
机器学习测试笔记(26)——自动特征选择(下)
2基于模型特征选择(SelectFromModel)基于模型特征选择,使用sklearn.feature_selection.SelectFromModel类。我们用随机森林模型进行特征选择。from sklearn.feature_selection import SelectFromModel from sklearn.ensemble import RandomForestRegresso....

机器学习测试笔记(26)——自动特征选择(上)
自动特征选择包括:单一变量法(univariate)、基于模型特征选择(SelectFromModel)和迭代特征选择(RFE)。1单一变量法(univariate)我们从网易财经频道下载股票交易数据,通过下面代码进行处理。def dealdata(mydata): if str(mydata)[-1]=='%': try: return(float(str(mydata)[:-1])/100)....

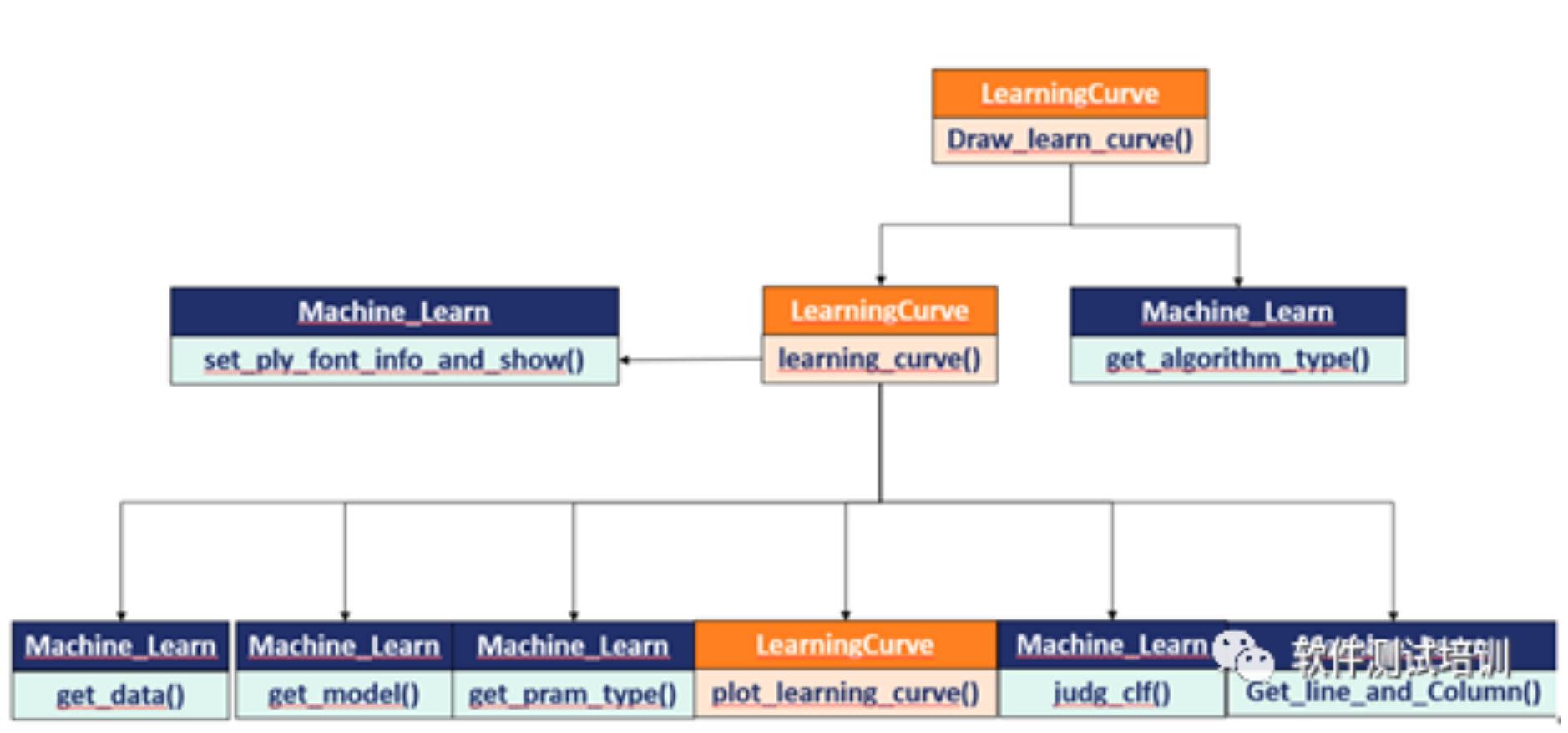
机器学习测试笔记(24)——综合_学习曲线
1 画学习曲线1.1函数和类调用图1.2 代码class LearningCurve: def__init__(self,data): self.data = data #定义一个绘制学习曲线的函数 defplot_learning_curve(self,estimator, title,X,y,ylim=None,cv=None,n_jobs=2,train_si...
