
带你读《全链路数据治理-全域数据集成》之29:3. 准备工作:添加数据源
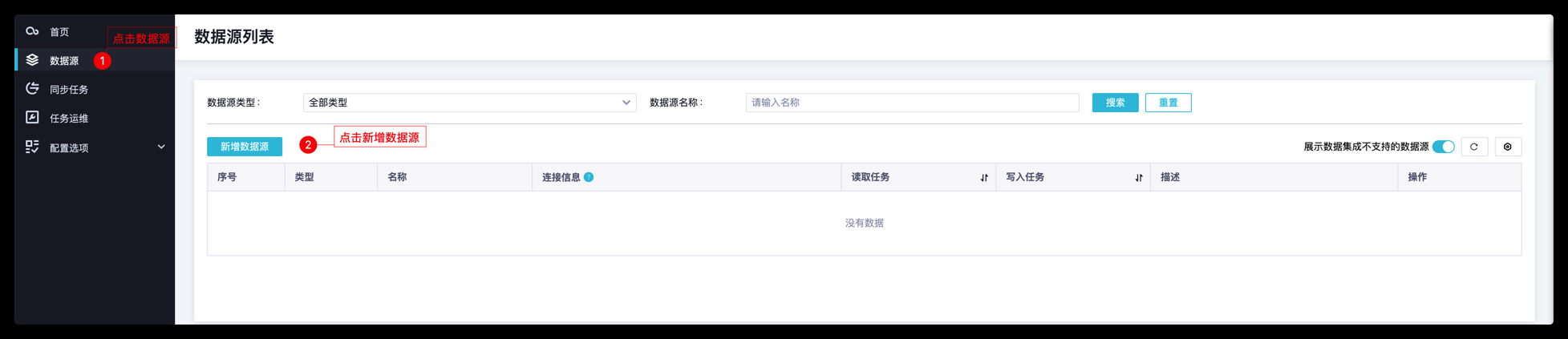
3. 准备工作:添加数据源1) 新建 MySQL 数据源如果您的数据源,为云上 RDS 数据库,可以选择创建阿里云实例类型。 如果您的数据源为 ECS 自建或 IDC 内,可以选择公网或 ECS 自建数据库类型。点击要同步该数据源的数据集成独享资源组测试连通性,确保数据源连通状态为“可连通”。2) 新建 Hologres 数据源测试连通性通过,并保存。
带你读《全链路数据治理-全域数据集成》之30:4. 配置任务(上)
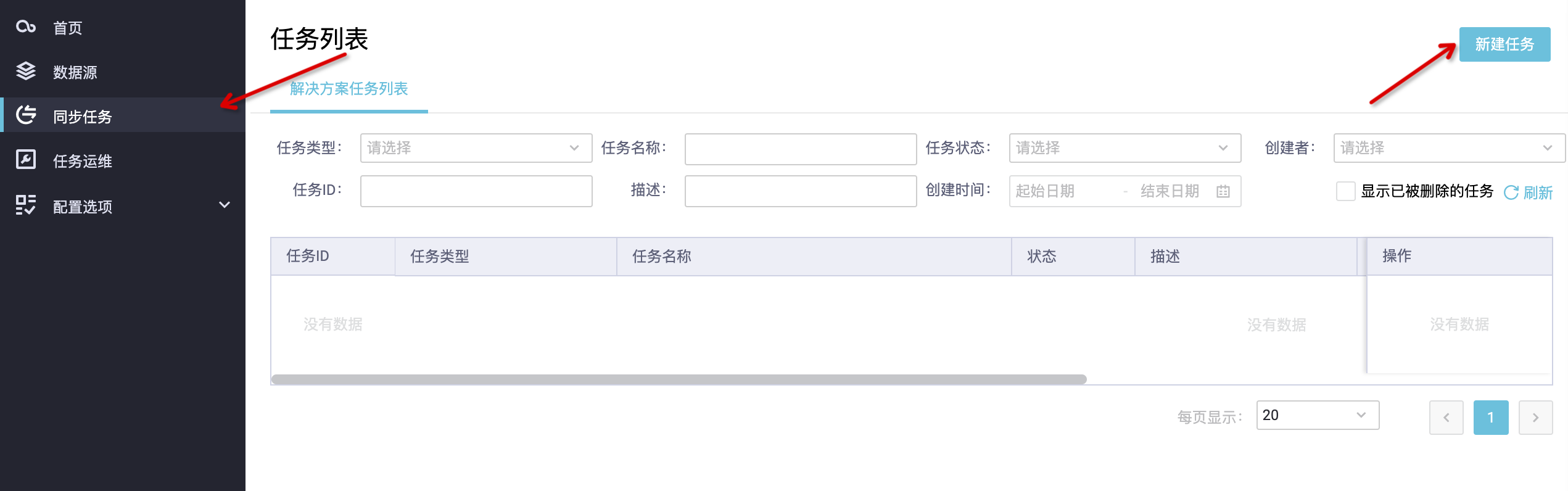
4. 配置任务1) 创建同步任务在 DataWorks 管控台进入数据集成主站,点击同步任务,新建任务。 选择 Hologres 整库全增量解决方案。、2) 选择表并刷新表映射l 左侧勾选源端需要同步的表 table_a_001、table_a_002、table_b_001、table_b_002。 l 通过穿梭框选中后移动至右侧。 l 点击批量刷新映射按钮。 提示: l 目标端 Schema....
