
机器学习测试笔记(16)——数据处理
1.数据处理的重要性对于机器学习,选择一个好的算法是非常有用的,另外对测试集和训练集的数据进行处理也是非常重要的。通常情况下是为了消除量纲的影响。譬如一个百分制的变量与一个5分值的变量在一起怎么比较?只有通过数据标准化,都把它们标准到同一个标准时才具有可比性,一般标准化采用的是Z标准化,即均值为0,方差为1。当然也有其他标准化,比如0——1标准化等,可根据自己的数据分布情况和模型来选择。那什么情....

机器学习测试笔记(15)——神经网络
1.神经网络基础 上面这个图是动物神经的解刨图,由于神经仅有兴奋与抑制两种状态,这与计算机仅有“0”“1”两种状态相吻合,这也就是神经网络可以应用于计算机的原因。神经网络的发展历史如下:1943年,美国神经解剖学家沃伦麦克洛奇(.....

机器学习测试笔记(13)——支持向量机(下)
接下来我们看一下gamma参数。def gamma_for_RBF(): wine = datasets.load_wine() #选取数据集前两个特征 X = wine.data[:,:2] y = wine.target C = 1.0 #SVM参数正则化 models =(svm.SVC(kernel='rbf',ga...
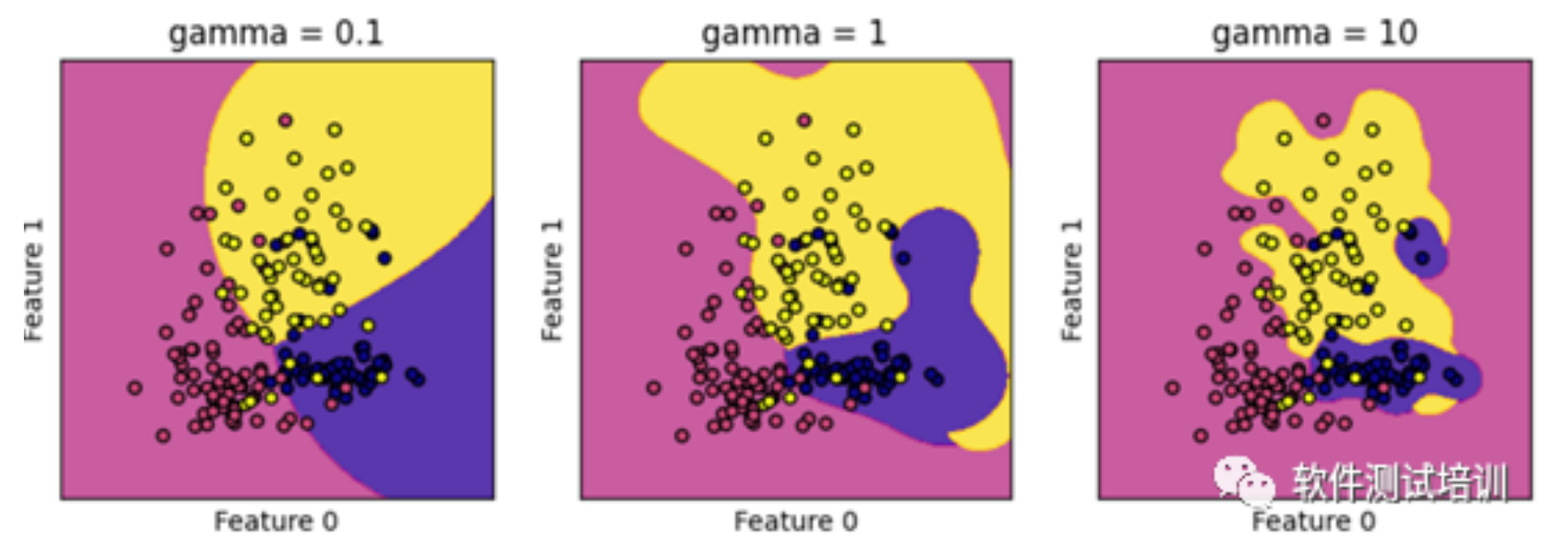
机器学习测试笔记(13)——支持向量机(上)
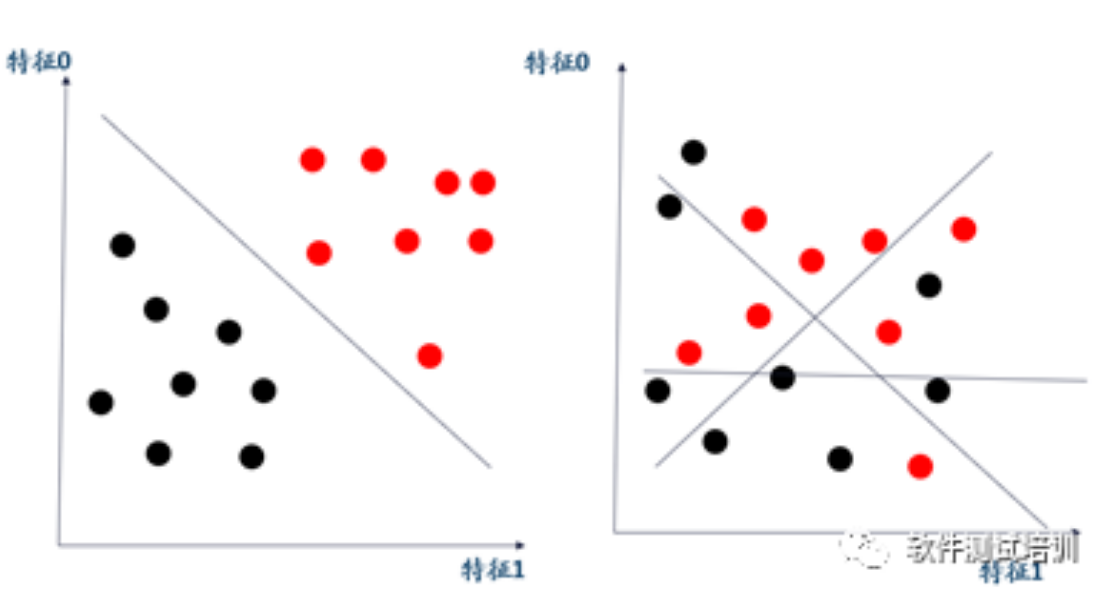