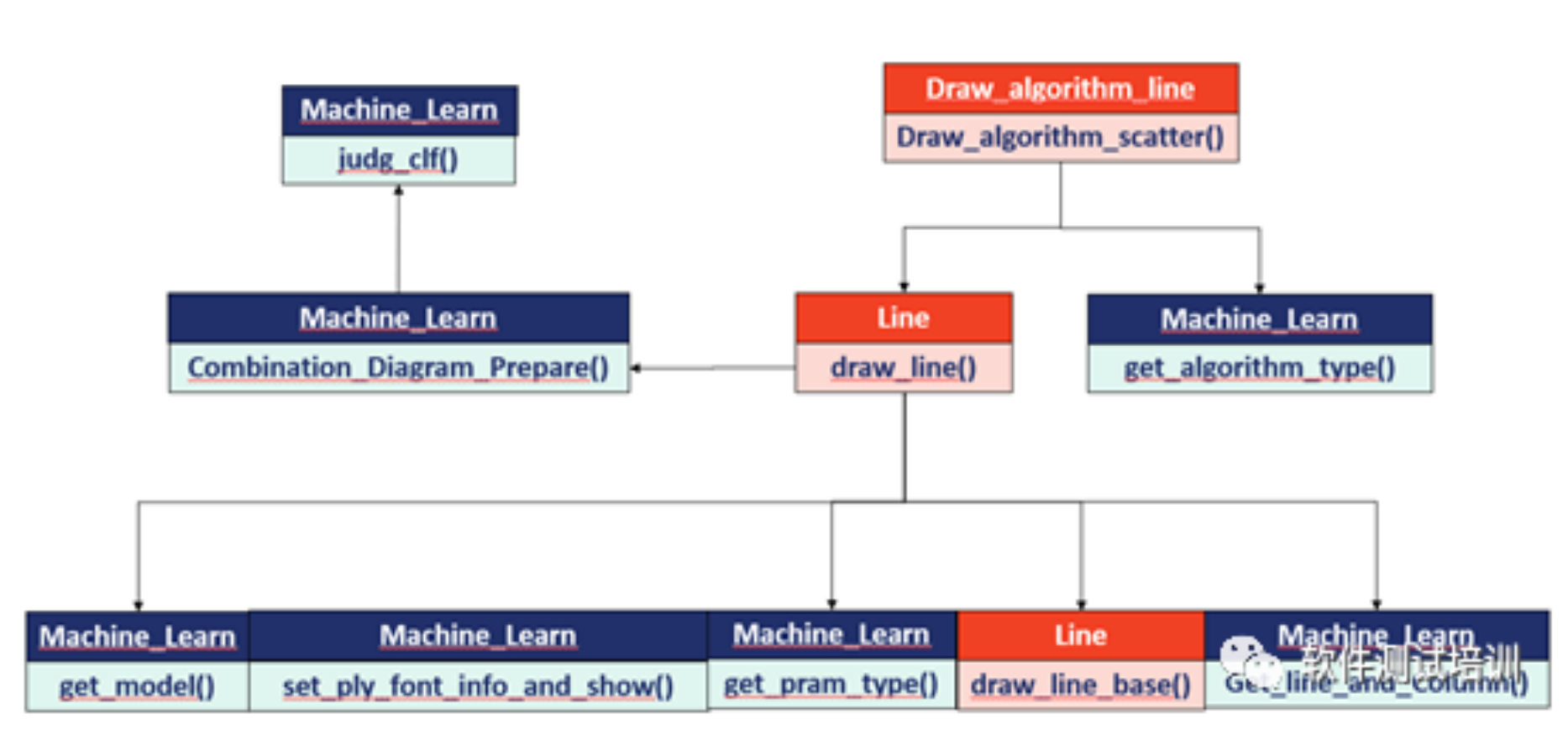
机器学习测试笔记(23)——综合_拟合线
1 画拟合线1.1函数和类调用图1.2 代码class Line: #画线 defdraw_line_base(self,X,y,clf): Z = np.linspace(-3,3,200).reshape(-1,1) plt.scatter(X,y,c='b',s=60) try: plt.plot(Z,clf.predict(Z),c='k') except Exception a...