带你读《全链路数据治理-全域数据集成》之30:4. 配置任务(下)
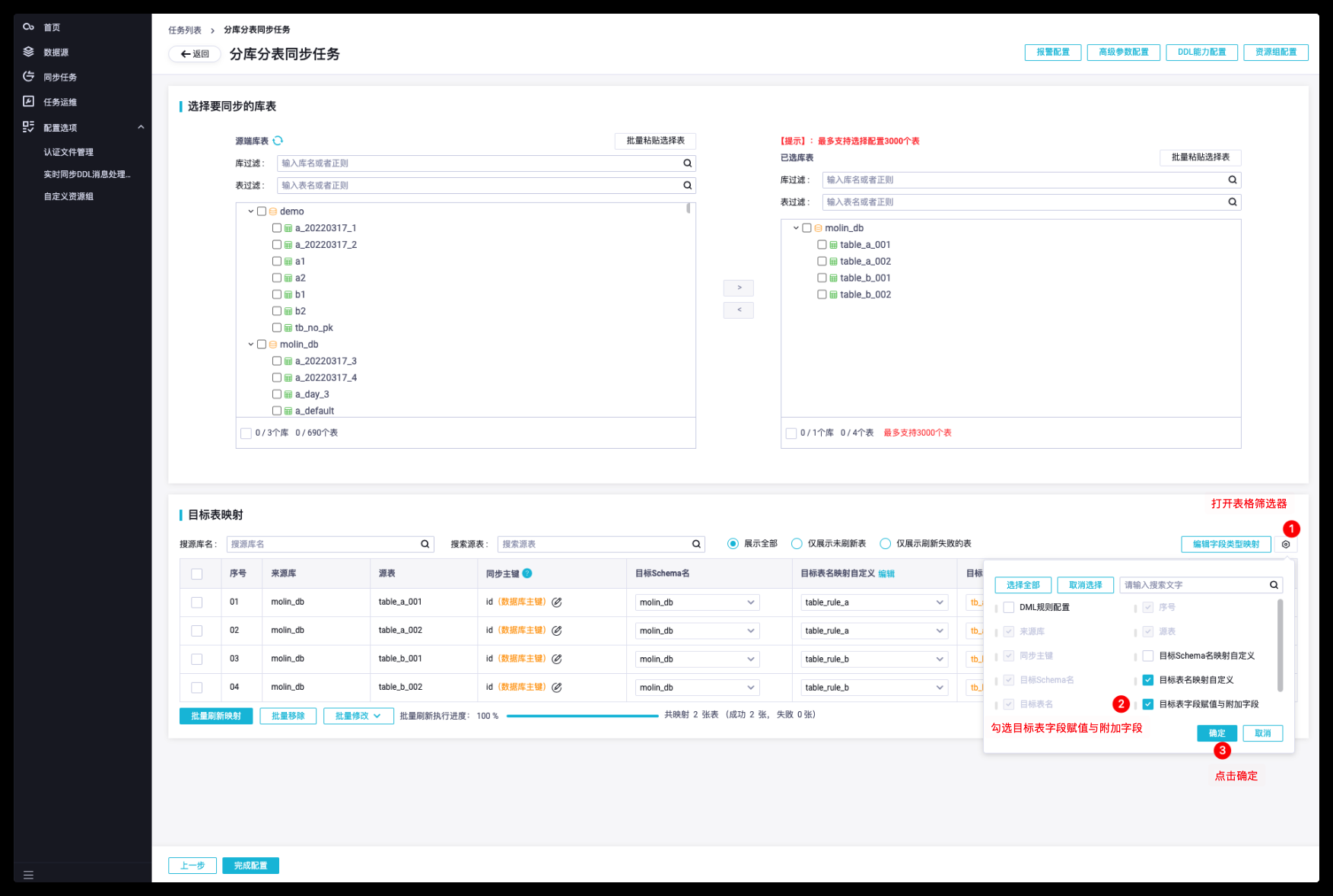
《全链路数据治理-全域数据集成》——五、分库分表至 Hologres 最佳实践——4. 配置任务(上):https://developer.aliyun.com/article/12229644) 配置附加字段 分库表至 Hologres 最佳实践 可以看到表格中,附加字段列编辑按钮后有黄色感叹号标识,表示有附加字段配置。 点击单表的编辑按钮,查看指定表的附加字段配置,可以验证批量添加附加字段是....
