
【Python机器学习】KNN进行水果分类和分类器实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~KNN算法简介KNN(K-Nearest Neighbor)算法是机器学习算法中最基础、最简单的算法之一。它既能用于分类,也能用于回归。KNN通过测量不同特征值之间的距离来进行分类。KNN算法的思想非常简单:对于任意n维输入向量,分别对应于特征空间中的一个点,输出为该特征向量所对应的类别标签或预测值。KNN算法是一种非常特别的机器学习算法,因为....
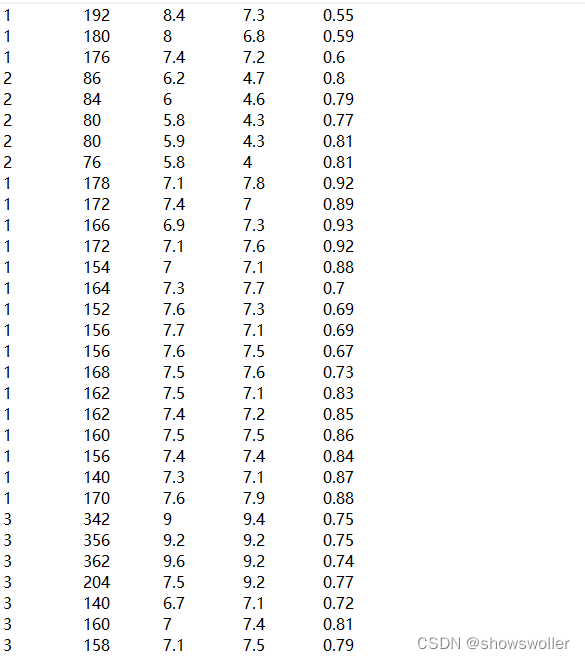
【Python机器学习】K-Means算法对人脸图像进行聚类实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~K-Mean算法,即 K 均值算法,是一种常见的聚类算法。算法会将数据集分为 K 个簇,每个簇使用簇内所有样本均值来表示,将该均值称为“质心”。算法步骤K-Means容易受初始质心的影响;算法简单,容易实现;算法聚类时,容易产生空簇;算法可能收敛到局部最小值。通过聚类可以实现:发现不同用户群体,从而可以实现精准营销;对文档进行划分;社交网络中,....

【Python机器学习】决策树、K近邻、神经网络等模型对Kaggle房价预测实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~超参数调优超参数调优需要依靠试验的方法,以及人的经验。对算法本身的理解越深入,对实现算法的过程了解越详细,积累了越多的调优经验,就越能够快速准确地找到最合适的超参数试验的方法,就是设置了一系列超参数之后,用训练集来训练并用验证集来检验,多次重复以上过程,取效果最好的超参数。训练数据的划分可以采用保持法,也可以采用K-折交叉验证法。超参数调优的试....

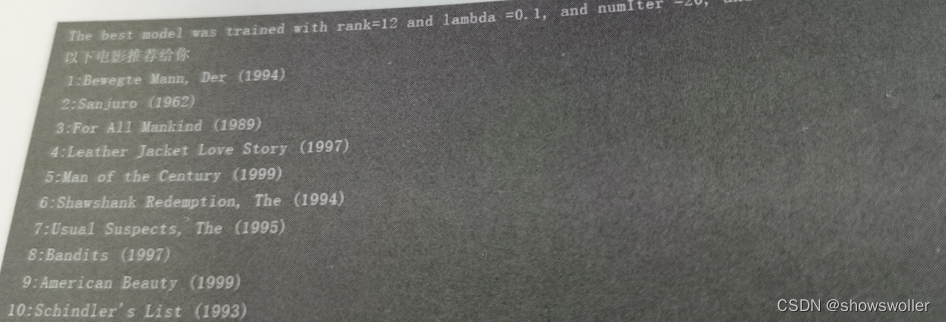
【大数据技术】Spark MLlib机器学习协同过滤电影推荐实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~协同过滤————电影推荐协同过滤是利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。在协同过滤算法中有着两个分支,分别是基于群体用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。在电影推荐系统中,通常分为针对用户推荐电影和针对电影推荐用户两种方式。若采用基于用户的推荐模型,则会利用相似用户的评级来计算对某个用户的推....
