
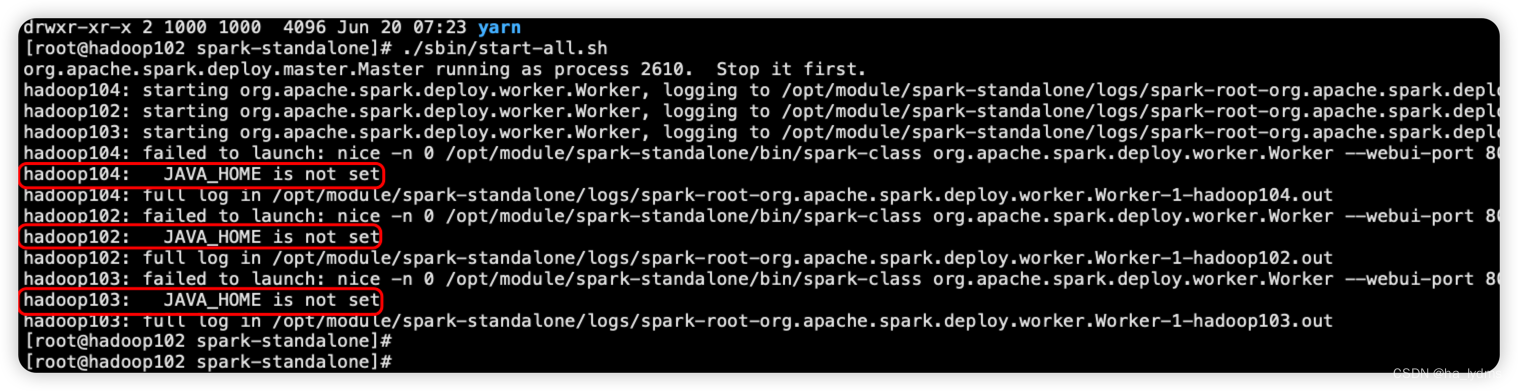
Spark 启动时,报JAVA_HOME is not set
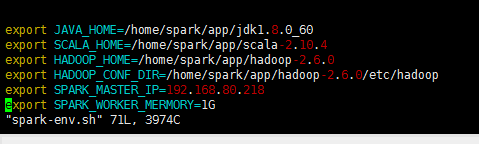
1、报错内容Spark启动时报错:hadoop104: JAVA_HOME is not set2、解决方式解决方式:打开启动配置文件cd /opt/module/spark-standalone/sbin/ vim spark-config.sh配置Java的环境变量#JAVA_HOME export JAVA_HOME=/usr/local/java/jdk1.8.0_181 expor...
Spark Shell启动时遇到:14: error: not found: value spark import spark.implicits._ :14: error: not found: value spark import spark.sql错误的解决
这里我,使用的是spark-2.2.0-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz 的单节点来测试下。 其中,hadoop-2.6.0的单节点配置文件,我就不赘述了。 这里,我重点写下spark on yarn。我这里采取的是这模式。 spark-defaults.conf 默认,保持不修改。 &nbs...
Spark 启动时,提示 JAVA_HOME not set,已解决。。。
在spark 根目录使用 sbin/start-all.sh 时,console提示 slave JAVA_HOME not set, 找了半天,最后的解决方法如下: 在sbin目录下的spark-config.sh 中添加对应的jdk 路径,然后使用scp -r 命令复制到各个worker节点,即可。。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark启动时相关内容
apache spark您可能感兴趣
- apache spark日志
- apache spark分析
- apache spark应用
- apache spark OSS
- apache spark机制
- apache spark缓存
- apache spark rdd
- apache spark湖仓
- apache spark lakehouse
- apache spark构建
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark操作
- apache spark技术
- apache spark yarn
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注