带你读《全链路数据治理-全域数据集成》之31:5. 任务运维
5. 任务运维1) 查看任务状态可以看到任务已经处于运行中状态,点击执行概况,可以进入任务运维页面。查看结构迁移状态。 结构迁移表格数据说明: l 目标对接方式:自动建表使用已有表。l DDL 列:鼠标悬浮可以查看建表的 SQL 语句。 l 状态列值:执行中、成功、失败,如状态为失败,鼠标悬浮可查看失败原因。 查看全量初始化状态。 全量初始化表格数据说明: l 全量进度,表示该表的全量初始化任务....

带你读《全链路数据治理-全域数据集成》之32:1. 背景信息
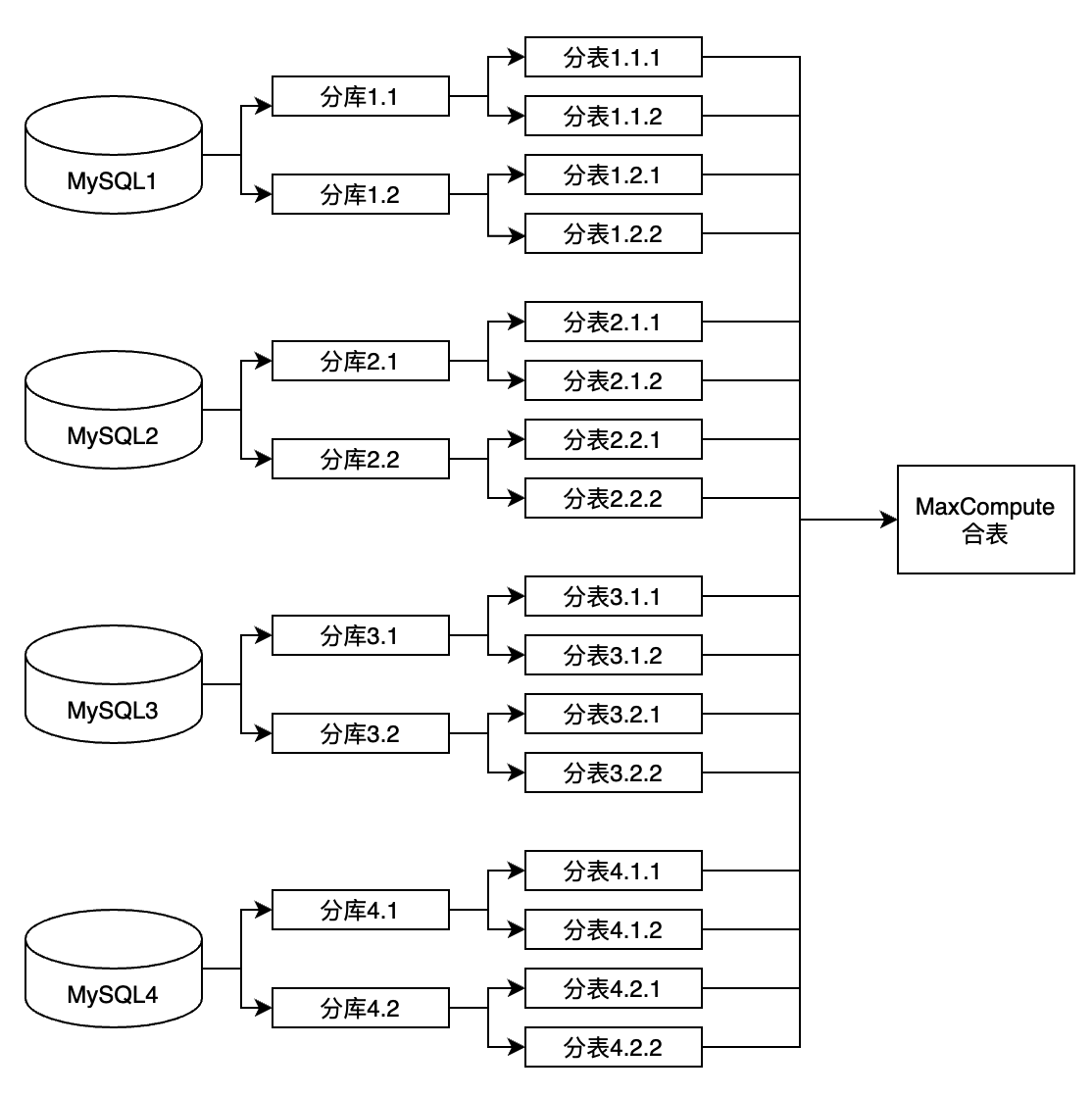
六、分库分表至 MaxCompute 实践1. 背景信息1) 业务诉求MySQL 分库分表的场景下,上游的表和库非常多,都需要同时写入一张MaxCompute 表,如果要同时配置多个任务则会导致配置非常复杂且运维困难。 针对上诉痛点,阿里云 DataWorks 数据集成分库分表同步解决方案提供了面向业务场景的同步任务配置化方案,支持不同数据源的一键同步功能,方便业务简单快速的进行数据同步。 2)....
带你读《全链路数据治理-全域数据集成》之33:2. 使用限制
