
Python 爬虫必备杀器,xpath 解析 HTML
XPath 简介 XPath(XML Path Language)是一种用于在 XML 和 HTML 文档中定位节点的语言。它使用路径表达式来选取 XML/HTML 文档中的节点或者节点集。虽然它是为 XML 设计的,但由于 HTML 可以看作是 XML 的一种应用(XHTML),所以 XPath 也非常适合用于解析 HTML 文档。 例如,一个简单的 H...
Sphinx是一个Python文档生成工具,它可以解析reStructuredText或Markdown格式的源代码注释,并生成多种输出格式,如HTML、LaTeX、PDF、ePub等。
Sphinx简介 Sphinx是一个Python文档生成工具,它可以解析reStructuredText或Markdown格式的源代码注释,并生成多种输出格式,如HTML、LaTeX、PDF、ePub等。Sphinx特别适用于生成API文档,因为它能够自动从Python的docstrings中提取信息。 Sphinx基本使用 安装Sphin...
怎么用Python解析HTML轻松搞定网页数据
HTML(Hypertext Markup Language)是互联网世界中的通用语言,用于构建网页。在许多应用程序和任务中,需要从HTML中提取数据、分析页面结构、执行网络爬取以及进行网页分析。Python是一种功能强大的编程语言,拥有众多库和工具,可以用于HTML解析。 本文将详细介绍如何使用Python解析HTML,包括各种方法和示例代码。 为什么解析HTML? H...

在阿里云RPA Python 编码如何通过解析HTML 获取表格内容 有事例吗?
在阿里云RPA Python 编码如何通过解析HTML 获取表格内容 有事例吗?
Python爬虫:scrapy内置网页解析库parsel-通过css和xpath解析xml、html
文档https://pypi.org/project/parsel/https://github.com/scrapy/parsel安装pip install parsel代码示例from parsel import Selector selector = Selector(text="""<html> <body> <h1&...
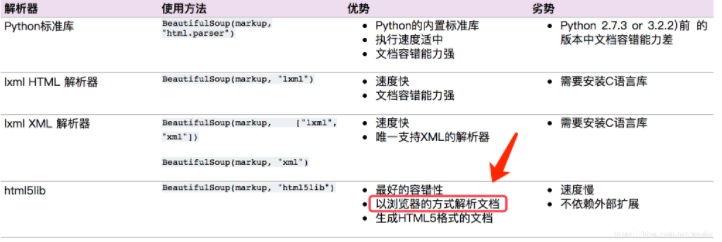
Python爬虫:scrapy利用html5lib解析不规范的html文本
问题当爬取表格(table) 的内容时,发现用 xpath helper 获取正常,程序却解析不到在chrome、火狐测试都有这个情况。出现这种原因是因为浏览器会对html文本进行一定的规范化scrapy 使用的解析器是 lxml ,下面使用lxml解析,只是函数表达不一样,xpath和css选择器的语法一样安装解析器pip install beautifulsoup4 lxml html5li....
python模块之 HTMLParser: 解析html,获取url
HTMLParser是python用来解析html的模块。它可以分析出html里面的标签、数据等等,是一种处理html的简便途径。 HTMLParser采用的是一种事件驱动的模式,当HTMLParser找到一个特定的标记时,它会去调用一个用户定义的函数,以此来通知程序处理。它 主要的用户回调函数的命名都是以handler_开头的,都是HTMLParser的成员函数。当我们使用时,就从HTMLPa....
Python 用HTMLParser解析HTML文件
HTMLParser是Python自带的模块,使用简单,能够很容易的实现HTML文件的分析。 本文主要简单讲一下HTMLParser的用法. 使用时需要定义一个从类HTMLParser继承的类,重定义函数: handle_starttag( tag, attrs) handle_startendtag( tag, attrs) handle_endtag( tag) 来实现自己需...
python模块学习---HTMLParser(解析HTML文档元素)
HTMLParser是Python自带的模块,使用简单,能够很容易的实现HTML文件的分析。 本文主要简单讲一下HTMLParser的用法. 使用时需要定义一个从类HTMLParser继承的类,重定义函数:handle_starttag( tag, attrs)handle_startendtag( tag, attrs)handle_endtag( tag)来实现自己需要的功能。tag是的ht....
用python解析html
python中,有三个库可以解析html文本,HTMLParser,sgmllib,htmllib。他们的实现方法不通,但功能差不多。这三个库中 提供解析html的类都是基类,本身并不做具体的工作。他们在发现的元件后(如标签、注释、声名等),会调用相应的函数,这些函数必须重载,因为基类中不 作处理。 比如: """<html><head><title&g...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云解析DNSpython相关内容
- python云解析DNS
- 构建python云解析DNS
- python爬虫云解析DNS
- python手册云解析DNS
- python协程云解析DNS
- 云解析DNS python web
- python web云解析DNS
- python库云解析DNS
- 应用python云解析DNS
- python技术云解析DNS
- python云解析DNS实践
- python框架云解析DNS
- python json云解析DNS
- python云解析DNS代码
- python命令行参数云解析DNS
- python xpath云解析DNS
- python字典云解析DNS
- python爬虫pyquery模块云解析DNS网页
- python云解析DNS字符串abc def列表
- python if name main云解析DNS