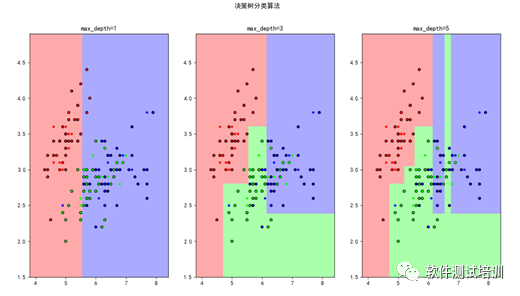
机器学习测试笔记(22)——综合_散点图(下)
4.3 决策树输出DecisionTreeClassifier 训练集得分(max_depth=1): 63.39% 测试集得分(max_depth=1):65.79% 训练集得分(max_depth=3): 86.61% 测试集得分(max_depth=3):71.05% 训练集得分(max_depth=5): 88.39% 测试集得分(max_depth=5):68.42%(过拟合) Dec....
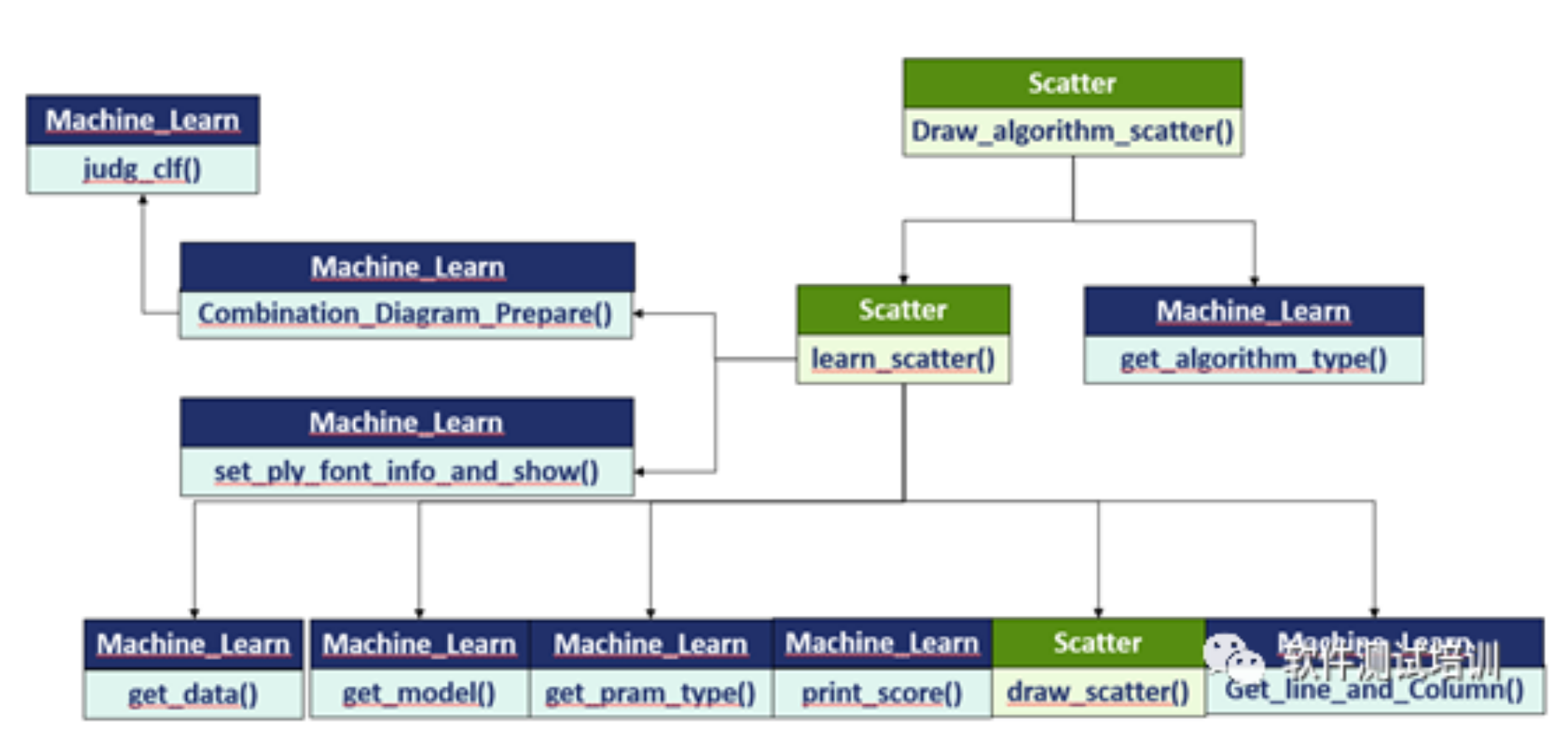
机器学习测试笔记(22)——综合_散点图(上)
