)称为先验概率,即分类B_i发生的概率,它和条件概率P(A│B_i)可从样本集中....

【Python机器学习】过拟合及其抑制方法讲解及实战(图文解释 附源码)
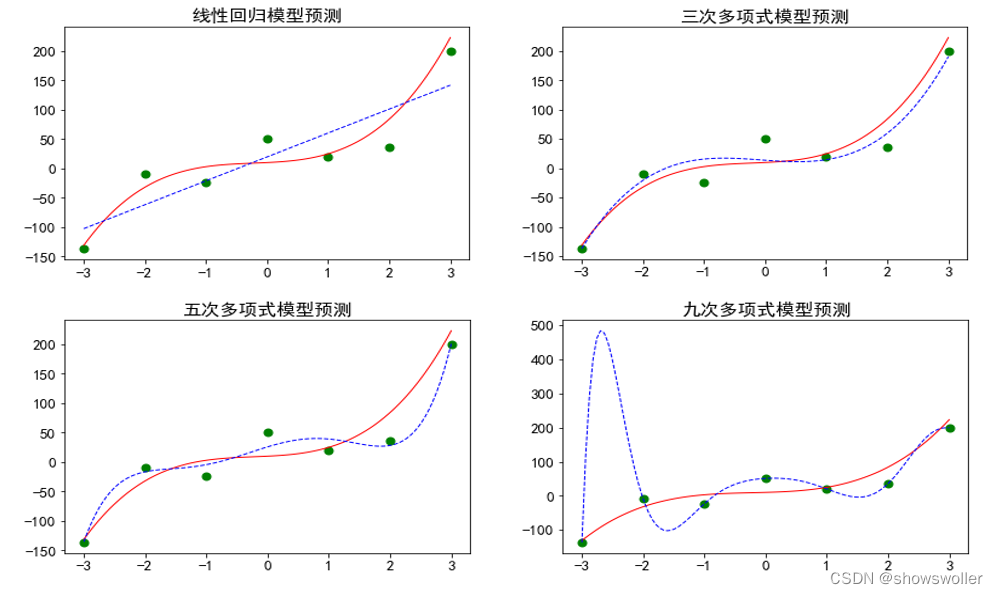
需要源码请点赞关注收藏后评论区留言私信~~~欠拟合、过拟合与泛化能力欠拟合最简单的线性模型,它是用一条直线来逼近各个样本点,显然力不从心,这种现象称为欠拟合。欠拟合模型是由于模型复杂度不够,训练样本集容量不够,特征数量不够,抽样分布不均衡等原因引起的不能学习出样本集中蕴含只是的模型,欠拟合问题比较容易处理,如增加模型复杂度,增加训练样本,提取更多特征等等过拟合某些情况下,越复杂的模型越能逼近样本....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
机器学习平台 PAI实战相关内容
- 机器学习平台 PAI实战数字识别
- 实战机器学习平台 PAI
- 机器学习平台 PAI实战sklearn
- 机器学习平台 PAI实战工业蒸汽
- 机器学习平台 PAI实战附源码数据集
- 机器学习平台 PAI k近邻实战
- 机器学习平台 PAI k近邻实战源码
- 机器学习平台 PAI实战附源码
- 机器学习平台 PAI kmeans聚类实战
- 机器学习平台 PAI案例实战
- 机器学习平台 PAI实战教程
- 机器学习平台 PAI实战应用案例
- 机器学习平台 PAI实战分类
- 机器学习平台 PAI实战k-means
- 机器学习平台 PAI实战工业蒸汽版本
- 机器学习平台 PAI竞赛实战
- 机器学习平台 PAI实战逻辑回归
- 机器学习平台 PAI实战kaggle
- 机器学习平台 PAI实战朴素贝叶斯
- 机器学习平台 PAI实战决策树算法
- 机器学习平台 PAI实战决策树算法代码
- 机器学习平台 PAI人机交互实战
- 阿旭机器学习平台 PAI实战
- 阿旭机器学习平台 PAI实战糖尿病
- 阿旭机器学习平台 PAI实战逻辑斯蒂回归
- 阿旭机器学习平台 PAI实战图片
- 机器学习平台 PAI实战线性
- 阿旭机器学习平台 PAI实战线性
- 机器学习平台 PAI实战决策原理
- 机器学习平台 PAI原理实战线性回归
机器学习平台 PAI更多实战相关
- 阿旭机器学习平台 PAI实战knn
- 机器学习平台 PAI实战xgboost
- 机器学习平台 PAI实战波士顿房价boston housing
- 机器学习平台 PAI实战实践
- 机器学习平台 PAI k-nearest实战
- 机器学习平台 PAI实战项目
- 机器学习平台 PAI实战特征工程
- 机器学习平台 PAI实战项目电商销量预估
- 机器学习平台 PAI实战近邻算法
- sls机器学习平台 PAI实战时序
- 机器学习平台 PAI实战logistic
- arduino家居安全系统构建实战机器学习平台 PAI
- 机器学习平台 PAI实战machine learning action
- 机器学习平台 PAI实战数据
- sls机器学习平台 PAI实战时序异常检测
机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI scikit-learn
- 机器学习平台 PAI python
- 机器学习平台 PAI代码
- 机器学习平台 PAI论文
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI模型
- 机器学习平台 PAI构建
- 机器学习平台 PAI升级
- 机器学习平台 PAIpai
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI数据
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI方法
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI分类
- 机器学习平台 PAI平台
- 机器学习平台 PAI笔记
- 机器学习平台 PAI学习
- 机器学习平台 PAI特征
- 机器学习平台 PAI实践
- 机器学习平台 PAI决策
- 机器学习平台 PAIai
- 机器学习平台 PAI部署
- 机器学习平台 PAI网络