2. 使用限制1) 同步资源组:分库分表同步至 MaxCompute 需要使用 DataWorks 独享数据集成资源组2) 表数量上限:l 单数据源,源库支持的数量上限为 50。l 单数据源,源表支持的数量上限为 5000。l 单同步任务逻辑表数量上限为 3000。3) 跨时区同步限制:同步解决方案暂不支持跨时区同步数据。如果同步任务中同步的数据源与使用的DataWorks 资源组不在同一个时区....
带你读《全链路数据治理-全域数据集成》之34:3. 准备工作:添加数据源
3. 准备工作:添加数据源1) 新建 MySQL 数据源新建 MySQL 数据源,支持阿里云实例模式和连接串模式。 l 阿里云实例模式:适用于阿里云 RDS For MySQL。l 连接串模式:适用于自建、公网或本地 IDC 机房 MySQL。本文以阿里云 RDS for MySQL 为例,新建数据源如下:点击要同步该数据源的数据集成独享资源组测试连通性,确保数据源连通状态为“可连通”。2) 新....

带你读《全链路数据治理-全域数据集成》之35:4.任务配置(上)
4. 任务配置 1) 创建同步任务在 DataWorks 管控台进入数据集成主站,点击同步任务,新建任务。 选择分库分表实时同步至 MaxCompute 解决方案。 2) 配置同步网络连接在数据来源中选择多个数据源,作为分库分表解决方案的数据来源,点击各个数据来源可以收缩、展开。其中多个数据源必须保持类型一致,比如都是 MySQL 数据源。 本步骤要求所选用的数据源和资源组具有网络连通性。 3)....