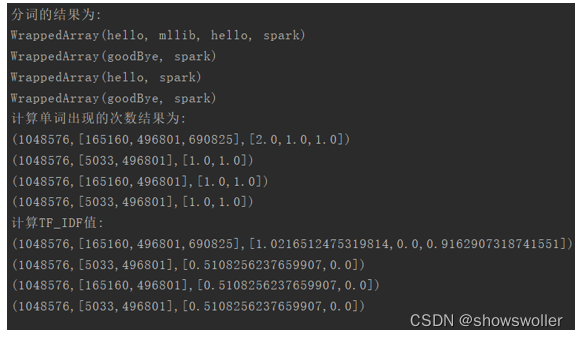
【大数据技术】Spark MLlib机器学习特征抽取 TF-IDF统计词频实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~特征抽取 TF-IDFTF-IDF是两个统计量的乘积,即词频(Term Frequency, TF)和逆向文档频率(Inverse Document Frequency, IDF)。它们各自有不同的计算方法。TF是一个文档(去除停用词之后)中某个词出现的次数。它用来度量词对文档的重要程度,TF越大,该词在文档中就越重要。IDF逆向文档频率,是指....
【Python机器学习】条件随机场模型CRF及在中文分词中实战(附源码和数据集)
需要源码请点赞关注收藏后评论区留言私信~~~基本思想假如有另一个标注序列(代词 动词 名词 动词 动词),如何来评价哪个序列更合理呢?条件随机场的做法是给两个序列“打分”,得分高的序列被认为是更合理的。既然要打分,那就要有“评价标准”,称为特征函数。例如,可以定义相邻两个词的词性的关系为一个特征函数,那么对于“语言 处理”来说,上文提到的两个序列分别标注为“名词 动词”和“动词 动词”。从语言学....
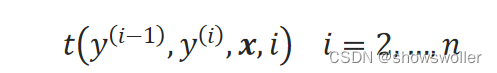
【Python机器学习】隐马尔可夫模型讲解及在中文分词中的实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~隐马尔可夫模型(HMM)是关于时序的概率模型,它可用于标注等问题中基本思想假设一个盒子里可以装两个骰子,骰子的种类有四面的和六面的两种。现在进行猜骰子实验,该实验由实验者和分析者完成。实验者每次随机从盒子中取出一个骰子,然后补入一个另外种类的骰子。实验者记录下每次实验后盒子中不同种类骰子的数量,可得到一个盒子状态的序列。实验者在每次实验后掷一次....
【Python机器学习】卷积神经网络Vgg19模型预测动物类别实战(附源码和数据集)
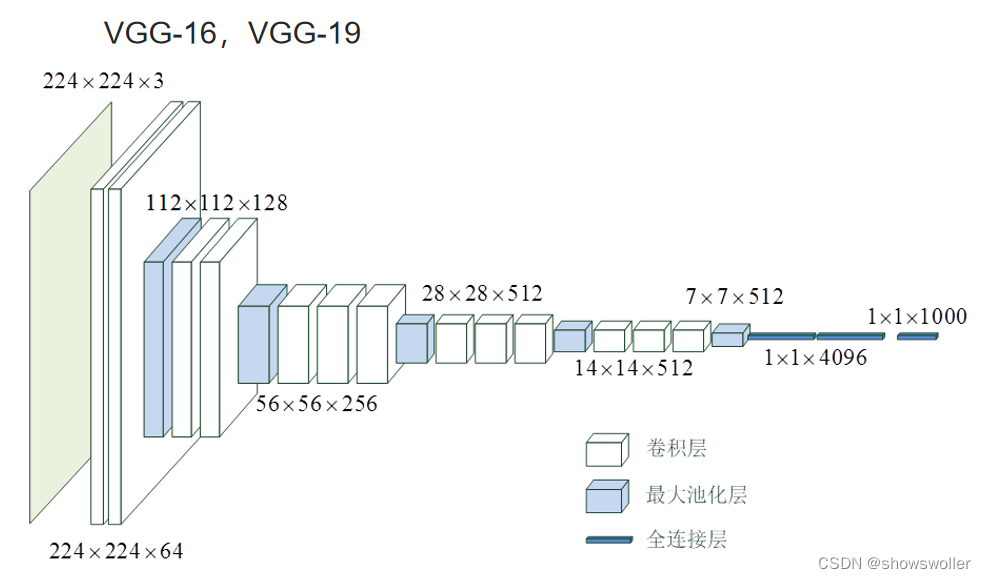
需要源码和数据集请点赞关注收藏后评论区留言私信~~~典型神经网络在深度学习的发展过程中,出现了很多经典的卷积神经网络,它们对深度学习的学术研究和工业生产斗起到了促进的作用,如VGG ResNet Inception DenseNet等等,很多实际使用的卷积神经网络都是在它们的基础上进行改进的,下面主要讨论VGG卷积神经网络VGG-16是共16层的卷积神经网络,有大约1.38亿个网络参数网络结构图....