1.引入算法头from sklearn import datasets from sklearn.pipeline import Pipeline from sklearn.svm importSVC,SVR,LinearSVC,LinearSVR from sklearn.tree import DecisionTreeClassifier,DecisionTreeRegressor from....
机器学习测试笔记(20)——集成学习
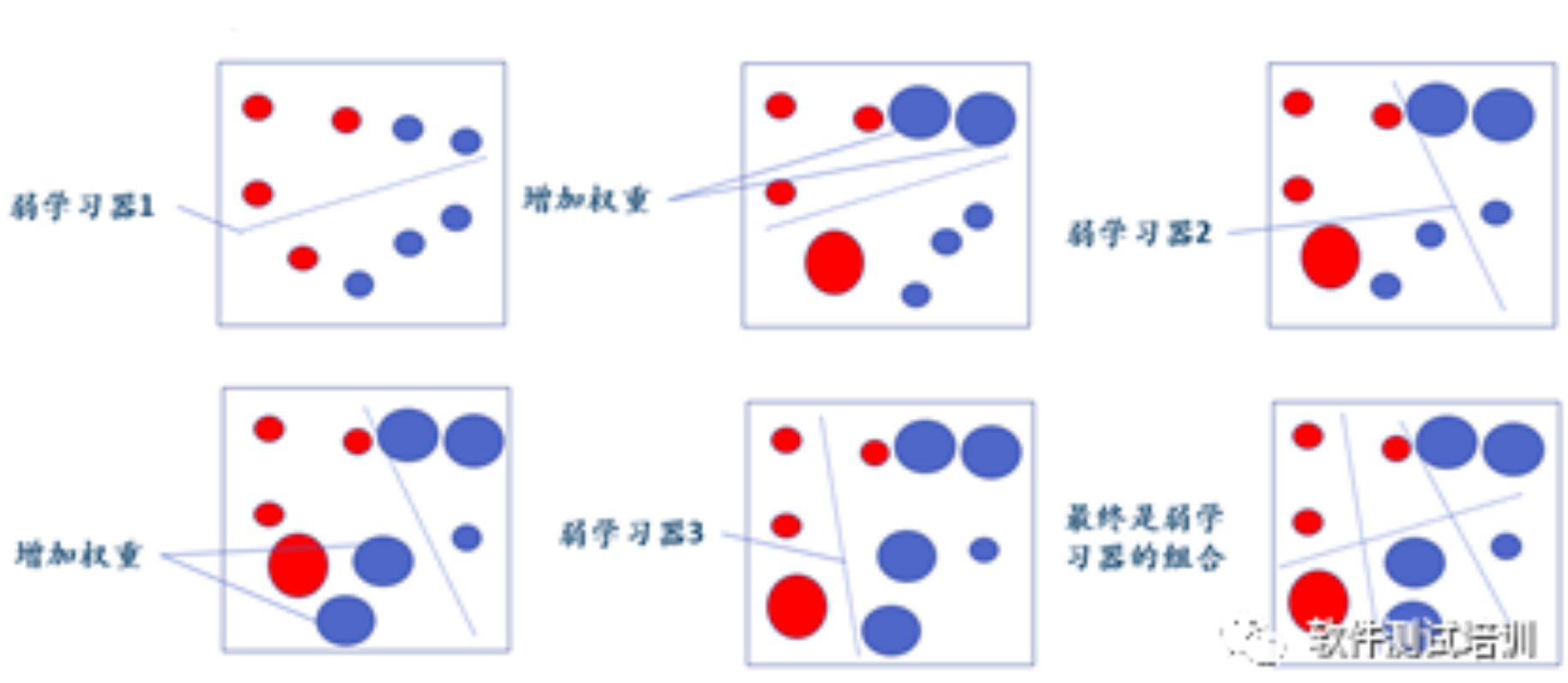
1.概念集成学习将多个训练的基础学习器进行结合,优化为更先进的学习器。集成学习模型的方式大致为以下几个:bagging、boosting、voting、stacking。