带你读《全链路数据治理-全域数据集成》之35:4.任务配置(中)
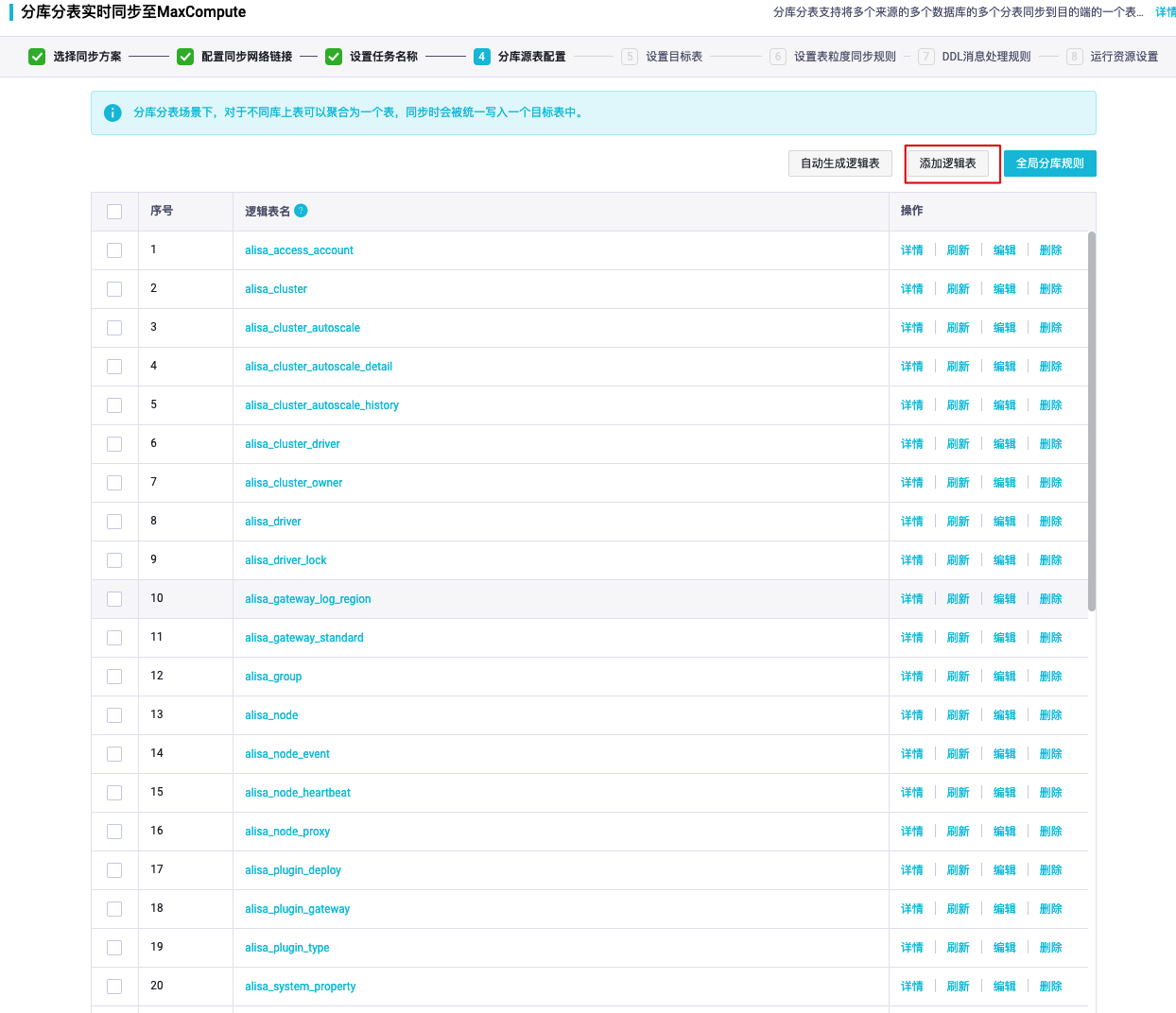
《全链路数据治理-全域数据集成》——六、分库表至 MaxCompute 实践——4.任务配置(上): https://developer.aliyun.com/article/12229396) 手动配置逻辑表在“自动生成逻辑表”与期望的匹配结果不符时,可以编辑逻辑表匹配规则,也可以通过“添加逻辑表”添加没有扫描到的逻辑表。有几个逻辑表需要同步,就在此处添加几个。同一逻辑表的数据会同步到目标表中....
