
大数据-104 Spark Streaming Kafka Offset Scala实现Redis管理Offset并更新
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-103 Spark Streaming Kafka Offset管理详解 Scala自定义Offset
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-102 Spark Streaming Kafka ReceiveApproach DirectApproach 附带Producer、DStream代码案例
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

如何使用Spark通过ENI网络访问消息队列Kafka版
本文介绍如何使用云原生数据仓库 AnalyticDB MySQL 版Spark通过ENI网络访问消息队列Kafka版。
Spark Structured Streaming 和 Kafka 在数据完整性推理上有何不足?
Spark Structured Streaming 和 Kafka Streams 在数据完整性推理上有何不足?
195 Spark Streaming整合Kafka完成网站点击流实时统计
1.安装并配置zk2.安装并配置Kafka3.启动zk4.启动Kafka5.创建topicbin/kafka-topics.sh --create --zookeeper node1.itcast.cn:2181,node2.itcast.cn:2181 \ --replication-factor 3 --partitions 3 --topic urlcount6.编写Spark Strea....
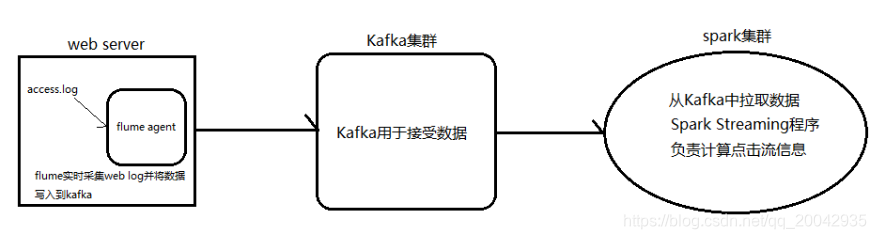
大数据Spark Structured Streaming集成 Kafka
1 Kafka 数据消费Apache Kafka 是目前最流行的一个分布式的实时流消息系统,给下游订阅消费系统提供了并行处理和可靠容错机制,现在大公司在流式数据的处理场景,Kafka基本是标配。StructuredStreaming很好的集成Kafka,可以从Kafka拉取消息,然后就可以把流数据看做一个DataFrame, 一张无限增长的大表,在这个大表上做查询,Structured Stre....
大数据Spark Streaming集成Kafka
1 整合Kafka 0.8.2在实际项目中,无论使用Storm还是SparkStreaming与Flink,主要从Kafka实时消费数据进行处理分析,流式数据实时处理技术架构大致如下:技术栈: Flume/SDK/Kafka Producer API -> KafKa —> SparkStreaming/Flink/Storm(Hadoop YARN) -> Redis -&am...
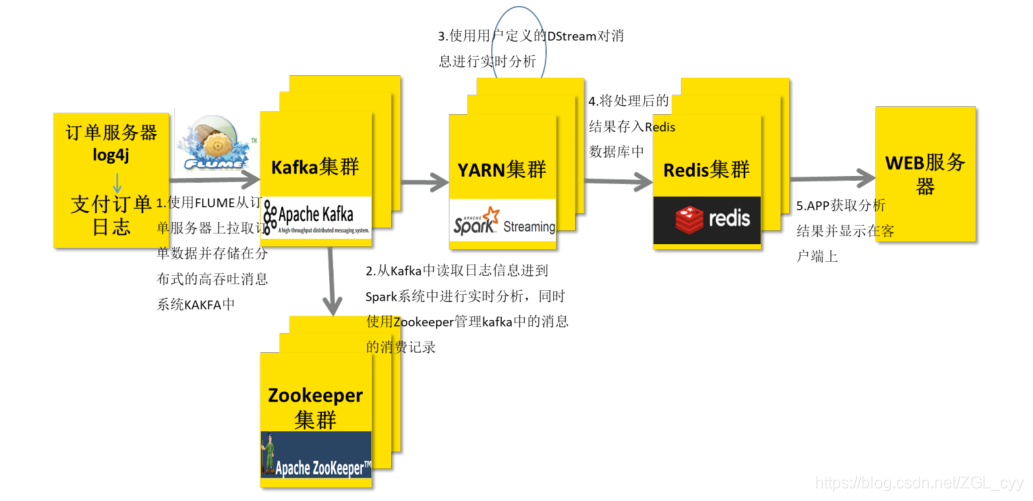
如何处理Kafka集群的数据_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
本文介绍如何在E-MapReduce的Hadoop集群运行Spark Streaming作业,处理Kafka集群的数据。
如何基于云HBase和Spark构建一体化的数据处理平台
云HBase X-Pack是基于Apache HBase、Phoenix、Spark深度扩展,融合Solr检索等技术,支持海量数据的一站式存储、检索与分析。融合云Kafka+云HBase X-Pack能够构建一体化的数据处理平台,支持风控、推荐、检索、画像、社交、物联网、时空、表单查询、离线数仓等场景,助力企业数据智能化。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云消息队列 Kafka 版spark相关内容
- spark云消息队列 Kafka 版scala
- spark streaming云消息队列 Kafka 版offset
- spark streaming云消息队列 Kafka 版scala
- 大数据spark云消息队列 Kafka 版
- spark云消息队列 Kafka 版
- spark云消息队列 Kafka 版自定义
- 云消息队列 Kafka 版spark streaming
- spark structured streaming云消息队列 Kafka 版
- spark streaming云消息队列 Kafka 版数据
- spark云消息队列 Kafka 版流数据
- spark集成云消息队列 Kafka 版
- spark云消息队列 Kafka 版direct
- spark云消息队列 Kafka 版服务
- spark云消息队列 Kafka 版stream
云消息队列 Kafka 版您可能感兴趣
- 云消息队列 Kafka 版应用
- 云消息队列 Kafka 版架构
- 云消息队列 Kafka 版场景
- 云消息队列 Kafka 版消费者
- 云消息队列 Kafka 版分配
- 云消息队列 Kafka 版分区
- 云消息队列 Kafka 版生产者
- 云消息队列 Kafka 版平台
- 云消息队列 Kafka 版分析
- 云消息队列 Kafka 版分布式
- 云消息队列 Kafka 版flink
- 云消息队列 Kafka 版数据
- 云消息队列 Kafka 版cdc
- 云消息队列 Kafka 版集群
- 云消息队列 Kafka 版报错
- 云消息队列 Kafka 版topic
- 云消息队列 Kafka 版配置
- 云消息队列 Kafka 版同步
- 云消息队列 Kafka 版消息队列
- 云消息队列 Kafka 版消费
- 云消息队列 Kafka 版mysql
- 云消息队列 Kafka 版apache
- 云消息队列 Kafka 版安装
- 云消息队列 Kafka 版消息
- 云消息队列 Kafka 版日志
- 云消息队列 Kafka 版sql
- 云消息队列 Kafka 版原理
- 云消息队列 Kafka 版连接
- 云消息队列 Kafka 版解析
- 云消息队列 Kafka 版java