【Python机器学习】Mean Shift、Kmeans聚类算法在图像分割中实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~Mean Shift算法是根据样本点分布密度进行迭代的聚类算法,它可以发现在空间中聚集的样本簇。簇中心是样本点密度最大的地方。Mean Shift算法寻找一个簇的过程是先随机选择一个点作为初始簇中心,然后从该点开始,始终向密度大的方向持续迭代前进,直到到达密度最大的位置。然后在剩下的点里重复以上过程,找到所有簇中心。如何找到密度大的方向并前进多....
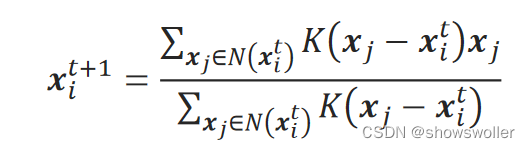
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
机器学习平台 PAI实战相关内容
- 机器学习平台 PAI实战数字识别
- 实战机器学习平台 PAI
- 机器学习平台 PAI实战sklearn
- 机器学习平台 PAI实战工业蒸汽
- 机器学习平台 PAI实战解释附源码
- 机器学习平台 PAI k近邻实战
- 机器学习平台 PAI k近邻实战源码
- 机器学习平台 PAI实战附源码
- 机器学习平台 PAI kmeans聚类实战
- 机器学习平台 PAI案例实战
- 机器学习平台 PAI实战教程
- 机器学习平台 PAI实战应用案例
- 机器学习平台 PAI实战分类
- 机器学习平台 PAI实战k-means
- 机器学习平台 PAI实战工业蒸汽版本
- 机器学习平台 PAI竞赛实战
- 机器学习平台 PAI实战逻辑回归
- 机器学习平台 PAI实战kaggle
- 机器学习平台 PAI实战朴素贝叶斯
- 机器学习平台 PAI实战决策树算法
- 机器学习平台 PAI实战决策树算法代码
- 机器学习平台 PAI人机交互实战
- 阿旭机器学习平台 PAI实战
- 阿旭机器学习平台 PAI实战糖尿病
- 阿旭机器学习平台 PAI实战逻辑斯蒂回归
- 阿旭机器学习平台 PAI实战图片
- 机器学习平台 PAI实战线性
- 阿旭机器学习平台 PAI实战线性
- 机器学习平台 PAI实战决策原理
- 机器学习平台 PAI原理实战线性回归
机器学习平台 PAI更多实战相关
- 阿旭机器学习平台 PAI实战knn
- 机器学习平台 PAI实战xgboost
- 机器学习平台 PAI实战波士顿房价boston housing
- 机器学习平台 PAI实战实践
- 机器学习平台 PAI k-nearest实战
- 机器学习平台 PAI实战项目
- 机器学习平台 PAI实战特征工程
- 机器学习平台 PAI实战项目电商销量预估
- 机器学习平台 PAI实战近邻算法
- sls机器学习平台 PAI实战时序
- 机器学习平台 PAI实战logistic
- arduino家居安全系统构建实战机器学习平台 PAI
- 机器学习平台 PAI实战machine learning action
- 机器学习平台 PAI实战数据
- sls机器学习平台 PAI实战时序异常检测
机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI scikit-learn
- 机器学习平台 PAI python
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI模型
- 机器学习平台 PAI构建
- 机器学习平台 PAI升级
- 机器学习平台 PAIpai
- 机器学习平台 PAI配置
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI数据
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI方法
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI分类
- 机器学习平台 PAI平台
- 机器学习平台 PAI代码
- 机器学习平台 PAI笔记
- 机器学习平台 PAI学习
- 机器学习平台 PAI特征
- 机器学习平台 PAI实践
- 机器学习平台 PAI决策
- 机器学习平台 PAIai
- 机器学习平台 PAI部署
- 机器学习平台 PAI网络