带你读《全链路数据治理-全域数据集成》之35:4.任务配置(下)
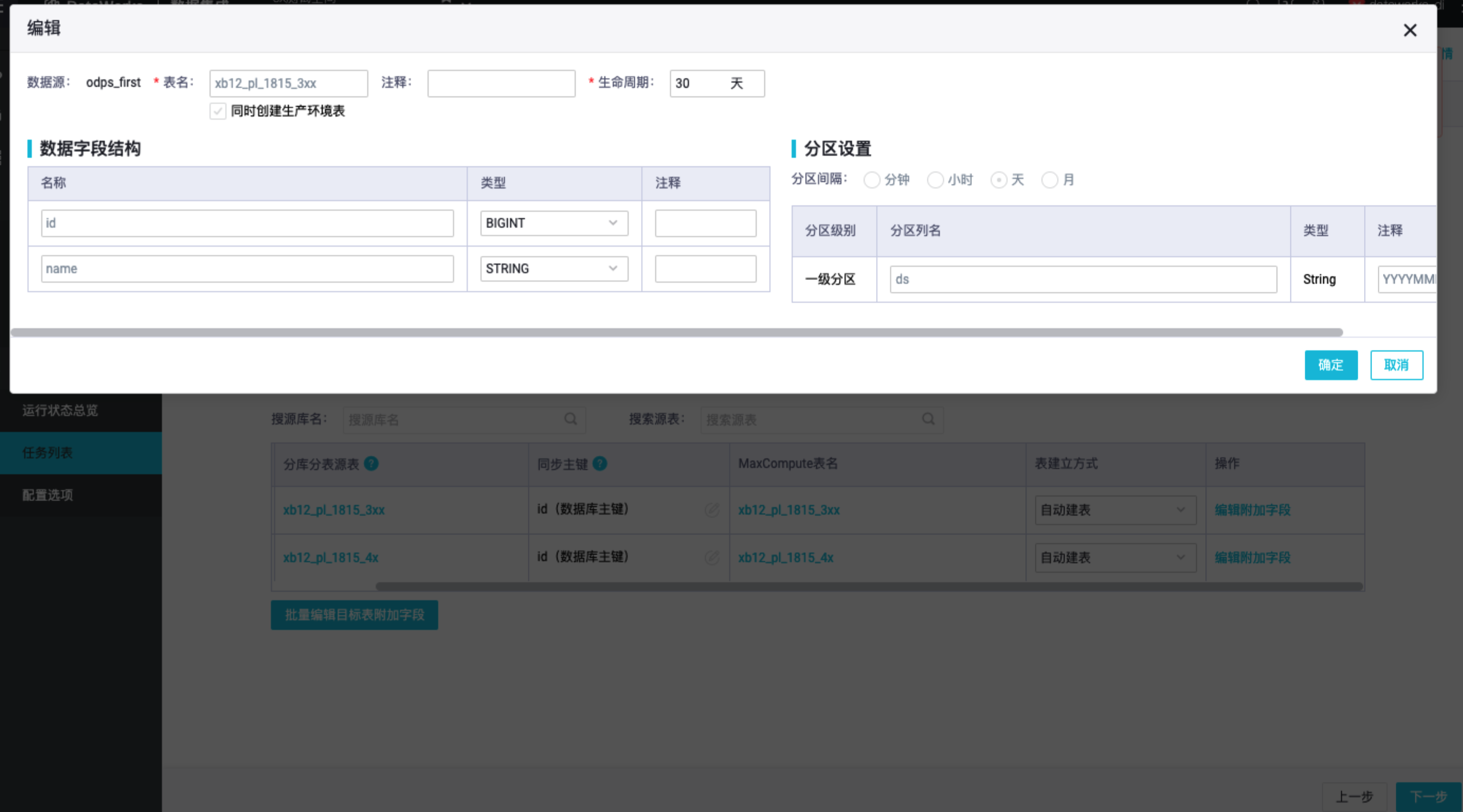
《全链路数据治理-全域数据集成》——六、分库表至 MaxCompute 实践——4.任务配置(中):https://developer.aliyun.com/article/122293410) 表结构配置默认的表生命周期为 30 天,表示 MaxCompute 只保留最近 30 天的分区数据,单击 MaxCompute 表名可以编辑这个生命周期。 11) 设置表粒度同步规则本解决方案支持配置 ....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
数据集成 Data Integration您可能感兴趣
- 数据集成 Data Integration工具
- 数据集成 Data Integration迁移
- 数据集成 Data Integration数据
- 数据集成 Data Integration hologres
- 数据集成 Data Integration同步
- 数据集成 Data Integration应用
- 数据集成 Data Integration实践
- 数据集成 Data Integration场景
- 数据集成 Data Integration自定义
- 数据集成 Data Integration transformer
- 数据集成 Data Integration dataworks
- 数据集成 Data Integration任务
- 数据集成 Data Integration资源
- 数据集成 Data Integration资源组
- 数据集成 Data Integration数据源
- 数据集成 Data Integration配置
- 数据集成 Data Integration mysql
- 数据集成 Data Integration报错
- 数据集成 Data Integration maxcompute
- 数据集成 Data Integration离线
- 数据集成 Data Integration数据库
- 数据集成 Data Integration数据同步
- 数据集成 Data Integration表
- 数据集成 Data Integration实时同步
- 数据集成 Data Integration集成
- 数据集成 Data Integration flink
- 数据集成 Data Integration字段
- 数据集成 Data Integration调度
- 数据集成 Data Integration功能
- 数据集成 Data Integration全链路
大数据开发治理DataWorks
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
+关注