1. 线性可分与线性不可分 上图左边为线性可分的,通过一条直线就可以把两类分开;而右边是线性不可分的,如何用一条线都不能把红黑两个分离开。对于线性不可分的我们可以采取升维的方式来解决,比如有如下十个样本。红色的是一类,绿色的是另一类,它在二维平面上是线性不可....
机器学习测试笔记(14)——决策树与随机森林(下)
2.4案例下面我们通过一个案例来介绍一下随机森林的使用,案例的内容是预测某人的收入是否可以>50K。我们到http://archive.ics.uci.edu/ml/machine-learning-databases/adult/网上下载adult.dat文件,它的格式是csv文件的形式,把它改为adult.csv,可用Excel文件打开。 import pandas as p....

机器学习测试笔记(14)——决策树与随机森林(上)
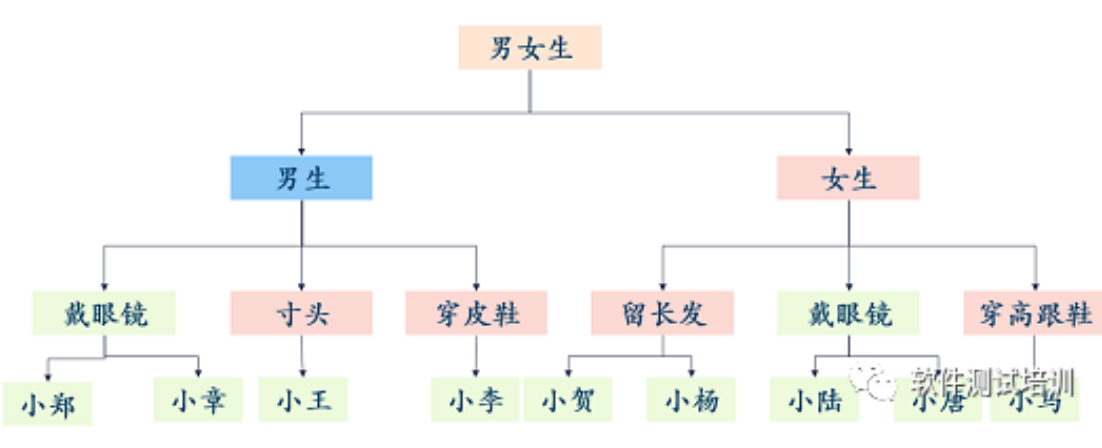
1决策树模型1.1基本概念决策树类似于我们玩的读心游戏,一个人问问题,另一个人只能回答yes或no。比如:问:这是个人吗?回答:是问:是女生吗?回答:不是问:他戴眼镜吗?回答:是…一直猜出回答者的正确答案。如下图所示。 1.2 信息增益与基尼不纯度在介绍决策树之前我们先来介绍下信息熵,信息熵是约翰·香农根据热力学第二定律,在 1948《通信的数学原理》一书中提出,主要思想是:一个问题不....