它的特点是:初始化,对m个训练样本的数据集(不同颜色代表不同数据集),给每个样本分配初始权重(圆点越大,权重越大);使用带权重的数据集训练处一个弱学习器;对弱学习器训练的错误样本增加权重;新的带权重的数据集训练处下一个弱学习器;....
机器学习测试笔记(19)——聚类
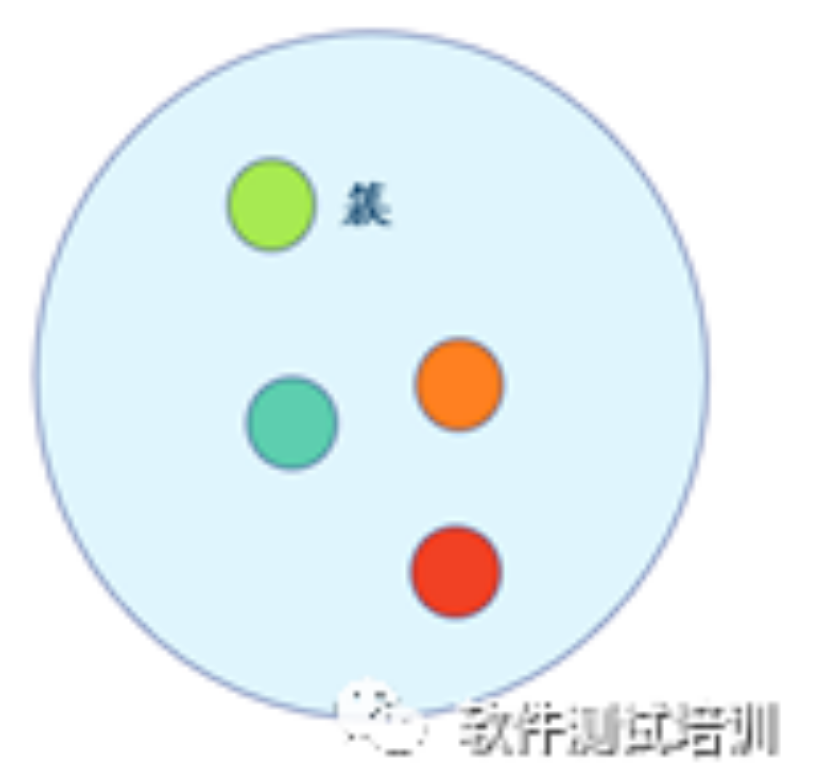
1.概念在有监督学习中分组叫做分类。它是有标签的,比如苹果可以分为:国光苹果、红香蕉苹果、阿克苏苹果…,而在无监督学习中分组叫做聚类,他是没有标签的,它把相同的元素分为一组。在聚类中,分类后的每一组叫做簇。 2.K均值聚类2.1 概念k均值聚类算法(k-means clustering....
