
数据湖的选型(delta iceberg hudi)以及比对
数据湖的选型此文章只是作为文稿记录,且截止到2022年11月份Hudi(0.12.0)支持spark 3.3.x 3.1.x是 Hadoop Upserts Deletes and Incrementals 的简写Hudi在华为的实践1。clustering支持常见的order以及z-order(里面以后优化https://github.com/delta-io/delta/pull/1149)....
数据湖选型指南|Hudi vs Iceberg 数据更新能力深度对比
数据湖作为新一代大数据基础设施,近年来持续火热,许多前线的同学都在讨论数据湖应该怎么建,许多企业也都在构建或者计划构建自己的数据湖。基于此,自然引发了许多关于数据湖选型的讨论和探究。但是经过搜索之后我们发现,网上现存的很多内容都是基于较早之前的开源信息做出的结论,在企业调研初期容易造成不准确的印象和理解。因此带着这样的问题,我们计划推出数据湖选型系列文章,基于最新的开源信息,从升级数据湖架构的几....
数据湖存储架构选型
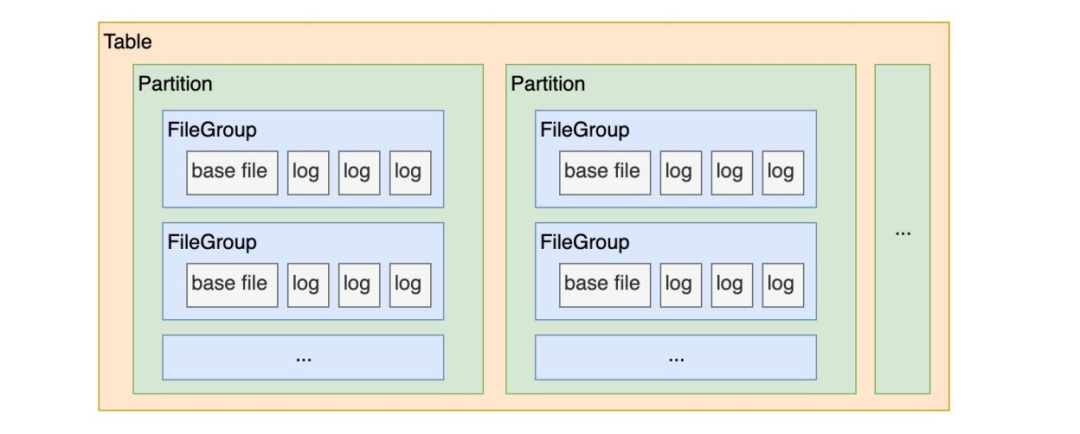
本文内容来自由阿里云计算平台事业部与阿里云开发者社区联合主办的大数据+AI meetup 2020第二站·上海讲师郑锴的分享《数据湖存储架构选型》 一、数据湖是个潮流 简单来讲,数据湖的理念就是说从一个企业的视角来讲,把整个数据集中的统一的存储在一起,主要通过 BI 和 AI 的手段来计算分析原始的数据。数据的类型不光是结构化、半结构化的,还包括音视频,这样的一些材料。 我们为什么要基于数据...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