机器学习测试笔记(13)——决策树与随机森林(下)
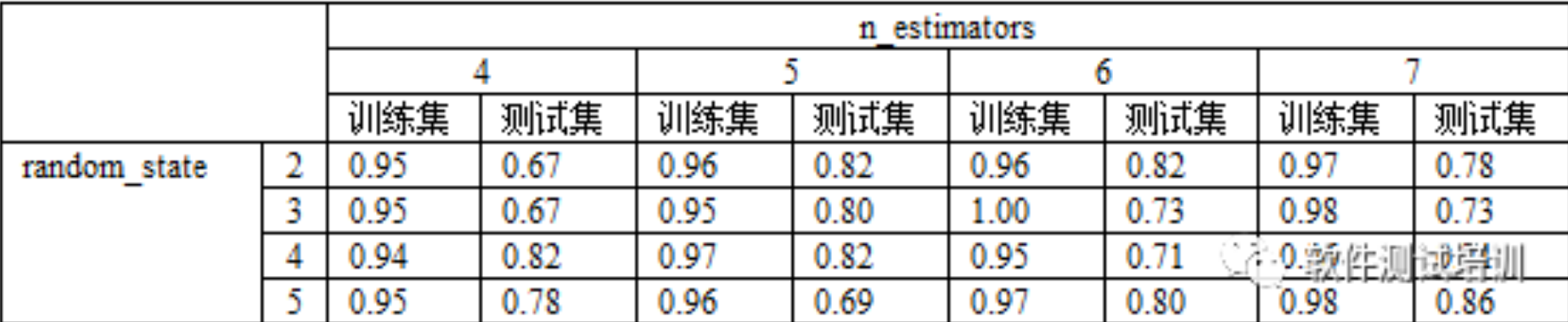
2 随机森林模型2.1基本概念2001年Breiman把分类树组合成随机森林(Breiman 2001a),即在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,再汇总分类树的结果。随机森林在运算量没有显著提高的前提下提高了预测精度。算法流程:构建决策树的个数t,单颗决策树的特征个数f,m个样本,n个特征数据集1 单颗决策树训练1.1 采用有放回抽样,从原数据集经过m次抽样,获得有....
机器学习测试笔记(9)——数据分析
1数据分析步骤2数据分析方法3数据分析工具4机器学习分类监督学习:有标签无监督学习:没标签5 数据分析库6训练方式与预测方式7机器学习三要素7.1模型7.2策略7.2.1目标函数目标函数:f(x)7.2.2损失函数目标函数:f(x)Y:真实值L(Y,f(x)]) =(Y-f(x))2损失函数值越小,效果越好7.2.3欠拟合、过拟合训练数据集上测试数据集上拟合原因不好不好欠拟合训练不佳好不好过拟合....

机器学习测试笔记(8)——分组聚合
# coding:utf-8 import numpy as np importpandas as pd1 初始化数据def init_data(): df = pd.DataFrame({'Key1':['0','1','1','0','1','0','1','1','0'],'Key2':['A','B','A','B','A','A','B','A','B'],'Dat...
机器学习测试笔记(7)——可视化
# coding:utf-8 import numpy asnp import pandas aspd importmatplotlib.pyplot as plt#pip3 install matplotlib importseaborn as sns#pip3 install seaborn1 折线defbroken_line(): s = pd.Series(np.random.r...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
机器学习平台 PAI笔记相关内容
- 机器学习平台 PAI精炼笔记
- 机器学习平台 PAI吴恩达笔记
- 笔记机器学习平台 PAI
- 机器学习平台 PAI笔记支持向量机
- 机器学习平台 PAI笔记神经网络
- 机器学习平台 PAI笔记单变量
- 机器学习平台 PAI课程学习笔记gnns
- 机器学习平台 PAI冬季课程学习笔记
- 机器学习平台 PAI冬季课程学习笔记networks
- 机器学习平台 PAI冬季课程学习笔记knowledge
- cs224w机器学习平台 PAI冬季课程学习笔记graph
- 机器学习平台 PAI冬季笔记embeddings
- 机器学习平台 PAI笔记model
- 机器学习平台 PAI笔记learning
- 机器学习平台 PAI自学笔记
- 机器学习平台 PAI笔记逻辑回归
- machine learning笔记机器学习平台 PAI
- 机器学习平台 PAI深度学习笔记
- andrew ng机器学习平台 PAI课程笔记
- andrew ng机器学习平台 PAI笔记pca
- andrew机器学习平台 PAI笔记learning
机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI scikit-learn
- 机器学习平台 PAI python
- 机器学习平台 PAI代码
- 机器学习平台 PAI论文
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI实战
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI模型
- 机器学习平台 PAI构建
- 机器学习平台 PAIpai
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI数据
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI方法
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI分类
- 机器学习平台 PAI平台
- 机器学习平台 PAI学习
- 机器学习平台 PAI特征
- 机器学习平台 PAI实践
- 机器学习平台 PAI决策
- 机器学习平台 PAIai
- 机器学习平台 PAI部署
- 机器学习平台 PAI网络
- 机器学习平台 PAI线性回归