
Apache Flink SQL概览
本篇核心目标是让大家概要了解一个完整的Apache Flink SQL Job的组成部分,以及Apache Flink SQL所提供的核心算子的语义,最后会应用Tumble Window编写一个End-to-End的页面访问的统计示例。 Apache Flink SQL Job的组成 我们做任何数据计算都离不开读取原始数据,计算逻辑和写入计算结果数据三部分,当然基于Apache Flink SQ....
Apache Spark 系列技术直播 - Spark SQL进阶与实战
Spark SQL进阶与实战 Spark相关组件介绍 Spark及其依赖组件 Hive Metastore介绍 Spark Thrift Server介绍 表与ETL Spark表基本概念 Spark建表最佳实践 Spark ETL最佳实践 动态分区表示例分析 Spark SQL查询最佳实践 Spark SQL查询常见问题 Join优化策略 数据倾斜优化策略 详情请查看附件 欢迎加...
Apache Spark 系列技术直播 - Spark SQL 实践与优化
直播回看点我 Apache Spark 系列技术直播 Spark SQL 实践与优化 内容简介: SparkSQL介绍 基本原理 支持的DataSource介绍 Hue/Zepplin/Livy周边跟SparkSQL的集成使用等 SparkSQL优化 SparkSQL Catalyst优化 AE优化 Shuffle优化 直播时间: 2018.11.27 周二 晚 19:00 ...
Apache Flink 漫谈系列(08) - SQL概览
SQL简述 SQL是Structured Query Language的缩写,最初是由美国计算机科学家Donald D. Chamberlin和Raymond F. Boyce在20世纪70年代早期从 Early History of SQL 中了解关系模型后在IBM开发的。该版本最初称为[SEQUEL: A Structured English Query Language](结构化英语查询语....
Apache Kudu & Apache Spark SQL for Fast Analytics on Fast Data
在SPARK SUMMIT 2017上,Mike Percy Software Engineer at Cloudera Apache Kudu PMC member分享了题为《Apache Kudu & Apache Spark SQL for Fast Analytics on Fast Data》,就Kudu概述,Apache Kudu的使用性能等方面的内容做了深入的分析。 http...
Apache Phoenix and HBase: Past, Present and Future of SQL over HBase
在Hadhoop summit 2016上,Enis Soztutar,Committer and PMC member in Apache HBase, Phoenix, and Hadoop分享了题为《Apache Phoenix and HBase: Past, Present and Future of SQL over HBase》,就Phoenix基础,Phoenix功能概述,Pho....
Major advancements in Apache Hive towards full support of SQL compliance
在Hadhoop summit 2016上,Pengcheng Xiong and Ashutosh Chauhan Hortonworks Inc., Apache Hive Community {pxiong,ashutosh分享了题为《Major advancements in Apache Hive towards full support of SQL compliance》,就SQL....
原生SQL on Hadoop引擎- Apache HAWQ 2.x最新技术解密malili
马丽丽在2017第八届数据库大会上做了题为《原生SQL on Hadoop引擎- Apache HAWQ 2.x最新技术解密malili》的分享,就Apache HAWQ 历史,系统架构,最新功能介绍做了深入的分析。 https://yq.aliyun.com/download/458?spm=a2c4e.11154804.0.0.10a76a79mhx3cu
Apache Phoenix学习记录(SQL on HBase)
1 使用概述 Phoenix是基于HBase的SQL中间件产品,由Salesforce.com公司开源并托管于Github上。对于熟悉关系型数据库的开发人员来说,通过Phoenix可以像使用MySQL等关系型数据库一样使用HBase中的数据表。值得注意的是,它还提供了JDBC驱动包供Java程序访问数据。在实现时,充分利用了HBase协处理器和过滤器等底层 2 环境配置 首先需要安...
KSQL,用于Apache Kafka的流数据SQL引擎
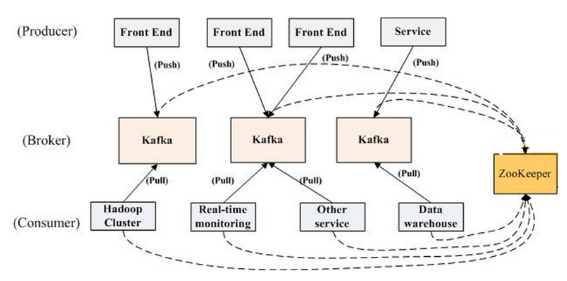
Apache Kafka是一个分布式的、分区的、多复本的日志提交服务,使用Scala编写,以可水平扩展和高吞吐率而被广泛使用。Kafka最初是由LinkedIn开发,并于2011年初开源,目标是为实时数据处理提供一个统一、高通量、低等待的平台。目前,越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。 Kafka拓扑结构 Kafka的设...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache您可能感兴趣
- Apache智能
- Apache data
- Apache流处理
- Apache升级
- Apache flink
- Apache iceberg
- Apache数据湖
- Apache性能
- Apache调优
- Apache孵化器
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache doris
- Apache服务
- Apache报错
- Apache mysql
- Apache微服务
- Apache访问
- Apache kafka
- Apache从入门到精通
- Apache hudi
- Apache实践

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注