机器学习测试笔记(18)——降维(下)
3.非负矩阵分解3.1 概念非负矩阵分解(Non-Negative Matrix Factorization : NMF)。矩阵分解:一个矩阵A分解为A=B1*B2*…*Bn。非负矩阵分解:矩阵分解,矩阵A、 B1…Bn中元素均为非负。3.2 代码通过fromsklearn.decomposition.NMF方法来实现。from sklearn.decomposition import NMF ....
机器学习测试笔记(18)——降维(上)
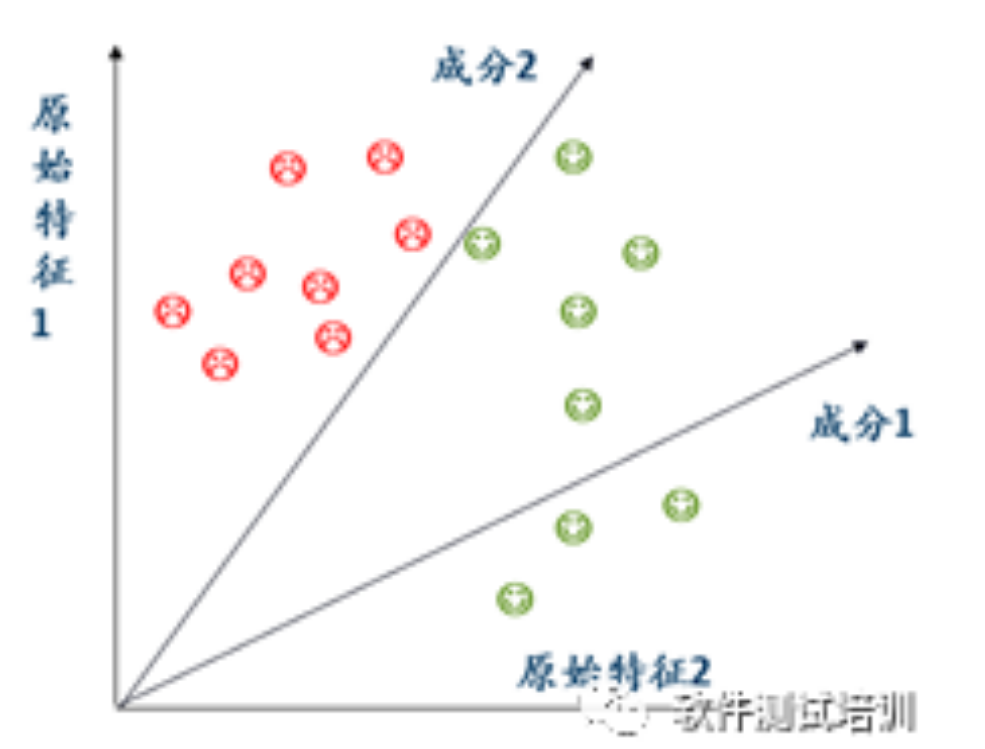
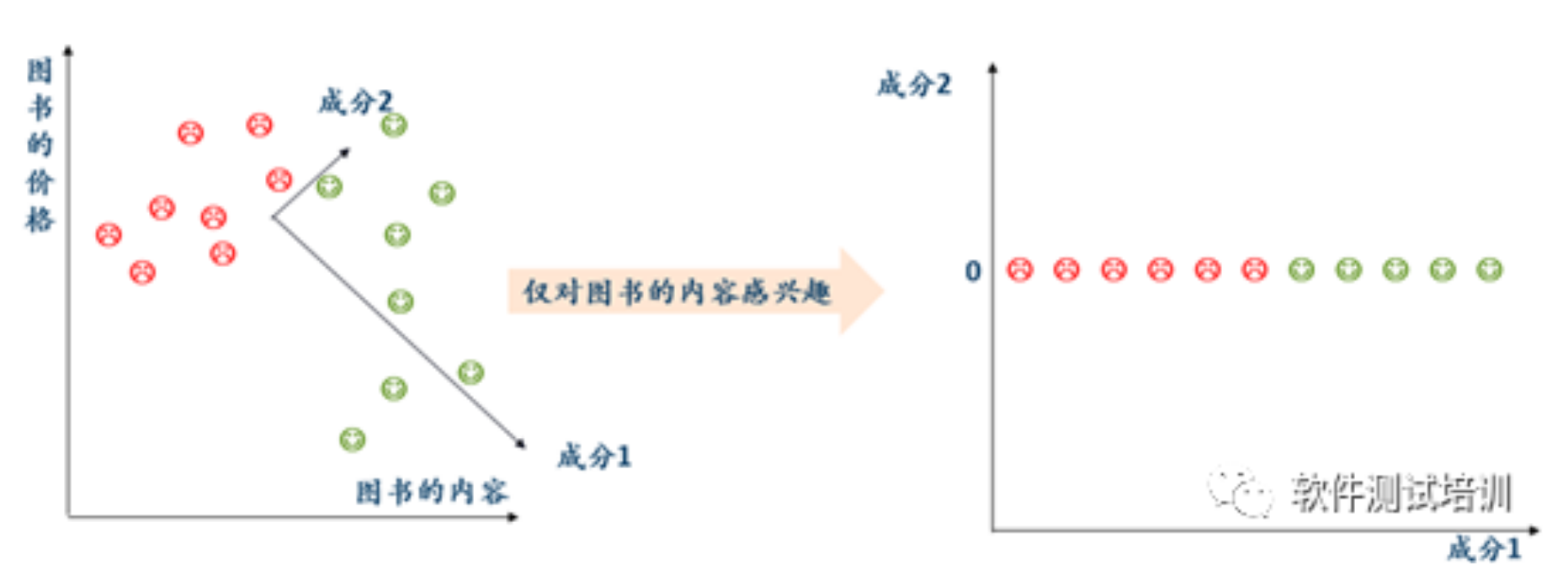
1.降维解决能问题降维解决能问题:缓解维度灾难问题;压缩数据的同时让信息损失最小化;理解低维度更容易。有些特征的意义不大,可以通过降维来解决2. 主生成分析2.1 概念主生成分析(Principal CpmponentAnalysis:PCA)。无监督线性降维,用于数据压缩、消除冗余和消除噪音。对图书价格关注程度不是很重要,可以通过成分1——成分2进行降维。映射到蓝色后方差最小。2.2数学意义X....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
机器学习平台 PAI笔记相关内容
- 机器学习平台 PAI精炼笔记
- 机器学习平台 PAI吴恩达笔记
- 笔记机器学习平台 PAI
- 机器学习平台 PAI笔记支持向量机
- 机器学习平台 PAI笔记神经网络
- 机器学习平台 PAI笔记单变量
- 机器学习平台 PAI课程学习笔记gnns
- 机器学习平台 PAI冬季课程学习笔记
- 机器学习平台 PAI冬季课程学习笔记networks
- 机器学习平台 PAI冬季课程学习笔记knowledge
- cs224w机器学习平台 PAI冬季课程学习笔记graph
- 机器学习平台 PAI冬季笔记embeddings
- 机器学习平台 PAI笔记model
- 机器学习平台 PAI笔记learning
- 机器学习平台 PAI自学笔记
- 机器学习平台 PAI笔记逻辑回归
- machine learning笔记机器学习平台 PAI
- 机器学习平台 PAI深度学习笔记
- andrew ng机器学习平台 PAI课程笔记
- andrew ng机器学习平台 PAI笔记pca
- andrew机器学习平台 PAI笔记learning
机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI scikit-learn
- 机器学习平台 PAI python
- 机器学习平台 PAI代码
- 机器学习平台 PAI论文
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI实战
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI模型
- 机器学习平台 PAI构建
- 机器学习平台 PAIpai
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI数据
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI方法
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI分类
- 机器学习平台 PAI平台
- 机器学习平台 PAI学习
- 机器学习平台 PAI特征
- 机器学习平台 PAI实践
- 机器学习平台 PAI决策
- 机器学习平台 PAIai
- 机器学习平台 PAI部署
- 机器学习平台 PAI网络
- 机器学习平台 PAI线性回归